


本文转载于公众号 读芯术,原文地址
在上一节(如何理解RNN?(理论篇))的课程我们介绍了循环神经网络的基本结构,同时这样的循环结构也会给优化带来一定的困难,本文主要介绍两种较为简单的方式来缓解RNN的优化问题:
- 正交初始化
- 激活函数的选择
BPTT的两个关键点

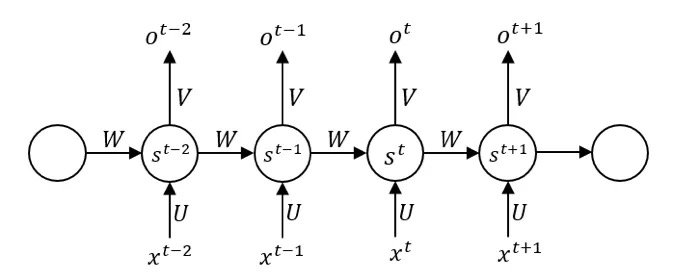
我们可以上图写出前向传播的公式,使用f作为隐藏单元的激活函数,g作为输出单元的激活函数,为了简化问题,不使用偏置,也不在单元中使用阈值,一个圆圈只代表一个神经元,以St为例:

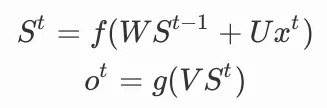
其中:

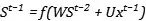
在反向传播时,我们就不能采取原来逐层反向传播的方法去更新参数,因为数据在使用时有着不同的进入顺序,同时每个时间步共享参数,我们对单独时间步的更新需要考虑整个序列上的信息。我们称这样的方式为沿时间的反向传播(BP through time),但真正本质的机制只有两个,参数共享和循环结构。
要理解这一点并不难,我们只需要考虑矩阵乘法,参数未被共享的情况下,从形式上来看,矩阵参数更新之间互不干扰,我们可以很方便对每个参数进行更新,但如果参数共享,那么矩阵的元素需要绑定在一起更新,梯度的更新变为了参数共享的区域梯度之和。因为参数共享的区域是沿着时间共享,所以求和也需要按照时间。(在同样具备参数共享的CNN的反向传播中,求和是按照空间)
我们对参数V的更新,就要考虑不同时间步上的参数共享,我们可以把前向传播写成矩阵的形式:

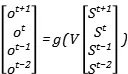
就有:

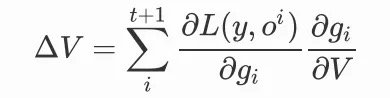
在此基础上,我们对于参数U进行同样的前向传播操作:

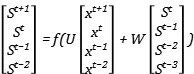
我们会发现,当前时间步的变量St会包含前一步的变量St-1,此时我们选择对U或者W求梯度,就不能忽略掉前一步的变量,因为前一步的变量中也包含了参数U和W,那么我们在对U进行更新时,就需要将前面的时间步递归展开:

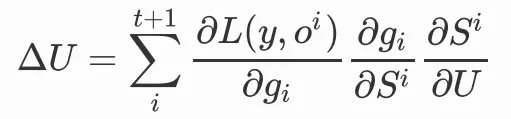
因为:

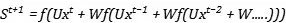

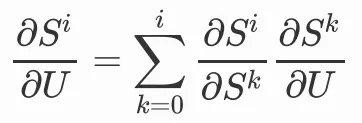
同理,我们对W做参数更新,也是同样的结构:

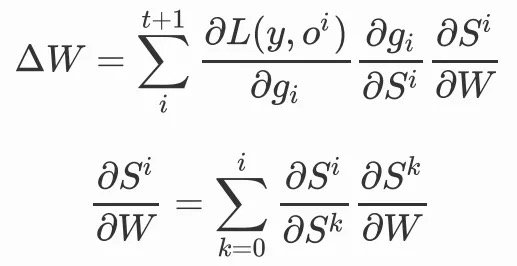
我们可以清晰的看到,权重共享机制使得我们需要对每个时间步梯度求和,循环结构使得我们需要递归地处理梯度,根据我们的展开式,每一个

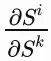
都会产生一个或多个W,比如:

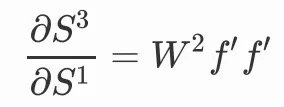
当我们链的越来越长的时候,整条链出现了W的连乘,这正是循环结构带来的。
在普通的神经网络中,梯度消失往往来源于激活函数和层与层协调更新,但在RNN中,梯度消失和爆炸的来源之一就是共享参数W的连乘。在RNN中,循环层如果没有梯度的流动,那么就表示序列的信息并没有传达到下去,我们所谓的记忆单元就会丧失记忆能力,RNN相比传统n-gram模型的优势也就不复存在。
从理论上来说,我们希望尽可能保持W值保持在一定范围内,使得网络可以被有效的训练。
正交初始化
正交初始化的思路很简单,就是利用了正交矩阵的性质,它的转置矩阵就是它的逆矩阵,有:

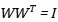
使得矩阵的连乘不会放大或者缩小W本身的值。
我们也可以从另外一个角度来理解,如果我们对矩阵做特征值分解,分解为对角矩阵和正交矩阵的乘积:

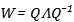
矩阵的连乘就会变成:

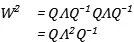
矩阵的连乘就会变为其特征值的连乘,所以:
• 如果特征值的绝对值都小于1,那么参数梯度会越变越小。
• 如果特征值近似都等于1,那么参数梯度就可以保持正常范围。
• 如果特征值的绝对值都大于1,那么参数梯度会越来越大。
正交矩阵的特征值要么是1、要么是-1,虽然我们无法保证参数矩阵W永远都是这样的形式,但至少可以在初始化上做到这一点。
激活函数
我们很早就曾讲过激活函数的重要性,sigmoid函数具有非中心化和广泛的饱和性,ReLU以及它的各种变体可以很好的解决这个问题,但是在循环神经网络中,我们需要考虑参数的特征值,ReLU在其右端是一个线性函数,虽然它的梯度恒定为1,但函数值却可以无限的增长。
传统的ReLU在RNN中则可能会带来梯度爆炸的问题,但解决梯度爆炸我们一般会采用截断(clipping)的方式,也就是如果梯度大于某值,就令其等于某值。另外,我们还可以在采用tanh激活函数,因为它的范围在[-1,1],更好的适应参数连乘带来的梯度爆炸,却也在一定程度上无法避免梯度消失。
我们需要在这两者之间做trade-off,因为我们既不想让激活函数对权重求导的部分变得太大或者太小,也不希望函数本身的值变得太大或者太小。