


在Dialexa,我们与企业和初创公司合作,从头开始设计,构建和部署成功的数据驱动产品。数据驱动型产品的核心是基于智能引擎,该引擎利用数据自动执行决策。
举例来说,这是一个竞标在线广告展示位置的平台。这是一个平台,需要以他们想要显示的广告,一些可选的硬出价限制和可配置的侵略性因素的形式进行一些人工输入。系统本身可以由机器学习代理驱动,该代理可以进行出价,监控广告的点击率,并可能对自身进行在线调整以优化出价模式。
以产品为中心的数据科学和机器学习带来了一系列全新的挑战,典型的数据科学项目并未受到限制。在以产品为中心的项目中,数据科学家与设计师,软件工程师和产品所有者的多学科团队合作,确保他们的模型与业务目标保持一致,在系统的约束下创建,并在敏捷的时间框架内交付。
多年来,我们已经看到了多个项目的一些常见情景,并积累了一些关于如何降低风险,快速交付价值以及为未来制定可靠计划的技术。
以下是那些希望构建数据驱动产品的人的一些建议。
尽早获取和分析数据
成功的机器学习和数据科学产品依靠数据生存和消亡。在Kaggle比赛和一些学术研究领域,数据清晰,可访问,值得信赖,并且足够丰富,可以训练模型。然而,工业数据科学数据通常是无格式的,嘈杂的,并且受到严格管理。
我们面临的最大挑战之一就是削减繁文缛节,以便掌握正确的数据集。企业在他们的仓库中闲置着数据宝库,但在您的团队和数据之间有多个部门(法律,IT,治理),他们需要批准转移,购买访问权限的潜在谈判过程以及团队数据工程师在数据传输到您的团队之前完成数据合同。
如果不能访问这些数据,数据科学家只能推测他们可以用它做什么。无法正确地假设此数据已准备好进行建模,甚至无法获得达到目标KPI所需的信号。尽早获取数据可让团队在深入了解可能不可行的建模路径之前返回快速反馈。
我们建议使用简短的“价值证明”阶段启动每个数据驱动的产品。这是一个小团队完成获取所需数据的基础,使用初始幼稚模型建立基线,并根据该模型设置可达到的模型KPI。这是一种低风险的方法,可以通过少量资源来验证您正在解决的问题。
理解最终用户
当您构建产品时,您实际上正在构建一个工具来解决最终用户利用的问题。用户以多种方式工作并与产品交互。数据驱动的产品将重点放在从模型接收建议的过程中,并提供模型反馈以供学习。要构建成功的数据驱动产品,首先要了解您的用户计划如何与您的产品进行交互,他们希望从模型中看到什么,他们对输出有什么控制,以及他们如何向系统提供反馈,这一点至关重要。
Web应用程序空间通过大量整合研究阶段,完善了成功产品的设计流程。此阶段通常包括构建角色,通过移情映射和进行用户访谈来了解用户和机器。此阶段的输出是产品所有者可以信赖的界面设计,以及工程师(和数据科学家!)团队可以执行的界面。
在Dialexa,我们成功地将以数据为中心的提示和问题注入到这些工具中,以深入了解用户实际需要的模型。这些新的数据点为数据科学家提供了指标,模型架构的要求,以及他们可能从未考虑过的许多新功能!

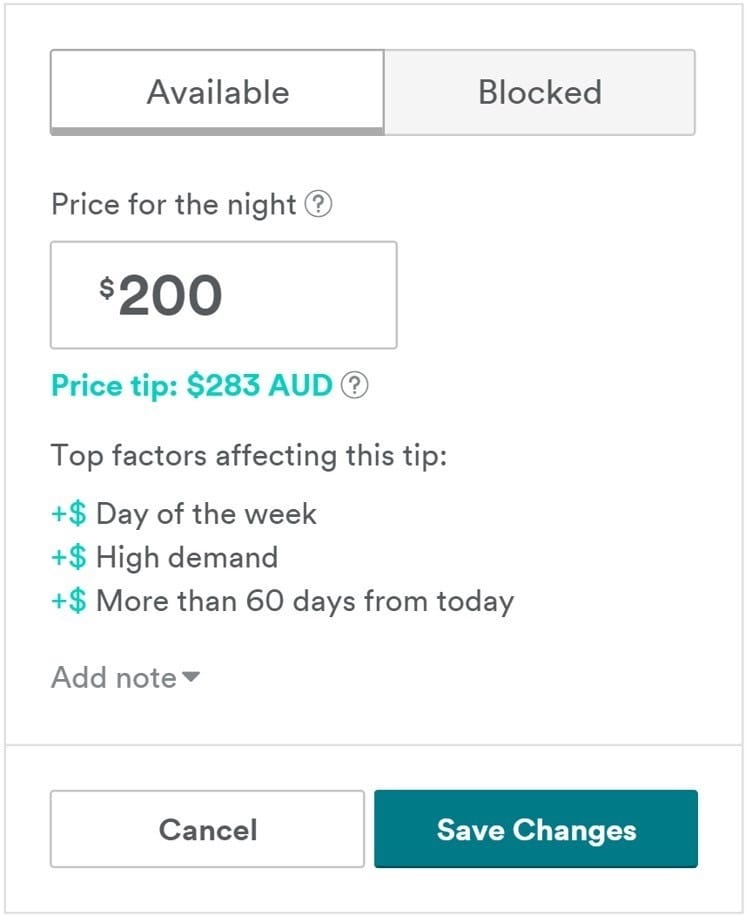
产品智能功能的一个很好的例子是AirBnB的上市价格建议。可以在研究阶段发现的这个功能的一些重要内容是:
- 这只是一个建议,让用户控制最终价格
- 他们给出了选择价格的主要因素
- 它们允许用户直接反馈他们的定价模型
这个功能并不完美,并且因其他投诉中的定价清单而受到批评。可以通过再次理解用户的顾虑来解决这些问题。我相信根据反馈,这个功能有很多方面需要改进。获得用户信任的一种方法是投资一个模型,该模型在决策中输出置信区间。他们可能不得不牺牲一些准确性,但是,只要它仍然可以接受准确,最终用户可能会对整个功能感到更满意。
理解你的模型
就像最终用户一样,模特也需要爱。这些模型不是独立的 – 整个团队必须在同一页面上,以便工程师可以编写支持软件,设计人员可以使用线框UI,利益相关者可以设置他们的交付期望。在建立模型或基于模型的功能之前,通过收集需求来让整个团队在同一页面上是至关重要的。


我们采用的方法之一来自我们的研究和设计团队。我们已经调整了用户移情地图以同情基于模型的功能。这是一篇很好的文章,深入描述了这个过程。练习的要点是让团队思考该功能,并记下以下内容:
- 感官 – 模型需要哪些数据和变量?
- 是 – 模型输出和采取的操作是什么?
- 说 – 用户如何知道模型做出决定的原因?
- 想一想 – 该功能必须遵循哪些硬性规则?
- 感觉 – 我们如何知道该功能正在做我们期望的事情?
这些是我们对我们团队运作良好的类别的解释。像“说”和“感觉”这样的类别可能特别难以包围。我们通过提供类似功能的示例,让团队开始思考正确的方向。例如,AirBnB价格建议工具的一些便签可能是:
感官
- 租用单位的位置数据
- 上市日期
是否
- 建议价格
- 一系列优惠的价格
说
- 该地区的类似房源
- 定价因素细分
想
- 不能低于最低收支平衡价格
- 有法律方面的考虑吗?
感觉
- 来自该工具的直接用户反馈
- 用户是否在此范围内?
此会话的输出是对此功能的所有玩家的共同理解和一系列明确要求。在高层次上,数据科学家可以开始设计模型架构,工程师可以为新数据源和API端点规划工作,设计人员可以对组件进行线框化,产品所有者确切知道将要交付的内容。多么令人难以置信的运动!
从简单开始,扩展复杂性
在产品团队中,数据科学家的工作很多时候都是其他团队成员工作的依赖。后端工程师无法有效地开发和测试软件以支持他们的模型,直到他们可以访问它。除此之外,产品所有者可能希望尽快推出用于beta测试的功能,而不是团队可以优化模型。
在这种情况下采取的第一个也是最重要的行动是与您的团队沟通。记录预期的输入和输出,以便解决模型何时准备就绪的问题。这应该在模型移情地图之后以高级别刷新!下一个要考虑的选择是不使用机器学习模型或大幅简化方法。
对于经验丰富的机器学习工程师来说,应对产品团队最困难的现实之一是机器学习是达到目的的手段,而不是目的本身。作为一名机器学习工程师,他喜欢阅读和了解该领域前沿的进展 – 我很难写出这一点。但实际上,大多数功能都是通过简单的模型甚至是启发式成功支持的 – 您不需要深入学习来解决每个问题。
快速部署一个简单的模型,或者至少是模型的界面,可以解除团队其他人的阻碍,让他们的齿轮转动。工程师可以放心地从该模型开始快速开发,利益相关者可以监控产品中模型的KPI,并在可接受时打开完整功能。
再举一次AirBnB价格建议模型。在定义完整功能之后,团队可以使用周围区域的平均列表价格来构建和部署快速启发式引擎。工程师可以开发出基于启发式的模型并将其隐藏在功能标志后面,等待在生产中打开。同时,数据科学团队,中小企业和产品所有者可以一起工作以迭代模型,直到它准备就绪,然后将其发布给最终用户。
这是一个为我们创造奇迹的过程。我们已经能够快速迭代越来越多的高级模型,在类似生产的环境中测试模型,并以完全安全的方式发布模型驱动的功能。
最后的想法
这些只是我们团队为提供数据驱动产品而采用的众多技术和流程中的一小部分。在我们渴望分享和帮助其他产品团队实施的过程中,我们吸取了更多的经验教训。回到餐巾纸上
本文转自medium,原文地址