


有没有想过我们如何将机器学习算法应用于问题,以便分析,可视化,发现趋势并找到数据中的相关性?在本文中,我将讨论建立机器学习模型的常见步骤以及为数据选择正确模型的方法。本文的灵感来自于常见的访谈问题,这些问题被问及如何处理数据科学问题以及为什么选择上述模型。
作为数据科学家,我们遵循一些准则来创建模型:
- 收集数据(通常为数吨)
- 建立目标,要检验的假设和完成此任务的时间表
- 检查异常或异常值
- 探索丢失的数据
- 根据我们的约束,目标和假设检验清理数据
- 执行统计分析和初始可视化
- 缩放,正则化,归一化,特征工程师,随机样本并验证我们的数据以进行模型准备
- 训练和测试我们的数据,并使用我们对数据的验证部分来扮演未知的角色
- 基于分类/回归指标构建模型,用于有监督或无监督学习
- 建立基准精度并根据训练或测试数据检查我们当前模型的精度
- 仔细检查我们是否已解决问题并提供结果
- 准备好用于部署和产品交付的模型(AWS,Docker,Buckets,App,网站,软件,Flask等)
机器学习任务可以分为监督学习,非监督学习,半监督学习和强化学习。在本文中,我们不关注最后两个,但是,我将对它们的含义有所了解。
半监督学习使用未标记的数据来总体上进一步了解人口结构。换句话说,我们只从一个小的训练集中学习特征,因为它被标记了!我们不会利用包含大量有价值信息的测试集,因为这些信息是未标记的。因此,我们应该找到一种从大量未标记数据中学习的方法。
根据GeeksForGeeks的说法,强化学习是关于在特定情况下采取适当的行动以最大化回报的方法。机器或机器人通过尝试所有可能的路径,然后选择能够以最少的障碍获得最佳回报的路径来进行学习。
方法
以下是为机器学习/深度学习任务选择模型的一些方法:
- 数据不平衡相对普遍。
我们可以通过对数据进行重新采样来处理不平衡数据,这是一种使用数据样本来提高准确性并量化总体参数不确定性的方法。记住我们喜欢重新采样。实际上,重采样方法利用了嵌套的重采样技术。
我们将原始数据分为训练和测试集。在训练集的帮助下找到适合我们模型的系数之后,我们可以将该模型应用于测试集并找到所述模型的准确性。这是将其应用于未知数据(也称为我们的验证集)之前的最终准确性。这种最终的准确性使人们更有希望在未知数据上获得准确的结果。
但是,如果我们将训练集进一步划分为训练和测试子集,然后计算该子集的最终准确性,那么对这些子集中的许多子集重复执行此操作,便可以使我们在这些子集中获得最大的准确性!我们希望该模型可以为我们的最终测试集提供最大的准确性。进行重新采样以提高模型的准确性。有不同的数据重新采样方式,例如自举,交叉验证,重复交叉验证等。
2.我们可以通过主成分分析来创建新功能
也称为PCA,有助于降低尺寸。聚类技术在无监督机器学习技术中非常普遍。
3.通过正则化技术,我们可以防止过度拟合,拟合不足,离群值和噪声。
4.我们需要解决黑匣子人工智能问题
这使我们考虑了构建可解释模型的策略。根据KDNuggets的说法,用于自动决策的黑匣子AI系统通常基于对大数据的机器学习,将用户的特征映射到一类可以预测个人行为特征的类中,而没有揭示其原因。
这不仅是缺乏透明度的问题,而且是算法从人类偏见和训练数据中隐藏的伪像集合中继承的可能偏差的问题,这可能导致不公平,错误的决定和错误的分析。
5.了解对异常值不敏感的算法
我们可以决定我们应该在模型中使用随机性,还是在随机森林中克服异常偏斜度。
机器学习模型
我的数据科学家学习指南涵盖了大多数这些模型。该指南很好地定义了每种模型的用途,用途,使用时间以及简单的口头示例。如果您想访问我的指南,请单击此处,因为它也是在Medium的“迈向数据科学”上发布并推荐的。
- 预测连续值的第一种方法:线性回归通常是首选,也是最常见的选择,例如房价
- 二元分类方法通常类似于逻辑回归模型。如果您遇到两类分类问题,则支持向量机(SVM)非常有助于获得最佳结果!
- 多类别分类:随机森林受到高度青睐,但SVM却有优势。随机森林更适合多类!

对于多类,您需要将数据简化为多个二进制分类问题。即使要素的比例不同,随机森林也可以很好地结合使用数字和分类要素,这意味着您可以按原样使用数据。SVM可以最大化余量,并依赖于不同点之间的距离概念。由距离决定是否真的很重要!
由于这种情况,我们必须对分类特征进行一次热编码(虚拟)。此外,强烈建议使用最小-最大或其他缩放比例作为预处理步骤。对于大多数常见的分类问题,随机森林提供了属于该类别的可能性,而SVM提供了您与边界的距离。如果需要概率,您仍然需要以某种方式将其转换为概率。对于支持SVM的那些问题,它将胜过随机森林模型。SVM为您提供支持向量,即每个类中最接近类之间边界的点。
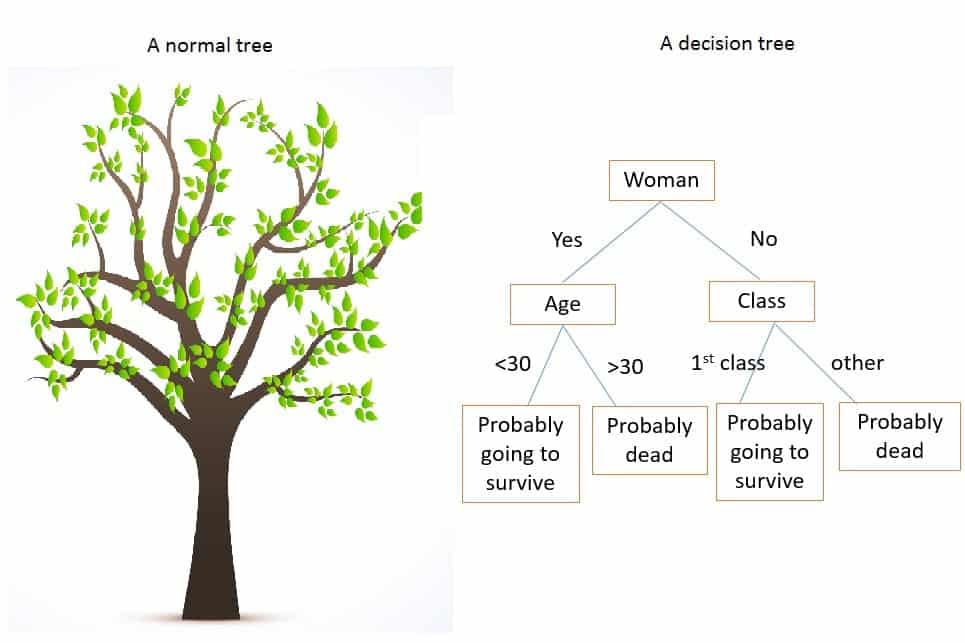
4.最简单的分类模型开始于?决策树被视为最容易使用和理解的树。它们是通过诸如随机森林或渐变增强之类的模型实现的。

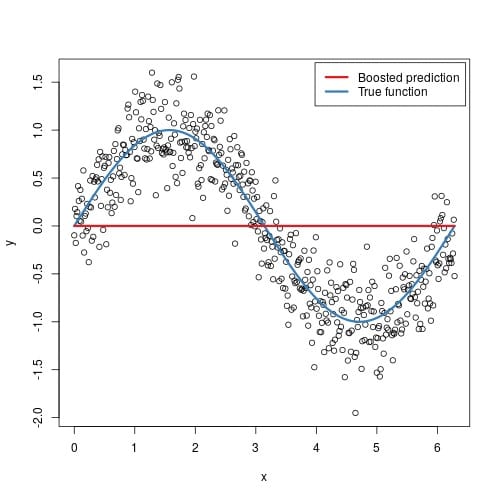
5.竞争青睐的车型?Kaggle比赛偏爱随机森林和XGBoost!什么是梯度增强树?

深度学习模型
根据Investopedia的说法,深度学习是一种人工智能功能,它模仿人脑在处理数据和创建用于决策的模式方面的工作。


- 我们可以使用多层感知器来专注于复杂的功能,这些功能不容易指定,但是具有大量标记数据!
根据Techopedia的说法,多层感知器(MLP)是一种前馈人工神经网络,可以从一组输入生成一组输出。MLP的特点是输入节点和输出层之间有向连接的几层输入节点,作为有向图。

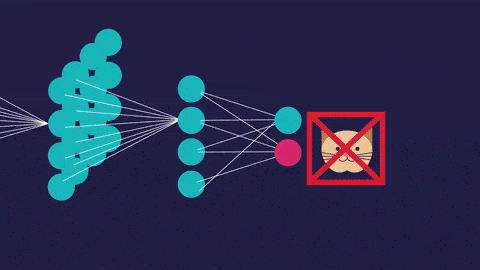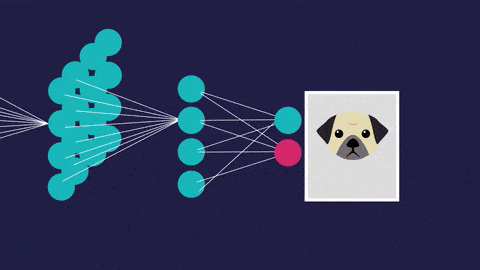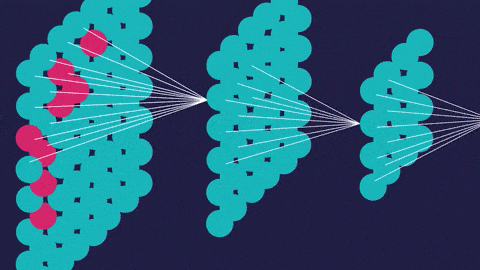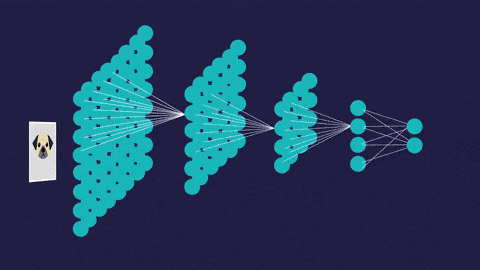
2.对于基于视觉的机器学习,例如图像分类,目标检测,图像分割或图像识别,我们将使用卷积神经网络。CNN用于专门用于处理像素数据的图像识别和处理。


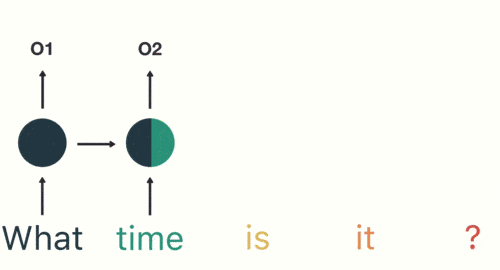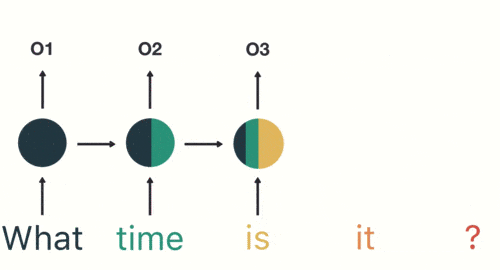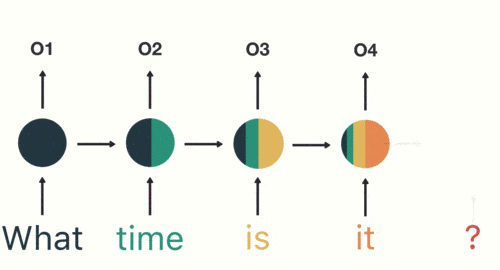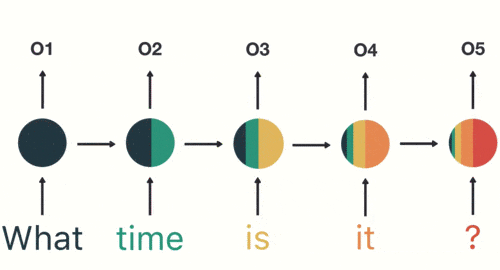
3.对于诸如语言翻译或文本分类之类的序列建模任务,经常使用递归神经网络。
当任何模型需要上下文以能够基于输入提供输出时,RNN就会出现。有时,上下文是模型预测最适当输出的最重要的事情。在其他神经网络中,所有输入都是彼此独立的。

感谢您抽出宝贵的时间阅读我的文章。在我的面试过程中,我一直在质疑解决数据科学问题和选择正确的机器学习模型的方法。不是说错了,而是为什么我选择了这个特定的方向。实际上,对于您的方法,确实没有正确的答案,但是选择正确的模型具有某种正确性。最终,这取决于您正在分析的数据以及您要解决的目标!
本文转自 medium,原文地址