


本文转载自公众号 将门创投,原文地址
人工智能的能力我们已经耳熟能详,但它的弱点是什么、它的局限是什么才是我们需要关注的重点。例如,无人驾驶汽车在真实路况中会遇到很多在训练中从未见过的场景,如何处理这种实际与训练不匹配的特殊情形成为了横在研究人员面前的一大难题。
近日,MIT和微软的研究人员开发出一种用于识别智能系统的新模型,特别是自动驾驶系统在训练中学习到的、但是与实际情形不匹配的知识“盲点”,工程师们可利用这一模型识别并改进自动驾驶系统处理特殊情况的措施,提高整个系统的安全性。


无人驾驶汽车的人工智能系统在虚拟仿真环境和数据集中接受了广泛的训练,以便应对道路上可能发生的每一种状况。但是有时候汽车在现实世界中会犯下意想不到的错误,因为对于有些突发事件,汽车应该但却没有做出正确的应对。


如果有一辆未经特殊训练的无人车,在通常的数据集上进行训练后可能无法区分白色的箱式小货车和闪着警报呼啸而至的救护车。当它在公路上行驶时救护车鸣笛经过,由于它无法识别出救护车这个特殊的训练集中缺乏的车型(训练集中一般会标注小货车),它无法知晓此时需要减速和靠边礼让,而这样的无人车在路上行驶时就带来一系列无法预知的交通状况。同样的情形还会出现在与警车、消防车甚至校车同行的路段中。特备对于外卖快递飞驰的电动车、忽左忽右的自行车、随处冲出的行人,无人驾驶系统更是无法处理如此复杂的路况!
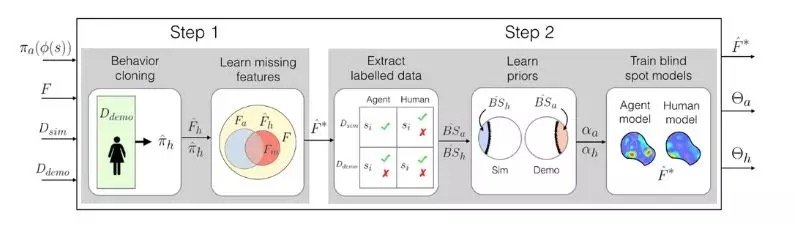
为了解决这一问题,研究人员提出了新的训练手段来对无人系统进行更深入的训练和改进。首先研究人员利用先前的方法通过模拟训练建立了人工智能系统。但当系统在现实世界中运行时,会有人密切监视该系统的行为,当系统犯下或将要犯下任何错误时,人类会及时介入为系统提供人类的反馈意见。随后研究人员将训练数据和人类反馈数据结合起来,并使用机器学习技术来生成异常/盲点识别模型,该模型能够准确地指出该系统在哪些地方需要人类介入以便获取更多的信息,从而来引导正确行为。
研究人员通过视频游戏验证了这种方法,他们通过模拟让人类纠正了视频中人物的学习路径。下一步是将该模型与传统的训练和测试方法结合起来,以便训练那些需要人类反馈意见的自动学习系统,比如自动驾驶汽车和机器人。这个模型有助于自动系统更好地了解它们不知道的东西,很多时候对系统进行训练时,它们接受的模拟训练与现实世界发生的事件并不相符,而且系统可能犯错,发生意外事故。这个模型可以用安全的方式以人类行为来弥补模拟和现实世界之间的差距。
一些传统的训练方法确实在真实世界的测试中提供了人类反馈,但是仅仅是为了更新系统的行为动作。这些方法不能识别人工智能系统的盲点。 而这种新提出的模型首先将人工智能系统置于模拟训练中,人工智能系统将产生一些“策略”,将每种情况都映射到它在模拟中能采取的最佳行动。然后该系统将被设置到现实世界中,当系统行为错误时人类将发出提醒信号。
人类可以通过多种方式提供数据,例如通过“演示”和“修正”。在演示中,人类像在现实世界中那样行动,系统对其进行观察,并将人类的行为和在这种情况下系统将采取的行为进行比较。以无人驾驶汽车为例,如果汽车的计划路线偏离了人类的意愿,人类会手动控制汽车,这时系统就会发出信号。通过观察人类行为相符或不相符的行为,为系统指出了哪些行为是可接受的,哪些行为是不可接受的。
同时人类还可以对系统进行修正,当系统在现实世界中工作时,人类可以对其进行监控。司机可以坐在驾驶座上,而自动驾驶汽车则沿着计划的路线行驶。如果汽车的行驶是正确的,人类不进行干预。如果汽车的行驶不正确,人类可能会重新控制车辆,这时系统就会发出信号,表明在这种特定情况下汽车采取了不当的行为。
一旦汇集了来自人类的反馈数据,系统就能构建出一个各类情况数据库。单个情况可以接收许多不同的信号,也就是说每种状况可能有多个标签表示该行为是可接受的和不可接受的。例如,一辆自动驾驶汽车可能已经在一辆大车旁边开过了许多次而且没有减速和停车,这是被认可的。但是某次对系统来说和大车完全一样的救护车驶来时,自动驾驶汽车也没有减速或者做出规避动作,此时它就会收到一个反馈信号:系统的行为不恰当。
此刻,该系统已经从人类那里得到了多个相互矛盾的信号:有时它从大车旁边不减速开过去,是可以的;而在相同情况下,只是大车换成了救护车,不减速开过去就不对。这时系统就会注意到它错了,但是它还不知道为什么错,在收集了所有这些看起来相互矛盾的信号后,下一步就是整合信息并提出问题:当收到这些混合信号时,犯下错误的可能性有多大。

这一新模型的最终目标是将这些模棱两可的情况标记为盲点。但这不仅仅是简单地计算每种情况下出现的可接受行为和不可接受行为的次数。例如如果该系统遇到救护车时十次中有九次采取正确的行动,就会将这种情况标记为非盲点。但由于不恰当行为远比恰当行为出现的次数少,系统最终会学会预测所有的情况都不是盲点,这对于实际系统来说是极其危险的。
为此研究人员使用一种通常用于众包数据处理标签噪声的Dawid – Skene机器学习方法来解决这一问题。该算法将各类情况汇总数据库作为输入,每个情况都有“可接受”和“不可接受”的一对噪音标签。然后它聚集所有数据,并使用一些概率计算方法来识别预测盲点标签模式和预测非盲点标签模式。使用这些信息它会为每种情况输出一个整合的“非盲点”或“盲点”标签以及该标签的置信度。值得注意的是,即使在90%的情况下做出了可接受行为,该算法也可以通过学习把罕见的不可接受情况认作盲点。最后该算法将生成了“热图”,系统在原始训练中经历的每种训练情况都被按照从低到高的盲点概率进行排布。
当系统被应用到现实世界中时,它可以利用该学习模型来更加谨慎和智能地行动。如果学习模型预测某种状态是高概率的盲点,系统就可以咨询人类应该如何应对,从而更安全的行动。
如果想要了解更详细的技术细节,请参考研究人员发表在最近AAAI -19的论文: