


最近我们一直在看电脑玩人类游戏,无论是多人游戏机器人还是Dota2,PUB-G,Mario等一对一游戏中的对手。当他们的AlphaGo计划在2016年击败韩国围棋世界冠军时,Deepmind(一家研究公司)创造了历史。如果你是一个激烈的游戏玩家,可能你一定听过Dota 2 OpenAI Five比赛,其中机器对抗人类在几场比赛中击败世界顶级Dota2球员(如果你对此感兴趣,这里是对算法和机器所玩游戏的完整分析)。


所以这是核心问题,为什么我们需要强化学习?它只用于游戏吗?或者它可以应用于现实世界的场景和问题吗?如果您是第一次学习强化学习,那么这个问题的答案超出了您的想象。它是人工智能领域中广泛使用和发展最快的技术之一。
以下是一些激励您构建增强系统的应用程序,
- 自驾车
- 赌博
- 机器人
- 推荐系统
- 广告与营销
强化学习的简要回顾与渊源
那么,当我们掌握了大量的机器学习和深度学习技术时,这个强化学习的来源是什么?“它由Rich Sutton和Andrew Barto发明,Rich的博士。论文顾问。“它已经在20世纪80年代形成,但当时是古老的。后来,Rich相信其有希望的性质,它最终会得到认可。
强化学习通过学习它所处的环境来支持自动化,机器学习和深度学习也是如此,不是相同的策略,而是支持自动化。那么,为什么要加强学习呢?
这非常类似于自然学习过程,其中,过程/模型将接收关于其是否表现良好的反馈。深度学习和机器学习也是学习过程,但最关注的是寻找现有数据中的模式。另一方面,强化学习通过反复试验方法进行学习,并最终获得正确的行动或全局最优。强化学习的另一个显着优势是我们无需像监督学习一样提供整个培训数据。相反,一些块就足够了。
了解强化学习
想象一下,你正在教你的猫新技巧,但不幸的是,猫不懂我们的语言所以我们无法告诉他们我们想用它们做什么。相反,模仿一种情况,你的猫试图以许多不同的方式作出反应。如果猫的反应是理想的,我们会用牛奶奖励他们。现在猜猜是什么,下一次猫暴露在相同的情况下,猫会执行类似的动作,期望更多的食物更热情。所以这是从积极的反应中学习,如果他们受到愤怒的面孔等负面反应的对待,他们往往不会向他们学习。
同样,这就是强化学习的工作原理,我们给机器一些输入和动作,然后根据输出奖励它们。奖励最大化将是我们的最终目标。现在让我们看看我们如何将上述同样的问题解释为强化学习问题。
- 猫将成为暴露于“环境”的“代理人”。
- 环境是一个房子/游乐区,取决于你教给它的东西。
- 遇到的情况称为“状态”,例如,你的猫在床下爬行或跑步。这些可以解释为状态。
- 代理通过执行从一个“状态”改变到另一个“状态”的动作来做出反应。
- 在州改变之后,我们根据所执行的行动给予代理“奖励”或“惩罚”。
- “政策”是选择行动以寻找更好结果的策略。
既然我们已经理解了强化学习的内容,那么让我们深入探讨强化学习和深层强化学习的起源和演变,以及如何解决有监督或无监督学习无法解决的问题,这是有趣的事实上,Google搜索引擎使用强化算法进行了优化。
熟悉强化学习术语
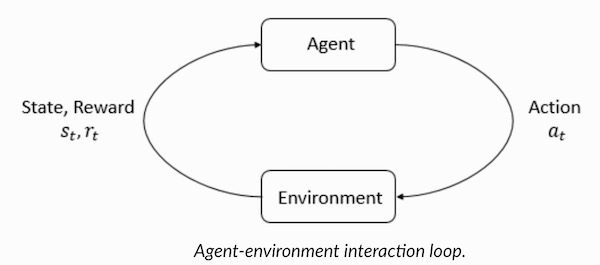
Agent和Environment在强化学习算法中起着至关重要的作用。环境是代理人幸存的世界。代理人还会感知来自环境的奖励信号,这个数字告诉它当前世界状态的好坏。代理人的目标是最大化其累积奖励,称为回报。在我们编写第一个强化学习算法之前,我们需要理解以下“术语”。

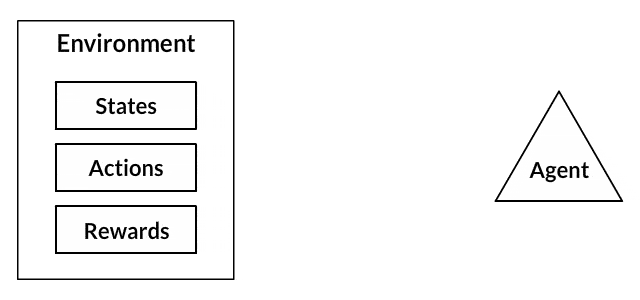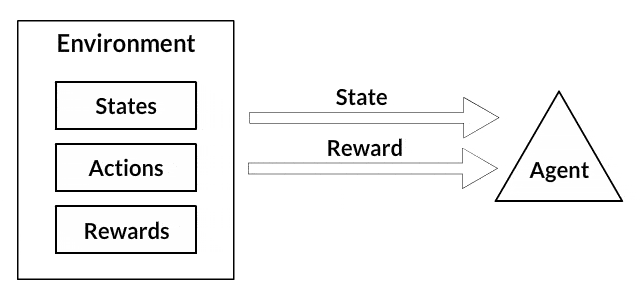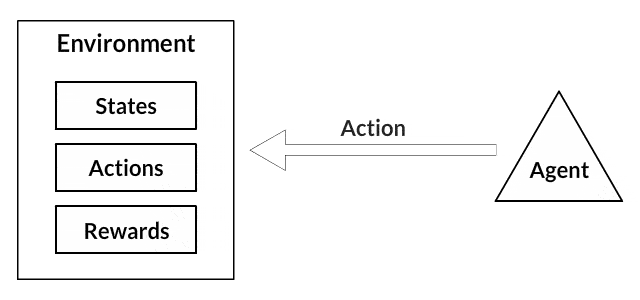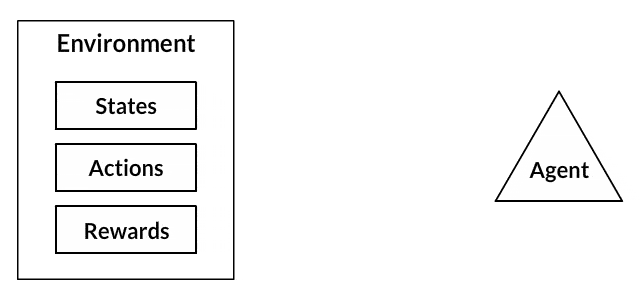
- 状态:状态是对世界的完整描述,它们不隐藏状态上存在的任何信息。它可以是位置,常数或动态。我们主要在数组,矩阵或更高阶张量中记录这些状态。
- 行动:行动通常基于环境,不同的环境导致基于代理的不同行为。代理的有效操作集记录在称为操作空间的空间中。这些通常是有限的。
- 环境:这是代理人生活和互动的地方。对于不同类型的环境,我们使用不同的奖励,政策等。
- 奖励和回报:奖励函数R是必须在强化学习中一直被跟踪的函数。它在调整,优化算法和停止训练算法方面起着至关重要的作用。这取决于当前的世界状况,刚刚采取的行动以及世界的下一个状态。
- 策略:策略是代理用于选择下一个操作的规则,这些也称为代理大脑。

现在我们已经看到了所有的加固术语,现在让我们使用强化算法来解决问题。在此之前,我们需要了解我们如何设计问题并在解决问题时分配此强化学习术语。
解决出租车问题
现在我们已经看到了所有的加固术语,现在让我们使用强化算法来解决问题。在此之前,我们需要了解我们如何设计问题并在解决问题时分配这种强化学习术语。
假设我们的出租车有一个培训区,我们教它将停车场的人员运送到四个不同的地方(R,G,Y,B) 。在此之前,我们需要了解并设置python开始运行的环境。如果你从头开始做python,我会推荐这篇文章。
您可以使用OpenAi的Gym来设置Taxi-Problem环境,这是解决强化问题最常用的库之一。好吧,在使用之前我们需要在你的机器上安装健身房,为此,你可以使用python包安装程序也称为pip。以下是要安装的命令。
pip install gym现在让我们看看我们的环境将如何呈现,此问题的所有模型和界面已经在健身房配置并命名为Taxi-V2。要在下面呈现此环境,请参阅代码段。
“有4个地点(用不同的字母标记),我们的工作是在一个地方接载乘客,然后将他送到另一个地方。我们获得了+20分的成功下降,并且每走一步都会失去1分。非法接送和下车行动也将被罚10分。“(资料来源:https://gym.openai.com/envs/Taxi-v2/ )
这将是控制台上的渲染输出:


完美,环境是OpenAi Gym的核心,它是统一的环境界面。以下是对我们非常有帮助的env方法:
env.reset:重置环境并返回随机初始状态。
env.step(action):将环境步进一步。
env.step(action)r eturns以下变量
observation:观察环境。reward:如果你的行为有益或没有done:表示我们是否已经成功接载并下降了一名乘客,也称为一集info:用于调试目的的其他信息,如性能和延迟env.render:渲染一个环境框架(有助于可视化环境)
现在我们已经看到了环境,让我们更深入地了解问题,出租车是这个停车场唯一的车。我们可以将停车场分成一个5x5网格,这为我们提供了25个可能的出租车位置。这25个地点是我们国家空间的一部分。请注意我们出租车的当前位置状态是坐标(3,1)。
在环境中,[(0,0), (0,4), (4,0), (4,3)]如果您可以将上面渲染的环境解释为坐标轴,则可以在四个可能的位置放置出租车中的乘客:R,G,Y,B或(行,列)坐标。
当我们还考虑到出租车内的一(1)个额外乘客状态时,我们可以将乘客位置和目的地位置的所有组合来达到我们的出租车环境的总数。有四(4)个目的地和五(4 + 1)个乘客位置。所以,我们的出租车环境5×5×5×4=500总共有可能的状态。代理遇到500个州中的一个,并采取行动。在我们的案例中,行动可以是向一个方向移动或决定接送乘客。
换句话说,我们有六个可能的操作:pickup,drop,north,east,south,west(。这四个方向是由出租车移动的移动)
这是:我们的代理在给定状态下可以采取的所有操作的集合。action space
您将在上图中注意到,由于墙壁,出租车无法在某些状态下执行某些操作。在环境的代码中,我们将简单地为每个墙壁打击提供-1惩罚,并且出租车不会移动到任何地方。这只会受到处罚,导致出租车考虑绕墙而行。
奖励表:创建出租车环境时,还会创建一个名为的初始奖励表P。我们可以把它想象成一个矩阵,它将状态数作为行数,将动作数作为列,即states × actions矩阵。
由于每个州都在这个矩阵中,我们可以看到分配给我们插图状态的默认奖励值:
>>> import gym
>>> env = gym.make("Taxi-v2").env
>>> env.P[328]
{0: [(1.0, 433, -1, False)],
1: [(1.0, 233, -1, False)],
2: [(1.0, 353, -1, False)],
3: [(1.0, 333, -1, False)],
4: [(1.0, 333, -10, False)],
5: [(1.0, 333, -10, False)]
}这本词典有一个结构{action: [(probability, nextstate, reward, done)]}。
- 0-5对应于出租车在图示中的当前状态下可以执行的动作(南,北,东,西,皮卡,下降)。
done用来告诉我们什么时候我们成功地将乘客送到了正确的位置。
为了在没有任何强化学习的情况下解决问题,我们可以设置目标状态,选择一些样本空间,然后如果它通过多次迭代达到目标状态,我们假设它是最大奖励,否则如果它接近目标则奖励增加如果步骤的奖励是-10,则提高州和罚款minimum。
现在让我们编写这个问题,而不需要强化学习。
由于我们P在每个州都有我们的默认奖励表,我们可以尝试让我们的出租车导航只使用它。
我们将创建一个无限循环,直到一个乘客到达一个目的地(一集),或者换句话说,当收到的奖励是20.该env.action_space.sample()方法自动从所有可能动作的集合中选择一个随机动作。
让我们看看发生了什么:
import gym
from time import sleep
# Creating thr env
env = gym.make("Taxi-v2").env
env.s = 328
# Setting the number of iterations, penalties and reward to zero,
epochs = 0
penalties, reward = 0, 0
frames = []
done = False
while not done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
# Put each rendered frame into the dictionary for animation
frames.append({
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
}
)
epochs += 1
print("Timesteps taken: {}".format(epochs))
print("Penalties incurred: {}".format(penalties))
# Printing all the possible actions, states, rewards.
def frames(frames):
for i, frame in enumerate(frames):
clear_output(wait=True)
print(frame['frame'].getvalue())
print(f"Timestep: {i + 1}")
print(f"State: {frame['state']}")
print(f"Action: {frame['action']}")
print(f"Reward: {frame['reward']}")
sleep(.1)
frames(frames)输出:

我们的问题已经解决但没有优化,或者这个算法不能一直工作,我们需要有一个合适的交互代理,这样机器/算法所需的迭代次数就会少得多。Q-Learning算法让我们看看它是如何在下一节中实现的。
Q-Learning简介
这种算法是最常用的基本强化算法,它利用环境奖励随着时间的推移学习,在给定状态下采取最佳动作。在上面的实现中,我们从代理将从中学习的奖励表“P”。使用奖励表,它选择下一个动作,如果它有益,然后他们更新一个名为Q值的新值。创建的这个新表称为Q表,它们映射到称为(State,Action)组合的组合。如果Q值更好,我们会有更优化的奖励。
例如,如果出租车面临包括其当前位置的乘客的状态,则与其他动作(例如,下降或北方)相比,拾取的Q值很可能更高。
Q值初始化为任意值,并且当代理将自身暴露给环境并通过执行不同的操作接收不同的奖励时,使用以下等式更新Q值:

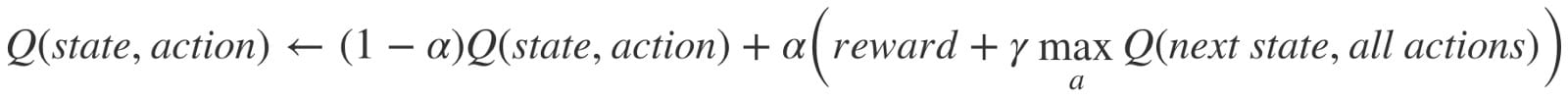
这里有一个问题,如何初始化这个Q值以及如何计算它们,因为我们用任意常量初始化Q值,然后当代理暴露给环境时,它通过执行不同的动作接收各种奖励。执行操作后,Q值由等式执行。
这里Alpha和Gamma是Q学习算法的参数。Alpha被称为学习率,γ被称为折扣因子,值的范围在0和1之间,有时等于1。伽玛可以为零,而阿尔法则不能,因为损失应该以一定的学习率更新。这里的Alpha表示与监督学习中使用的相同。Gamma决定了我们希望给予未来奖励多少重要性。
以下是算法简介,
- 步骤1:使用全零和Q值将Q表初始化为任意常量。
- 第2步:让代理人对环境做出反应并探索行动。对于状态中的每个更改,请为当前状态(S)的所有可能操作中选择任意一个。
- 步骤3:作为该动作(a)的结果,前进到下一个状态(S’)。
- 步骤4:对于来自状态(S’)的所有可能动作,选择具有最高Q值的动作。
- 步骤5:使用等式更新Q表值。
- 状态6:将下一个状态更改为当前状态。
- 步骤7:如果达到目标状态,则结束并重复该过程。
Python中的Q-Learning
import gym
import numpy as np
import random
from IPython.display import clear_output
# Init Taxi-V2 Env
env = gym.make("Taxi-v2").env
# Init arbitary values
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# Hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.1
all_epochs = []
all_penalties = []
for i in range(1, 100001):
state = env.reset()
# Init Vars
epochs, penalties, reward, = 0, 0, 0
done = False
while not done:
if random.uniform(0, 1) < epsilon:
# Check the action space
action = env.action_space.sample()
else:
# Check the learned values
action = np.argmax(q_table[state])
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
# Update the new value
new_value = (1 - alpha) * old_value + alpha * \
(reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1
if i % 100 == 0:
clear_output(wait=True)
print("Episode: {i}")
print("Training finished.")完美,现在你所有的值都将存储在变量中q_table 。
这就是你所有的模型都经过训练,环境现在可以更准确地降低乘客。在那里,你可以了解强化学习并能够编码新问题。
本文转载自 towardsdatascience,原文地址