


本文转载于公众号 科大讯飞,原文地址
如今,科技已经悄无声息的渗入我们每个人的生活,有时,你甚至毫无察觉。
比如,拨打10086等服务号,会听到一个优美的女声为您引导;
比如,启用导航软件,会听到一个流畅的语音播报路况。
再比如,使用时下流行的打车软件,有清晰语音为师傅播报乘客的位置。
而这些声音,其实都不是真的。是研究人员通过语音合成技术,让机器发出的声音。并且,经过多年的发展,机器合成的声音不仅能够达成普通人说话水平,更能赋予声音以个性、情感。很多时候,甚至能以假乱真。也许,在不久的将来,各种科幻片动画片中使用的“变声器”将不再是传说。
那么,现在就让科大讯飞带领大家一起来看一看这门神奇的技术是前世、今生。感受语音世界的神奇魅力。
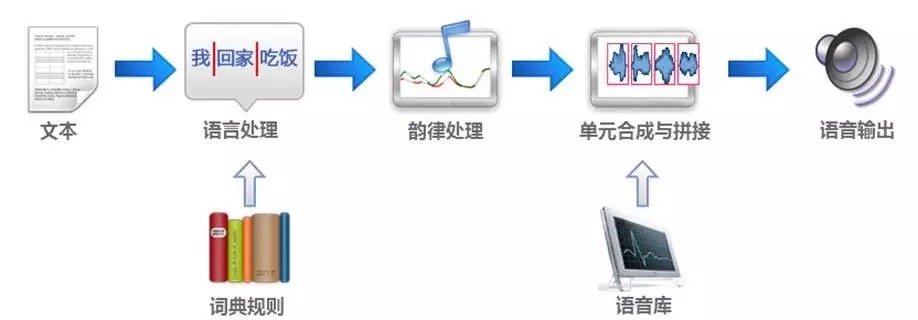
语音合成又称文语转换(Text toSpeech,TTS)技术,通过机械的、电子的方法产生人造语音。通俗的讲,语音合成技术就是赋予计算机像人一样可以自如说话的能力。
最早的“语音合成”是利用机械装置实现的。Kratzenstein在1779年研制出一种机械式语音合成器,用风箱模拟人的肺、簧片模拟声带、以皮革制成的共振腔模拟声道,通过改变共振腔的形状,可以合成出一些不同的元音。这可谓是人类历史上最早的合成技术。
19世纪出现电子器件以来,语音合成技术快速发展。1939年,贝尔实验室H. Dudley制作出一个电子合成器(Dudley’39)。这是一个利用共振峰原理制作的语音合成器,它以一些白噪音似的激励产生非浊音信号,以周期性的激励产生浊音信号。模拟声道的共振器是通过一个10阶的带通滤波器建模,模型的增益通过人来控制。

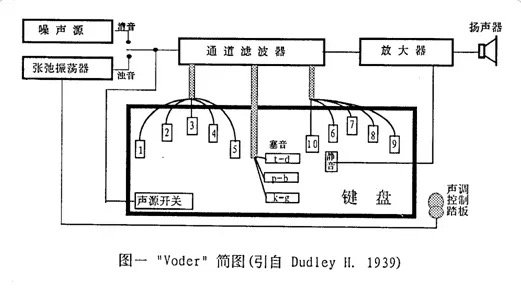


此后的一个世纪,语音合成技术不断取得一个又一个的突破。
1960年,G. Fant系统地阐述了语音产生的理论,极大地推动了语音合成技术的进步。


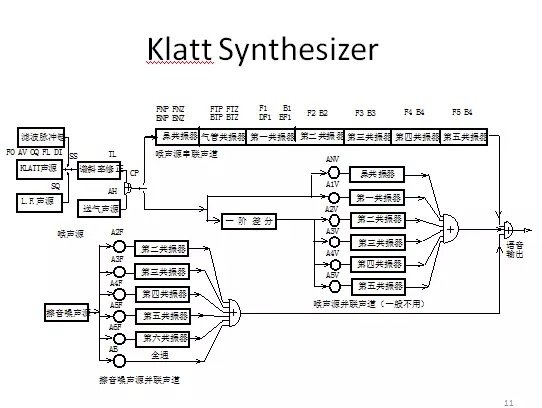
1980年,D. Klatt设计出串/并联混合型共振峰合成器,可以模拟不同的嗓音。

20世纪80年代末,基音同步叠加的时域波形修改(PSOLA)算法被提出,较好地解决了语音段之间的拼接问题,有力推动了语音合成技术的发展。
1990年代随着电子计算机的运算和存储能力的迅猛发展,基于大语料库的单元挑选与波形拼接合成方法逐渐成熟并开始商业应用。它的基本思想是从预先录制和标注好的语音库中挑选合适的单元,进行少量的调整(或者不进行调整),拼接得到最终的合成语音,其优势在于保持了高质量的原始声音。

20世纪末,可训练的语音合成方法(Trainable TTS)被提出。该方法基于统计建模和机器学习的方法,根据一定的语音数据进行训练并快速构建合成系统。这种方法可以自动快速的构建合成系统,系统尺寸很小,很适合嵌入式设备上的应用以及多样化语音合成方面的需求。
21世纪,语音合成技术飞速发展。在声音合成达到真人说话水平后,学界渐渐把眼光转向音色合成、情感合成等领域,力求使合成的声音更加自然,并具备个性化特征。

