


引言
认识“概念”(concept)是人类认识世界的重要基石。对于自然语言理解,提取概念和对文本进行概念化(conceptualization)是至关重要的研究问题。例如,当看到本田思域(Honda Civic)或者现代伊兰特(Hyundai Elantra)时,人们可以联想到“油耗低的车”或者“经济型车”这类的概念,并且能进而联想到福特福克斯(Ford Focus)或者尼桑Versa(Nissan Versa)等车型。


过去的研究工作,包括DBPedia, YAGO, Probase等等知识图谱或者概念库,从维基百科或者网页文章中提取各种不同的概念。但是这样提取的概念和用户的认知视角并不一致。例如,与其认识到丰田4Runner是一款丰田SUV或者说是一种汽车,我们更感兴趣是否能把它概念化为“底盘高的汽车”或者“越野型汽车”。类似地,如果一篇文章在讨论《简爱》,《呼啸山庄》,《了不起的盖斯比》等电影,如果我们能认识到它在讨论“小说改编的电影”这个概念,那么会帮助极大。然而,目前的知识图谱等工作目的是建立一个关于这个世界的结构化知识表示,概念提取自语法严谨的文章。因此,它们不能从用户的视角去对文本(例如query和document)进行概念化,从而理解用户的意图。另一方面,目前的工作也主要在于提取长期稳定的概念,难以提取短时间出现的热门概念以(例如“贺岁大片”,“2019七月新番”)及它们之间的联系。
我们提出了ConcepT概念挖掘系统,用以提取符合用户兴趣和认知粒度的概念。与以往工作不同的是,ConcepT系统从大量的用户query搜索点击日志中提取概念,并进一步将主题,概念,和实体联系在一起,构成一个分层级的认知系统。目前,ConcepT被部署在腾讯QQ浏览器中,用以挖掘不同的概念,增强对用户query意图的理解和对长文章的主题刻画,并支持搜索推荐等业务。目前它已经提取了超过20万高质量的基于用户视角的概念,并以每天挖掘超过11000个新概念的速度在不断成长。ConcepT系统的核心算法架构同样适用于英语等其他语言。
我们的主要贡献点包括:
- 我们基于两种无监督模型,bootstrapping和query-title alignment,从大量搜索日志中提取出以用户为中心(user-centered)的概念;
- 基于以上策略提取的种子数据,我们进一步训练有监督模型(条件随机场CRF + 分类器)来从输入query和文章title中进一步提取概念短语;
- 我们提出了两种策略来对长文章打上概念标签,丰富对文章主题的刻画;
- 通过提取主题,概念,实体之间的 isA关系,我们构建了一个三层的分级系统,来保存它们之间的联系。
实验证明,ConcepT系统能精确地从query中提取高质量的概念短语,以及将长文章打上相关的概念标签。在线A/B test证明,ConcepT系统能相对提升6.01%的信息流曝光效率。
方法
ConcepT系统针对三个问题分别提出了不同的解决方案:概念挖掘(Concept Mining),概念标记(Concept Tagging),层级结构构建(Taxonomy Construction)。图2 展示了ConcepT系统概念挖掘的原理。主要包括三种策略:
- Pattern-Concept Bootstrapping. 这种方法以一批种子模版为起点,匹配query得到一些候选概念。再基于得到的候选概念,去生成新的模版。新的模版应该既能匹配一定量的已有的概念,也能具有扩展性,匹配到一定量的新的概念,满足此条件的模版会被保留。如此循环往复,从而不断得到更多的候选概念以及匹配模版。
- Query-Title Alignment. 这种方法利用对其输入的query和点击的文章标题来抽取候选概念。其提取query和文章标题中共有的N-gram作为候选概念,并且假设query中的N-gram在文章标题中可以有更丰富的描述。
- Sequence Labeling. 这种方法将概念提取建模为序列标注问题,训练条件随机场序列标注模型来提取候选概念。
经过以上三种策略得到的候选概念,将统一由一个分类器过滤以便控制概念的质量,得到最终保留的概念集合。

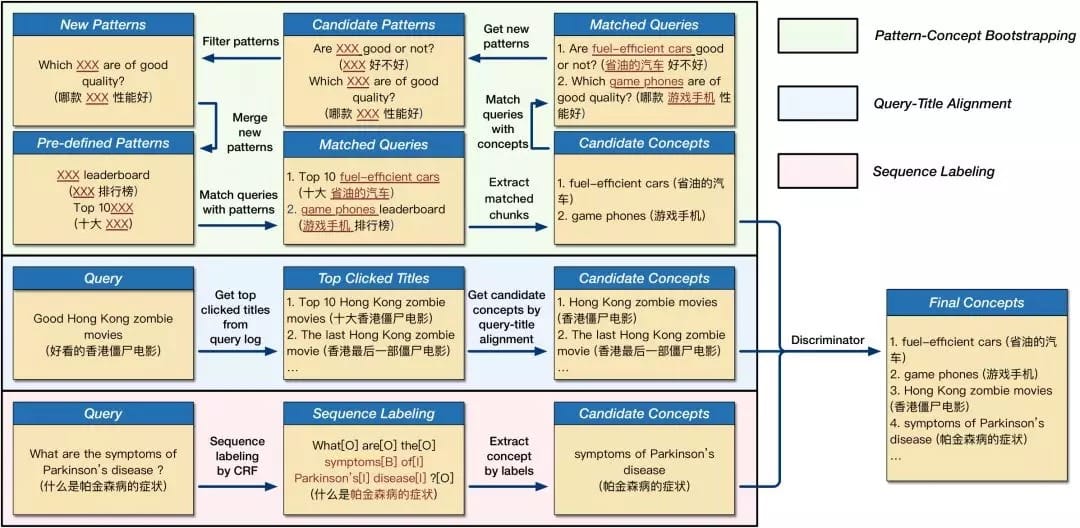
图3 展示了ConcepT系统给文章打上概念标签的原理。主要包含两种策略:
- 基于匹配的标记算法。该算法从文章中提取关键实体,然后利用实体与概念间的上下位关系,得到相关的概念。因为每个概念文本很短,因此利用该概念的高点击的文章标题对概念进行扩充表示。最后再比较扩充后的概念表示与文章之间的相似度,决定是否将该文章标记上给定的概念标签。
- 基于概率推断的标记算法。该算法从文章中提取关键实体,当实体与概念之间的上下位尚未建立时,利用实体词的上下文中出现的单词,找到候选的概念。最后,对于每一个候选概念,算法将根据文章到每一个实体词的概率以及实体词到概念的条件概率进行综合,来衡量文章到候选概念的关联程度。根据得到的分数,决定该文章可以打上哪些概念标签。


图4 展示了ConcepT构建的“主题-概念-实体”三级层级关系库。利用该层级关系,可以对长短文本有一个多层次的丰富的主题刻画。其中,构建实体词和概念之间的联系,与图三种计算实体和概念之间的关联程度算法一致,即基于实体上下文中的词进行概率推断。而概念到主题之间的关联,则基于包含该概念的文章由多少比例属于该主题而确定。此处的主题是预定义的31类主题,包括“科技”,“娱乐”,“时事”等等。文章的主题分类则是由一个基于词向量的文本分类模型完成。


实验结果
我们对ConcepT系统的概念抽取,文章标记,层级建设等能力,利用离线评测和在线A/B test做了大量的评估。



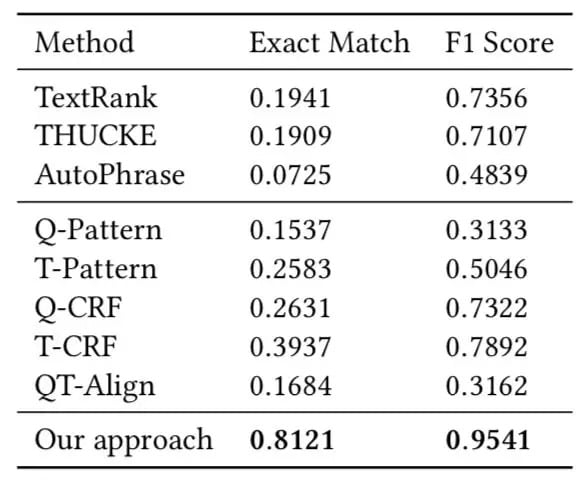
我们对比了不同的已有的关键字或者质量短语提取的算法和程序,以及我们的方法的变种。实验证明我们的综合策略达到了最高的准确度,并且对比其他算法有明显提升。实验所用的概念抽取数据集是从真实搜索日志中抽取并人工标记构建的,该数据集已经开源。

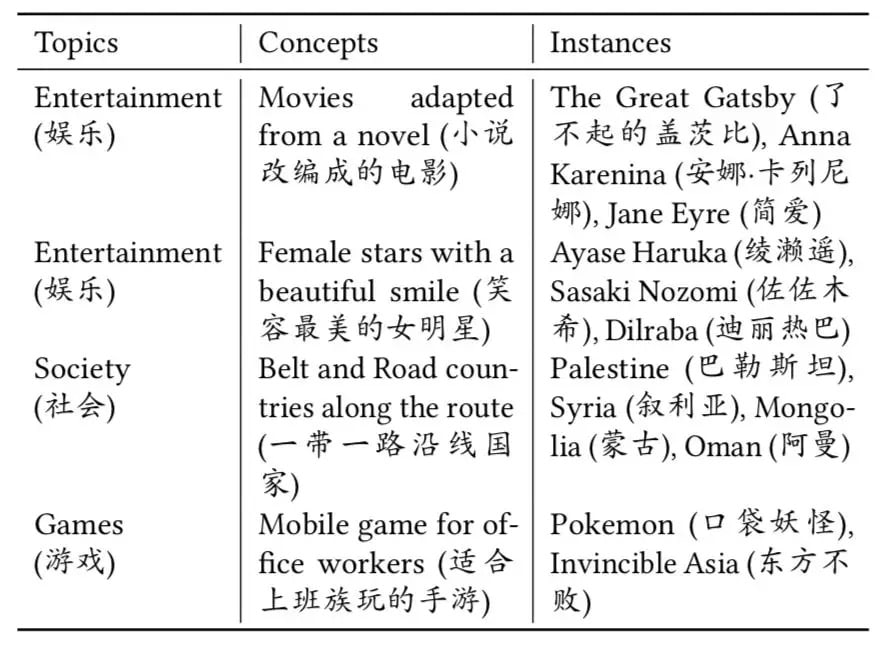
目前平均一个概念包含3.44个下级实体,最大的包含59个实体。人工评测层级关系的准确率为96.59%。


ConcepT系统对QQ浏览器信息流业务各项指标有明显提升。其中最重要的指标曝光效率(IE)相对提升了6.01%。

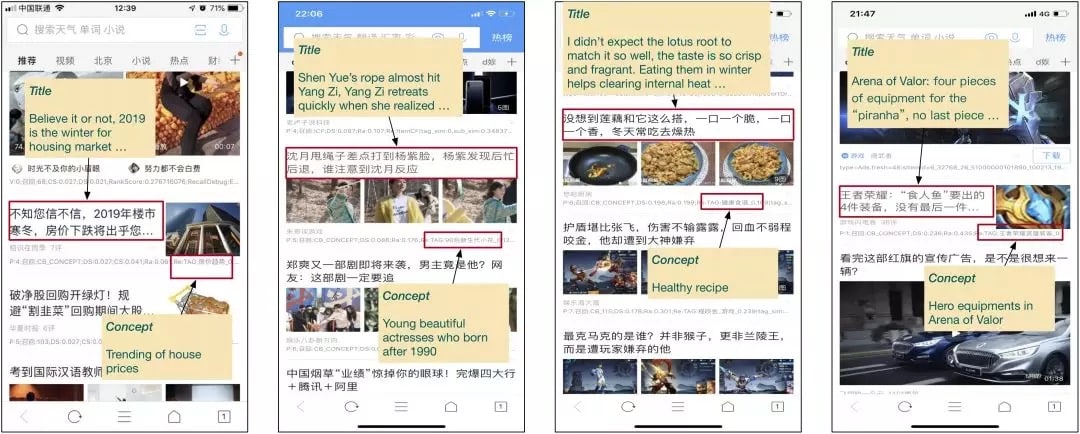
目前每天可处理96700篇文章,其中约35%可以打上概念标签。我们创建了一个包含11547篇文章的概念标记数据用以评测标记的准确率。人工评测发现,目前系统的标记准确度达96%。
论文:A User-Centered Concept Mining System for Query and Document Understanding at Tencent


论文地址:
https://arxiv.org/abs/1905.08487
相关数据资源:
https://github.com/BangLiu/ConcepT
本文转自公众号 腾讯技术工程,原文地址