


In mostNLPResearchers believe that 2018 year is a year of technological advancement, newPre-training NLPThe model breaks the task record from emotional analysis to question and answer.
But for others, 2018 is the year that NLP has ruined Sesame Street forever.
First comeELMo,thenBERT, now BigBird sits on topGLUE ranking. My own thoughts have been ruined by this naming convention when I heard " I have been playingBert"TimeFor example, the image that emerged in my mind was not the bird head that was blurred in my childhood, but something. like this:
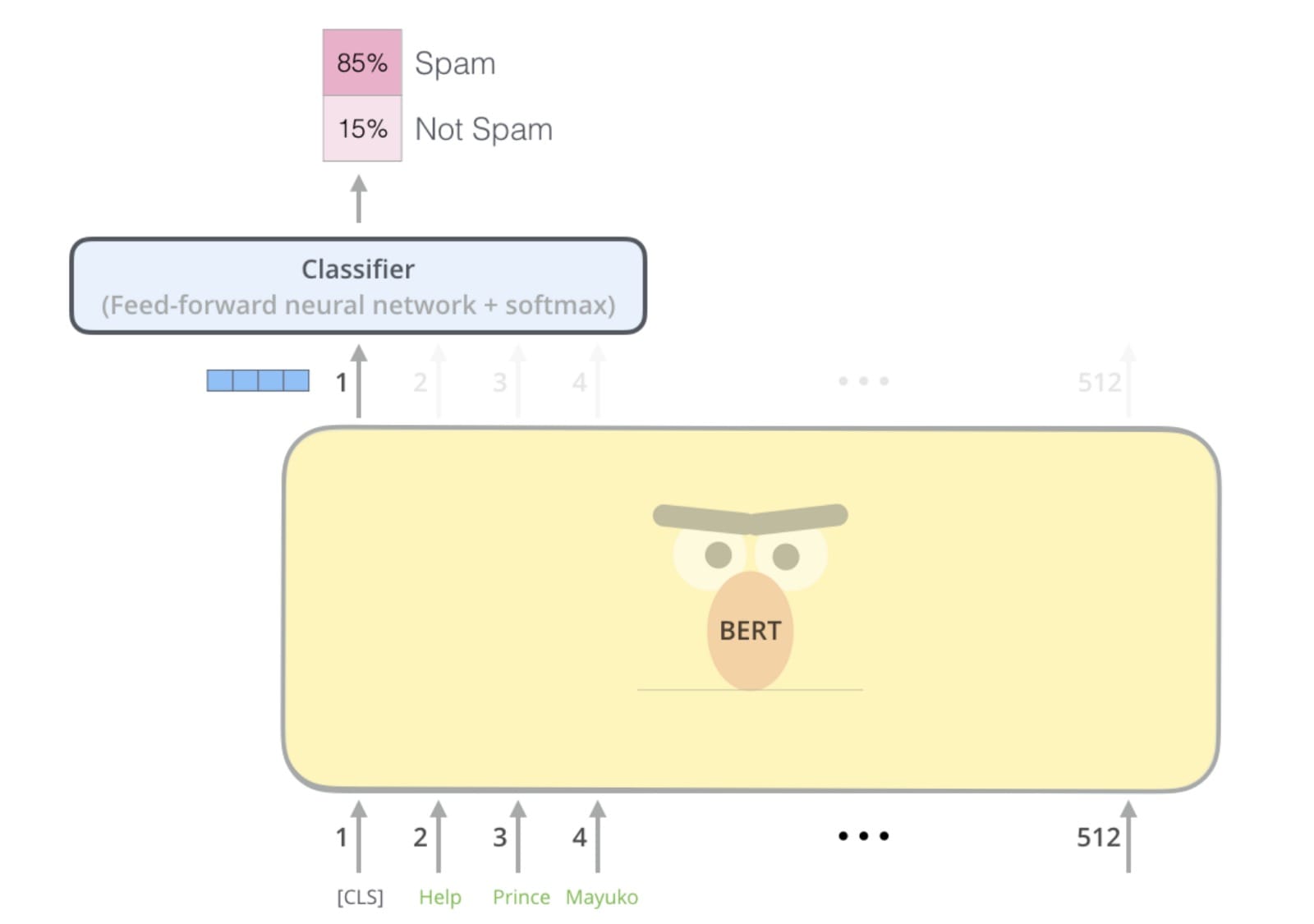
I can't see that,Illustration BERT!
I ask you-if Sesame Street is not safe for NLP model brands, what is it?
But there is a model that keeps my childhood memories intact. This algorithm is still anonymous and is referred to by its author as "language model" or "our method." Only whenAuthor of a paperThe whimsical model of this nameless creation needs to be compared when they are considered worthy of a nickname. And it is notLotteryOr Grover or Cookie Monster; the name describes exactly what the algorithm is, not more:OpenAI GPTFromOpenAIPre-trainedTransformer.
But like its naming, OpenAI GPT was ruined by BERT from the GLUE rankings. One reason for the collapse of GPT is that it is using traditionLanguage modelingPre-trained, that is, predicting the next word in the sentence. In contrast, BERT is pre-trained.Masked language modeling.This is a filled blank movement: guess the missing ("cover") words because they came beforeRear. This two-way architecture enables BERTs to learn richer representations and ultimately perform better in NLP benchmarks.
Therefore, at the end of 2018, it seems that OpenAI GPT will always be known to the history, because it is the common name of BERT, the eccentric one-way predecessor.
But 2019 has told a different story. It turns out that the one-way architecture that led to the collapse of GPT in 2018 gives it the ability to do what BERT has never done (or at least not designed for it):Write a story about talking about a unicorn :

You see, left-to-right language modeling is not just a pre-training; it can also complete a very practical task: language generation.If you can predict the next word in a sentence, then you can predict the word after that, then the next word, and there will be many words soon.If your language modeling is good enough, these words will form meaningful sentences, sentences will form coherent paragraphs, and these paragraphs will form whatever you want.
And on February 2019, 2, OpenAI’s language model was indeed good enough – enough to write about unicorns,Generate fake newsAnd writingAnti-recycling declarationstory. It was even given a new name:OpenAI GPT-2.
那么GPT-2的人类写作能力的秘诀是什么?没有基本的算法突破; 这是扩大规模的壮举。GPT-2拥有惊人的15亿个参数(比原来的GPT多15倍),并接受了来自800万个网站的文本培训。
How to understand a model with 15 billion parameters? Let's see if visualization is helpful.
Visualize GPT-2
OpenAI did not release the full GPT-2 model for fear of malicious use, but they did release a smaller version equivalent to the original GPT (117 M parameters) and trained on a new, larger data set. Although not as powerful as a large model, the smaller version still has some language generation sorting. Let's see if visualization can help us better understand this model.
Notes: You can be hereColab notebookCreate the following visualization, or directly fromGitHub warehousecreate.
An illustrative example
Let's see how the GPT-2 small model completes this sentence: the dog on the boat ran

This is the content generated by the model: the dog on the boat runs,On board
Found the dog.
It looks very reasonable, right? Let us pass nowdogchange toMotorTo slightly tweak the example and see what the model generates. : The motor on the boat ran away
The sentence now completed: the motor on board
Operates at approximately 100 miles per hour.
By changing the word at the beginning of the sentence, we got completely different results. The model seems to understand that the type of running dog is completely different from the type of motor.
How GPT-2 knows to pay close attention to thisdo g andelectric motorEspecially because this sentence appears in the sentence? Ok, GPT-2 is based onTransformers,It is aNotesModel – It learns to focus on the first few words most relevant to the task at hand: predict the next word in the sentence.
Let's see that the focus of GPT-2 is " Dog running on board ":

The lines read from left to right are in the guessing sentencenextThe position of the model attention is displayed when the word is used (color intensity represents attention). So whenRun outAfter guessing the next word.The model will pay close attention to this situationdog. This makes sense because knowing who is doing what or what is being done is critical to guessing what will happen next.
In linguistic terms, the model focuses onOn boardNoun phrase"dog"Ofhead. There are indications that GPT-2 capture is good because the above attention pattern is just a few other language attributes.OneSaid144Pay attention to the pattern in the model. GPT-2 has 12 layers of transformers, and each layer has 12 independent attention mechanisms called "heads"; the result is 12 x 12 = 144 different attention modes.Here, we visualize all 144, highlighting the one we just saw:
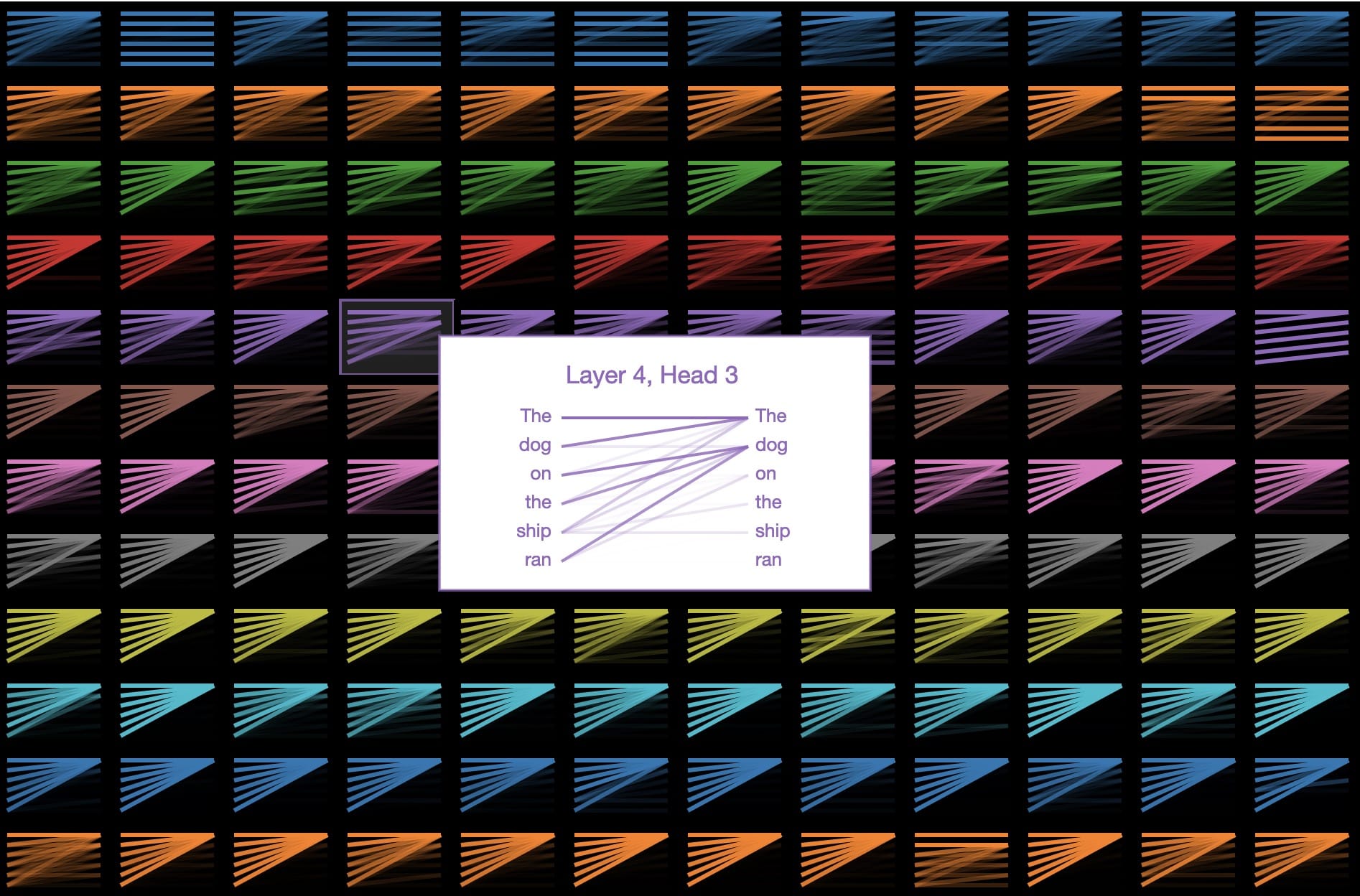
We can see that these patterns come in many different forms. This is another interesting one:

This layer/head focuses all of the attention in the sentencePrevious wordon. This makes sense because adjacent words are usually most relevant to predicting the next word. traditionaln -gramThe language model is based on the same intuition.
But why do so many attention patterns look like this?
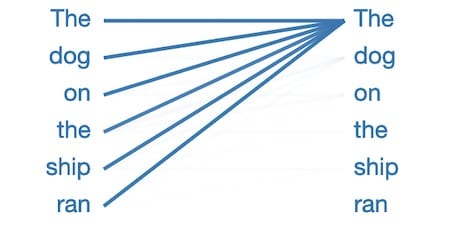
In this mode, almost all attention is focused on the first word in the sentence, while other words are ignored. This seems to be an empty pattern, indicating that the attention header did not find any language phenomena it was looking for. The model seems to have repositioned the first word as a place to look when it doesn't have a better focus.
Cat in _____

Well, if we want NLP to tarnish our memory of Sesame Street, then I guess Dr. Seuss is also a fair game. Let's see how GPT-2 works from classic classics.Hat CatComplete these series : On a kite line, we saw our mother's new dress! Her dresses are pink, white and...
Here's how GPT-2 completes the last sentence: her dress is pink, white and
Blue dots.
not bad! Original text红色, so at least we know that this is more than just memory.
So how does GPT-2 know the color of choice? Perhaps because the following attention mode seems to recognize a comma-separated list:
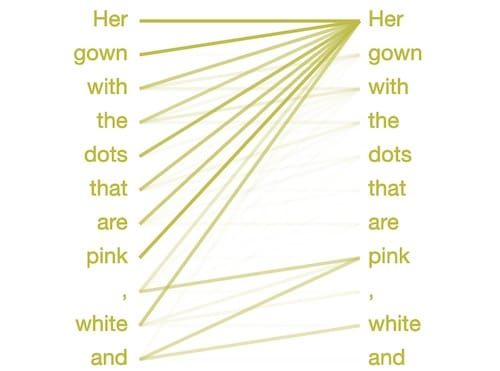
In order to decide the word和, The model focuses its attention on the previous item in the list- 粉 红色和white.It knows to choose a word that matches the previous item type, in this case a color.
what name?
GPT-2 seems to be particularly good at writing short biographies by name only.

As a fun exercise, try getting GPT-2 from the tip"Who is <your name>?"Generate text. This special hint usually triggers the model to write a short biography, probably because it is a common preface network of author creatures.
Here are some bios generated for the prompt "Who is Jesse Vig?":
“Jesse Vig is a social media marketing expert and former social media marketing manager. He is the co-founder and CEO of VigMedia.com and most recently the founder and CEO of VigMedia.com.”
Not bad! It's a bit repetitive, but it's a good way to personalize the story in an unexpected way. This is another one:
"Jessieg is the son of the evangelical missionary James Vig. He moved to the United States in 1964 and became a missionary at the University of Michigan, where he taught 18 years until 2007 died 10."
In the last example, GPT-2 is very clever and knows that my other self-family has the same last name. Let's take a look at where GPT-2 focuses when choosing this last name:

When decided toJamesLater, when predicting the word, this model focused on the last name I mentioned earlier. (Note that inside the model,VigHas been divided into words" V"with" Ig",Because it is an uncommon word. It seems that this mode of attention is specifically used to identify the relationship between family names. To test this, let's change the text a bit:
"Jessievig isAn evangelical missionary named JamesOfcolleague ......"

Since James is just acolleagueThis mode of attention almost completely ignores my last name.
note: GPT-2 appears to generate biographies based on perceived race and gender associated with the name.Further research is needed to understand the possible coding bias of the model; you can read more on this topicit's here.
The future is productive
Just last year, generated variousimage.Video.AudioAnd the ability to text content has increased to the point where we can no longer trust our senses and judgments about reality or falsehood.
And this is just the beginning; these technologies will continue to evolve and merge with each other.Soon when we staredThispersondoesnotexist.comWhen they generate faces, they will satisfy our eyes, they will talk to us about their lives and reveal the quirks of the personality they produce.
The most immediate danger may be a mixture of real and generated. We have already seenObama as an AI傀儡和Steve Buscemi-Jennifer Lawrence chimera's video. Soon, theseDeep waterWill become an individual. So, when your mom calls and says she needs 500 dollars to connect to the Cayman Islands, ask myself: Is this really my mother, or a language-generated AI, from her Facebook video released 5 years ago? Got the mother'sSound skin?
But for now, let us enjoy the story of talking about unicorns.
Resources:
Used to create the above visualizationColab notebook
For visualization toolsGitHub repoUse these awesome tools/frames to build:
Deconstructing BERT: Extracting 1 patterns from 6 billion parameters
This article is transferred fromTowards Data Science》.Original address(Requires Internet Science)

Comments