

This article is reproduced in the public number of the University of Science and Technology,Original address
Nowadays, technology has quietly infiltrated into the lives of each of us, and sometimes you are not even aware of it.
For example, if you call 10086 and other service numbers, you will hear a beautiful female voice to guide you;
For example, if you enable the navigation software, you will hear a smooth voice broadcast.
For example, using the popular taxi software, there is clear voice for the master to broadcast the passenger's position.
And these sounds are actually not true.It is the sound that the researchers use to make the machine emit sound through speech synthesis technology. Moreover, after years of development, the sound of machine synthesis can not only achieve the level of ordinary people's speech, but also give the voice personality and emotion. In many cases, it can even be fake. Perhaps, in the near future, the "voice changer" used in various science fiction cartoons will no longer be a legend.
So, let Keda Xunfei lead everyone to come and see that this magical technology is past and present. Feel the magical charm of the voice world.
Speech synthesis is also known as text to speech (Text toSpeech,TTSTechnology that produces artificial speech through mechanical and electronic methods.In layman's terms, speech synthesis technology is the ability to give computers the ability to speak as humans.
The earliest "speech synthesis" was achieved using mechanical devices.KratzensteinOn1779Developed aMechanical speech synthesizerThe bellows simulates the human lung, the reed simulates the vocal cords, and the resonant cavity analog sound made of leather. By changing the shape of the resonant cavity, some different vowels can be synthesized. This is the earliest synthetic technique in human history.
Since the emergence of electronic devices in the 19 century, speech synthesis technology has developed rapidly.1939Bell LabsH. DudleyMake oneElectronic synthesizer(Dudley'39). This is a speech synthesizer made using the formant principle. It uses some white noise-like excitations to generate non-voiced signals and periodic excitations to generate voiced signals. The resonator of the analog channel is modeled by a 10-order bandpass filter, and the gain of the model is controlled by humans.
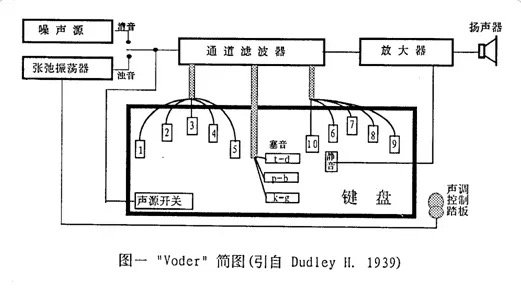

In the following century, speech synthesis technology has continuously made breakthroughs one after another.
1960year,G. FantThe theory of speech production is systematically expounded, which greatly promotes the advancement of speech synthesis technology.

1980year,D. KlattDesignSeries/parallel hybrid formant synthesizerCan simulate different arpeggios.
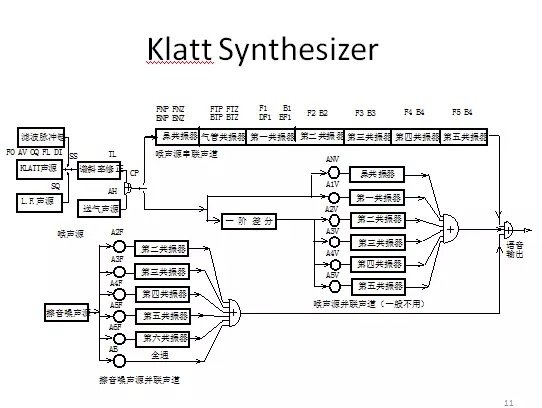
20 century 80 era.Time Domain Waveform Modification (PSOLA) Algorithm for Pitch Synchronous OverlayIt has been proposed to better solve the problem of splicing between speech segments, which has greatly promoted the development of speech synthesis technology.
1990With the rapid development of computing and storage capabilities of electronic computers,Unit selection and waveform stitching synthesis method based on large corpusGradually mature and begin commercial applications. Its basic idea is to select the appropriate unit from the pre-recorded and labeled speech library, make a small amount of adjustment (or no adjustment), and stitch the final synthesized speech. The advantage is that the original sound is maintained with high quality.
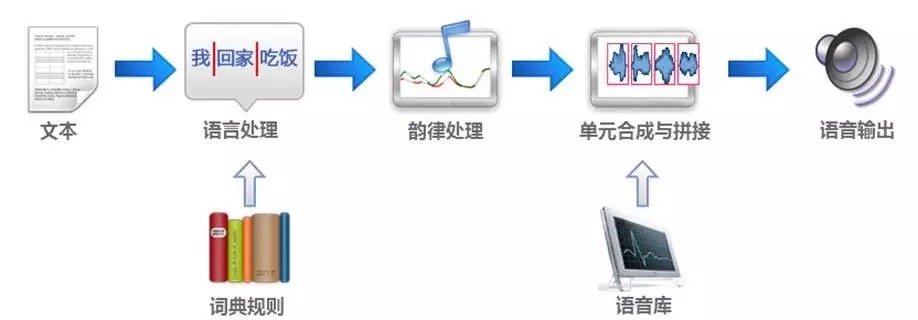
End of 20 century.Trainable speech synthesis method (Trainable TTS)Been proposed. The method is based on statistical modeling and machine learning methods, training according to certain speech data and quickly constructing a synthetic system. This method can automatically and quickly build a synthesis system with a small system size, which is suitable for applications on embedded devices and diverse speech synthesis requirements.
21 世纪, speech synthesis technology is developing rapidly. After the sound synthesis reaches the level of real people's speech, the academic circles gradually turn their eyes to the fields of sound synthesis, emotion synthesis, etc., and strive to make the synthesized sound more natural and have personalized characteristics.


Comment
Hahaha, hey.