

This article is reproduced from the public number PaperWeekly.Original address
Shannon Technology recently proposed Glyce,For the first time, using the Chinese character information (Glyph) in the framework of deep learning, swept the 13 Chinese natural language task record, including: (1) word-level language model (2) word-level language model (3) Chinese word segmentation (4) named entity recognition (5) part-of-speech tagging (6) syntactic dependency analysis (7) semantic decision labeling (8) semantics Similarity (9) Intent Recognition (10) Sentiment Analysis (11) Machine Translation (12) Text Classification (13) Text Analysis.

Paper link: https://arxiv.org/abs/1901.10125
Introduction to the paper
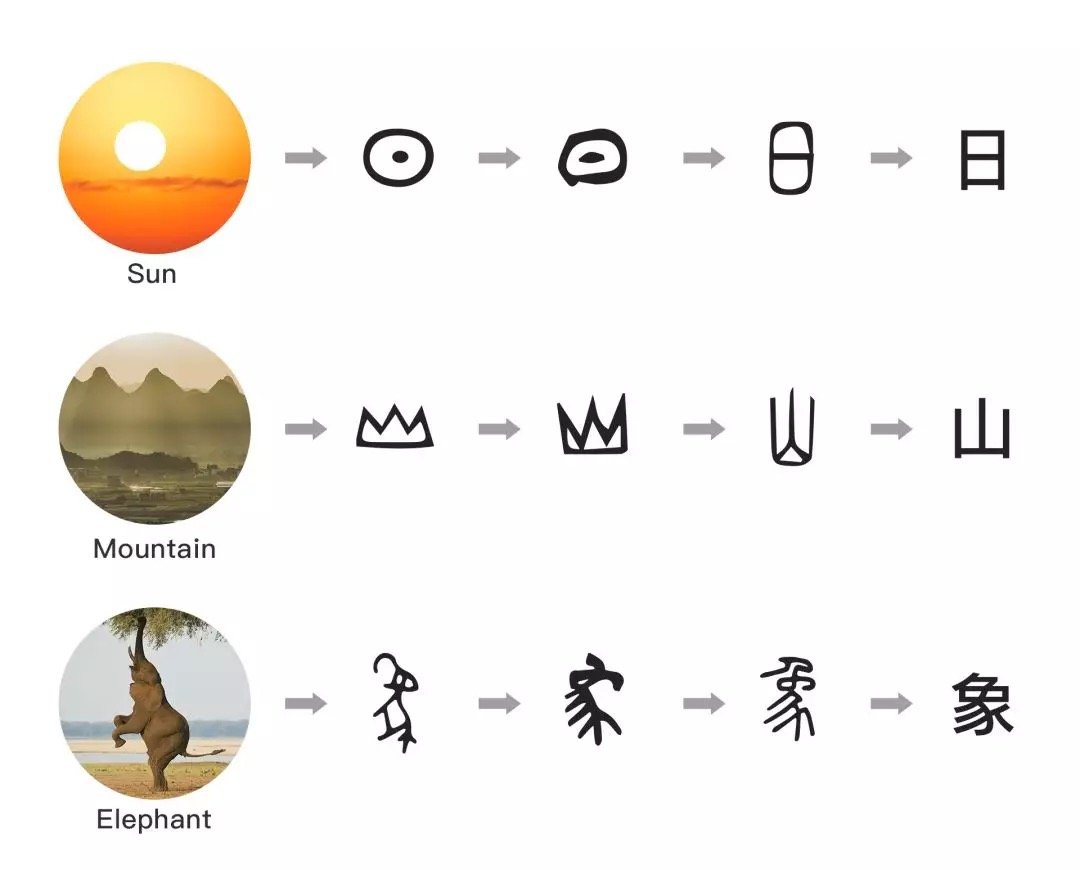
Chinese characters are logographic languages, which have evolved over thousands of years and are the oldest words still used in the world today. There is an essential difference between Chinese characters and English, because the origin of most Chinese characters is graphics, and the Chinese characters have rich voice information. Even people who are illiterate can sometimes guess the approximate meaning of a word.
On the contrary, it is difficult for English to guess the semantics from the glyphs, because English is an alphabetic language, and the Roman alphabet based on it is more about the pronunciation of words than semantics.
However, most of the methods of Chinese natural language processing today are based on English. NLP The processing flow: based on the ID of the word or word, each word or word has a corresponding vector, and does not consider the information of the Chinese glyph.
Glyce proposed a semantic representation based on the Chinese character:Think of Chinese characters as a picture, and then use the convolutional neural network to learn the semantics, so that you can make full use of the graphic information in Chinese characters and enhance the semantic expression of deep learning vectors.Glyce refreshed history on a total of 13 items, nearly all Chinese natural language processing tasks.
Detailed explanation of the thesis
In theory, Chinese characters can be directly input into the convolutional neural network as a picture. But the effect achieved in this way is not good.Glyce tried to solve this problem in three ways:
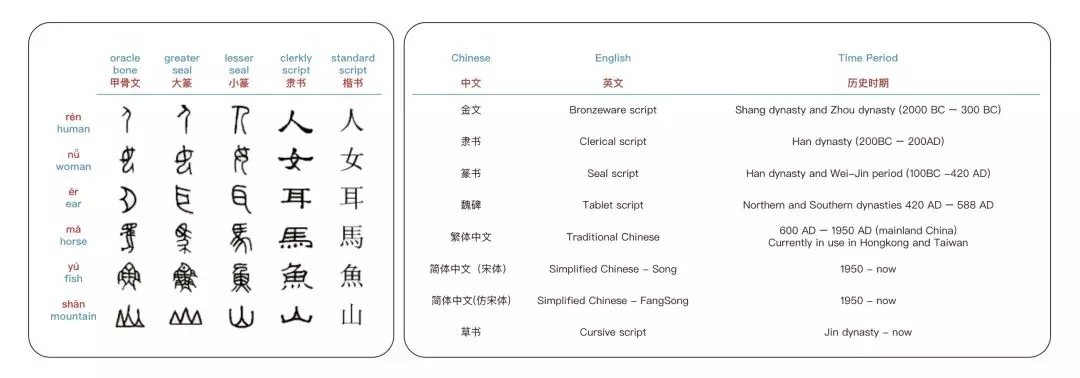
Use Chinese characters from different historical periods
The Simplified Chinese characters that are widely used today have evolved over a long period of time. Simplified Chinese writing is more convenient, but at the same time it also loses a lot of original graphic information.Glyce proposes to use Chinese characters from different historical periodsFrom the Jinwen in the Zhou Dynasty, the Lishu in the Han Dynasty, the script in the Wei and Jin Dynasties, the Weibei in the Southern and Northern Dynasties, and the Traditional and Simplified Chinese. These different categories of characters cover semantic information more comprehensively.
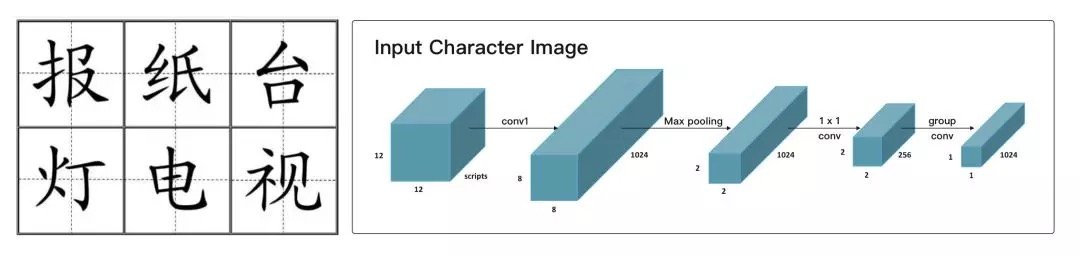
Presenting the Tianzige in the shape of a Chinese character -CNNArchitecture
Glyce made some comments to modify the internal structure of CNN to make the model more suitable for processing Chinese characters.The main improvements focus on two aspects. The first is to prevent over-fitting and reduce the amount of parameters involved in the CNN, such as changing the conv layer to grouped conv. Another second interesting point is that the last layer uses pooling to turn the image input into a grid of 2*2. The paper mentions that this model is very consistent with the Chinese character grid pattern, and the Tian character lattice structure is in fact very consistent with the writing order of Chinese characters.
Multi-task Learning
Compared to image classification tasks, there are millions or tens of millions of training data, and there are only a thousand of Chinese characters. Even with different fonts, the model can only see tens of thousands of different character image samples. This poses a challenge to the generalization of images.
To solve this problem,Glyce proposes to use image classification tasks as an auxiliary training objective.. The glyph vector output by CNN will be entered into the character-based classification task at the same time. The actual training function is the linear weighting of the task-specific loss function and the glyph image recognition loss function:
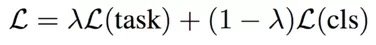
Glyce Chinese character vector
Glyce stacks the same characters from different historical periods into different channels, and encodes these image information through CNN to get the glyph vector. The obtained glyph vector is input to the image classification model to obtain the loss function of the glyph image recognition. The final Glyce Chinese character vector is then obtained by combining the glyph vector with the corresponding Chinese char-id vector via a highway network or a fully connected method.
Glyce Chinese word vector
Since Chinese words can be regarded as composed of Chinese characters, Glyce obtains the semantic meaning of more fine-grained words by making full use of the Chinese characters in the Chinese words. Use the Glyce word vector to get the representation of the corresponding word in the word.
Because of the uncertainty of the number of words in the Chinese word, Glyce uses the max pooling layer to filter the features of all the obtained Glyce word vectors to maintain the dimensional invariance. The resulting vector is stitched together with the word-id vector to get the final Glyce Chinese word vector.
experiment
使用 Glyce 的编码方式分别在:(1)字级别语言模型(2)词级别语言模型(3)中文分词(4)命名实体识别(5)词性标注(6)句法依存分析(7)语义决策标注(8)语义相似度(9)意图识别(10)情感分析(11)机器翻译(12)文本分类(13)篇章分析,共 13 个中文自然语言处理任务上进行了实验。
The experimental results refreshed the records of all experimental tasks, fully demonstrating the validity and robustness of Glyce's Chinese semantic representation coding, and demonstrating the design advantages of Glyce.
Word level language model

The word-level language model uses the Chinese Tree-Bank 6.0 (CTB6.0) corpus and uses PPL (Confusion) as the final evaluation indicator. By using the loss function of 8 historical fonts and image classification, the PPL (confusion) of the word-level based language model reaches 50.67.
Word level language model

The word-level language model uses the Chinese Tree-Bank 6.0 (CTB6.0) corpus and uses PPL (Confusion) as the final evaluation indicator. After comparison experiments, the word-ID vector and the glyce word vector work best on the word-level language model, and the PPL (confusion) reaches 175.1.
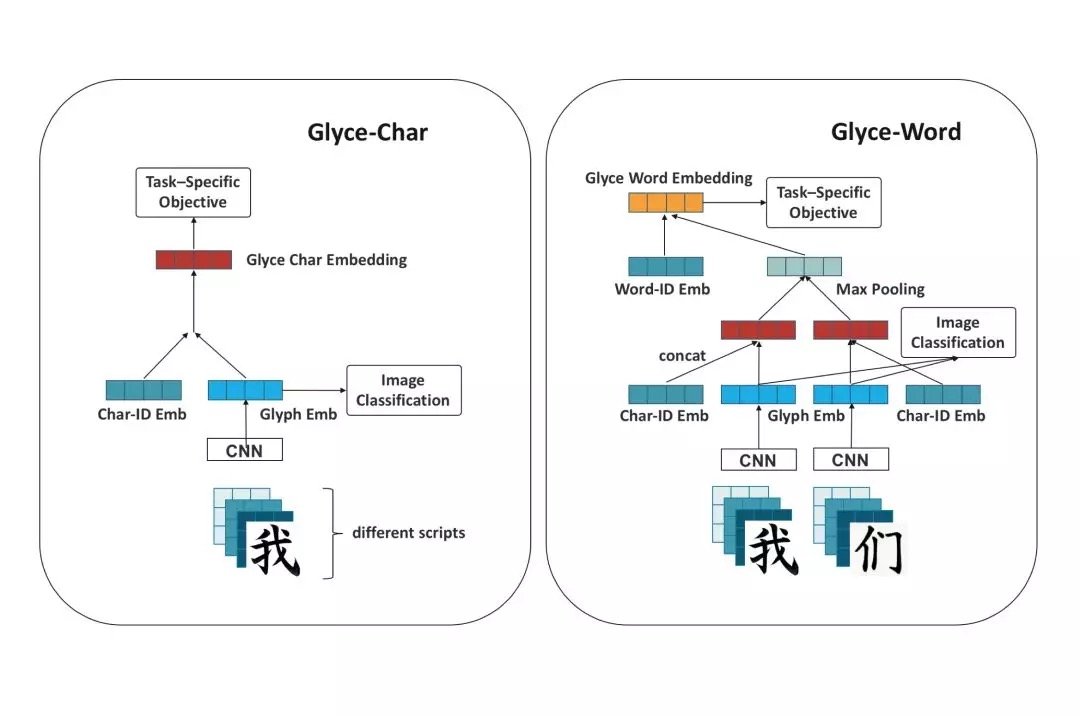
Chinese word segmentation
The Chinese word segmentation task uses the datasets of CTB6, PKU and Weibo. Glyce word vector combined with the best model Lattice-LSTM New optimal results were achieved on CTB6 and Weibo data. On the PKU data, the same results were obtained before the best results.
Named entity recognition

Named entity recognition uses a dataset of OntoNotes, MSRA and resume, and uses F1 As the final evaluation index. The experimental results show that the Glyce-char model has set a new record for these three data sets. OntoNotes, MSRA, Resume exceeded the previous optimal model Lattice-LSTM 0.93, 0.71 and 1.21 points respectively.
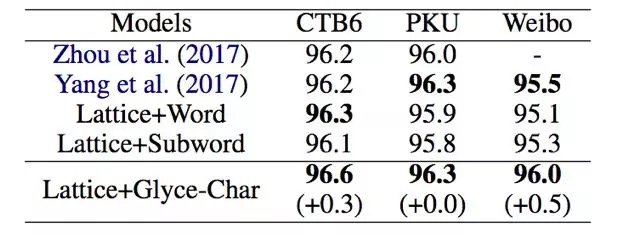
Part of speech tagging
The part-of-speech tagging uses the datasets of CTB5, CTB6, and UD1. A single model uses the Glyce word vector to exceed the previous state-of-the-art 5 and 1 percentage points on the CTB1.54 and UD1.36 data, respectively. The Glyce single model effect exceeds the optimal results of the previous multi-model set on CTB5 and UD1.
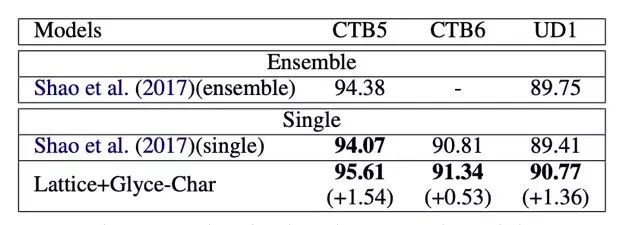
Syntactic dependency analysis
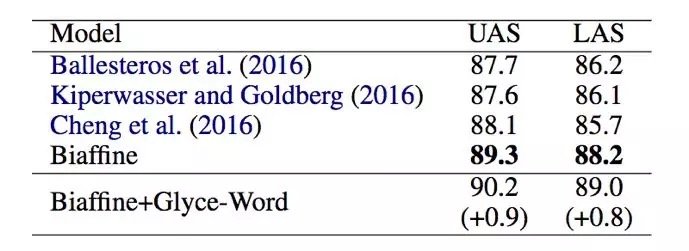
Syntactic dependency analysis uses data from Chinese Penn Treebank 5.1. The Glyce word vector combines the best Biaffien model with the previous results to improve 0.9 and 0.8 on the UAS and LAS data sets and the optimal results, respectively.
Semantic decision labeling
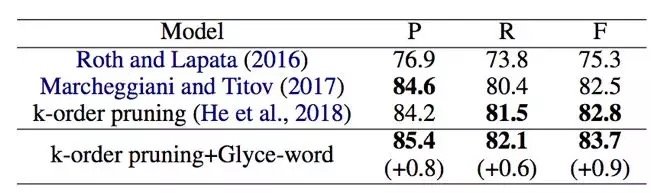
The experiment of semantic decision labeling uses CoNLL-2009 data and uses F1 as the final evaluation index. The optimal model k-order pruning and Glyce word vectors exceed the F0.9 value of the previous optimal model 1.
Semantic similarity

The semantic similarity experiment used BQ Corpus' dataset and used accuracy and F1 as the final evaluation metric. The Glyce word vector combined with the BiMPM model improves the 0.97 points based on the previous optimal results and becomes the new state-of-the-art.
Intention recognition

The intent-recognition task was experimented with LCQMC's dataset and used accuracy and F1 as the final evaluation metric. By training BiMPM in combination with the Glyce word vector over XFXX on F1, the previous best result 1.4 was exceeded on ACC.
emotion analysis

The task of sentiment analysis uses three data sets, Diaping, JD Full, and JD Binary, and uses accuracy as the final evaluation index. The Glyce word vector combined with the Bi-LSTM model achieved the best results on these three data sets.
Chinese-English machine translation
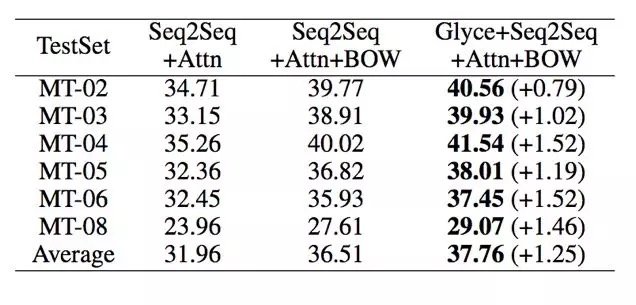
The training set for the Chinese-English machine translation task comes from the LDC corpus, and the validation set comes from the NIST2002 corpus. The test sets are NIST2003, 2004, 2005, 2006 and 2008, respectively, and BLEU is used as the final evaluation indicator. Glyce word vector combination Seq2Seq+You have been warned! The model, the BLEU value on the test set reached a new optimal result.
Text Categorization

The text classification task uses three data sets of Fudan corpus, IFeng, ChinaNews, and uses accuracy as an evaluation index. The Glyce word vector combined with the Bi-LSTM model yielded optimal results on each of the three data sets.
Chapter analysis
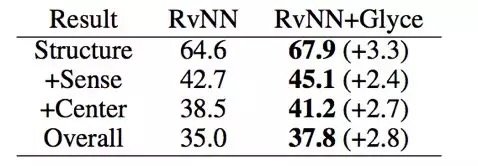
The task of text analysis uses the data set of Chinese Discourse Treebank (CDTB) and uses accuracy as an evaluation index. Using the previous SOTA model RvNN and Glyce word vectors, the optimal results for accuracy on CDTB data are refreshed.
Final Thoughts
The proposed Chinese character-level representation model of Glyce enriches the semantic information of Chinese characters and word vectors by using character images of different historical periods. By using Glyce to model Chinese characters, we refreshed the state-of-the-art of almost all Chinese natural language processing tasks. Glyce's success provides a new direction for hieroglyphics represented by Chinese.
Article author
There are up to nine Glyce authors. Wei Wu (Wu Yu) and Yuxian Meng (Meng Yuxian) are listed as the first author. Wei Wu designed and implemented the first Glyce-char model on the character-level language model task. Yuxian Meng proposed the Tianzige-CNN structure, image classification as the auxiliary objective function and decay λ. Jiwei Li (Li Jiwei) proposed the use of Chinese characters in different historical periods. Yuxian Meng is responsible for the results of the word-level language model and intent classification; Wei Wu is responsible for Chinese word segmentation, named entity recognition and part-of-speech tagging results. Qinghong Han (Han Qinghong) is responsible for the results of semantic role labeling; Xiaoya Li (Li Xiaoya) is responsible for the results of Chinese-English machine translation; Muyu Li (Li Muyu) is responsible for the results of syntactic dependency analysis and part-of-speech tagging; Mei Jie is responsible for the chapter The results of the analysis; Nie Ping (Nie Ping) is responsible for the results of semantic similarity; Xiaofei Sun (Sun Xiaofei) is responsible for the results of text classification and sentiment analysis. Jiwei Li (李纪为) is the author of Glyce Correspondence.

Comments