


首先,了解一下集成学习及 Boosting 算法
集成学习归属于机器学习,他是一种「训练思路」,并不是某种具体的方法或者算法。
现实生活中,大家都知道「人多力量大」,「3 个臭皮匠顶个诸葛亮」。而集成学习的核心思路就是「人多力量大」,它并没有创造出新的算法,而是把已有的算法进行结合,从而得到更好的效果。
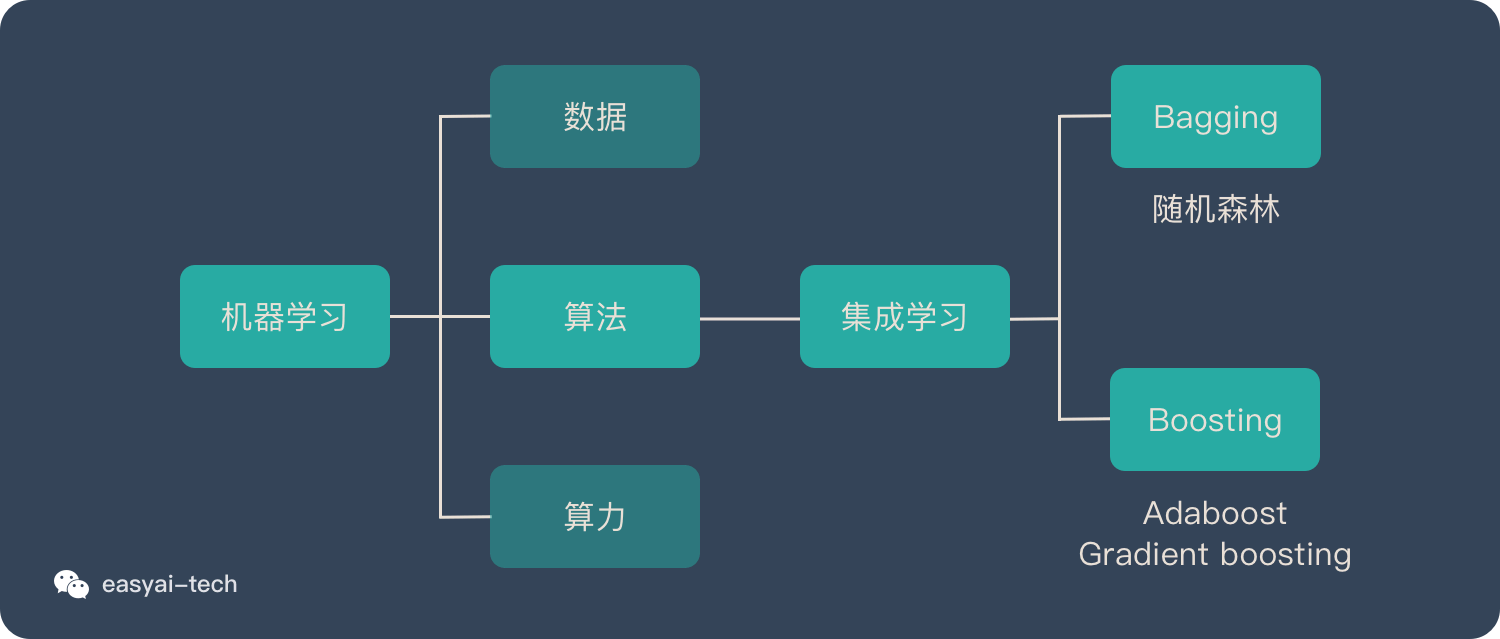
集成学习会挑选一些简单的基础模型进行组装,组装这些基础模型的思路主要有 2 种方法:
- bagging(bootstrap aggregating的缩写,也称作“套袋法”)
- boosting
今天所说的 Adaboost 算法就是 Boosting算法的其中一种。
下面再说一下Boosting算法:

Boosting 的核心思路是——挑选精英。
Boosting 和 bagging 最本质的差别在于他对基础模型不是一致对待的,而是经过不停的考验和筛选来挑选出「精英」,然后给精英更多的投票权,表现不好的基础模型则给较少的投票权,然后综合所有人的投票得到最终结果。
大部分情况下,经过 boosting 得到的结果偏差(bias)更小。
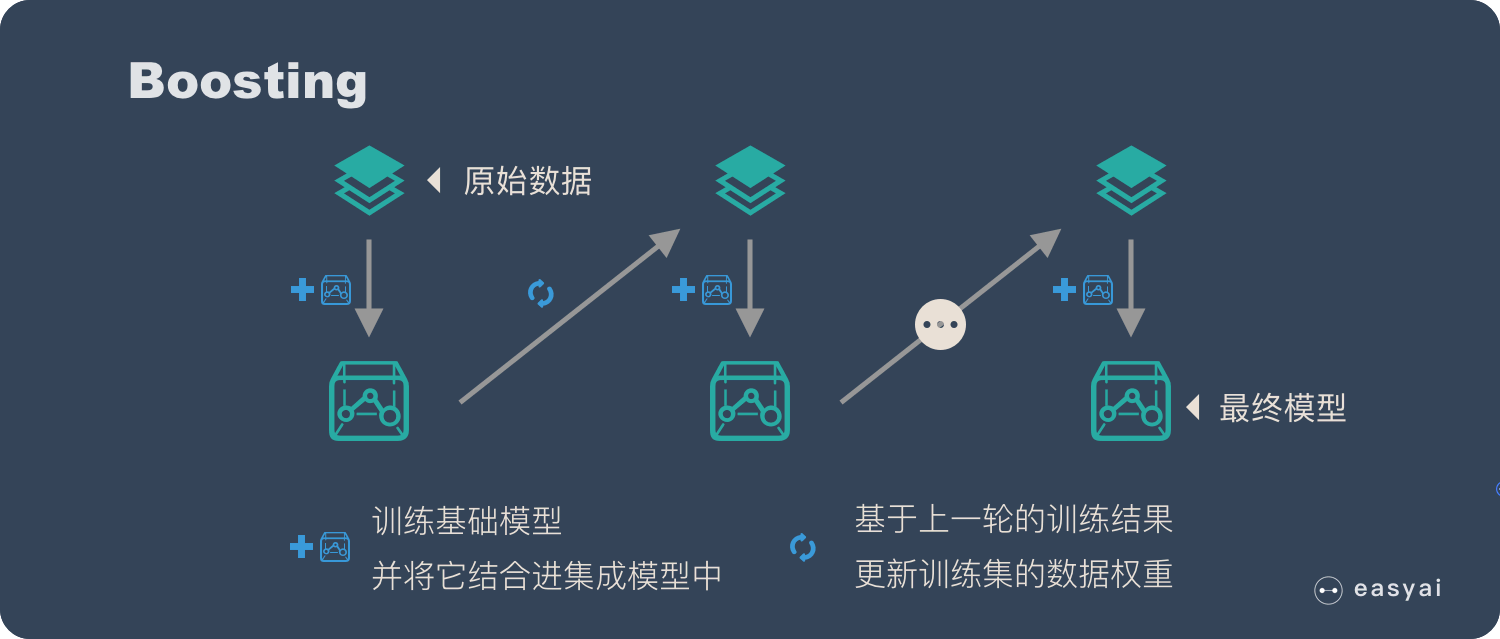
具体过程:
- 通过加法模型将基础模型进行线性的组合。
- 每一轮训练都提升那些错误率小的基础模型权重,同时减小错误率高的模型权重。
- 在每一轮改变训练数据的权值或概率分布,通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
想要详细了解集成算法或bagging算法,可以看看这篇文章《一文看懂集成学习(详解 bagging、boosting 以及他们的 4 点区别)》
什么是 AdaBoost 算法?
Boosting是一种集合技术,试图从许多弱分类器中创建一个强分类器。这是通过从训练数据构建模型,然后创建第二个模型来尝试从第一个模型中纠正错误来完成的。添加模型直到完美预测训练集或添加最大数量的模型。
AdaBoost是第一个为二进制分类开发的真正成功的增强算法。这是理解助力的最佳起点。现代助推方法建立在AdaBoost上,最着名的是随机梯度增强机。
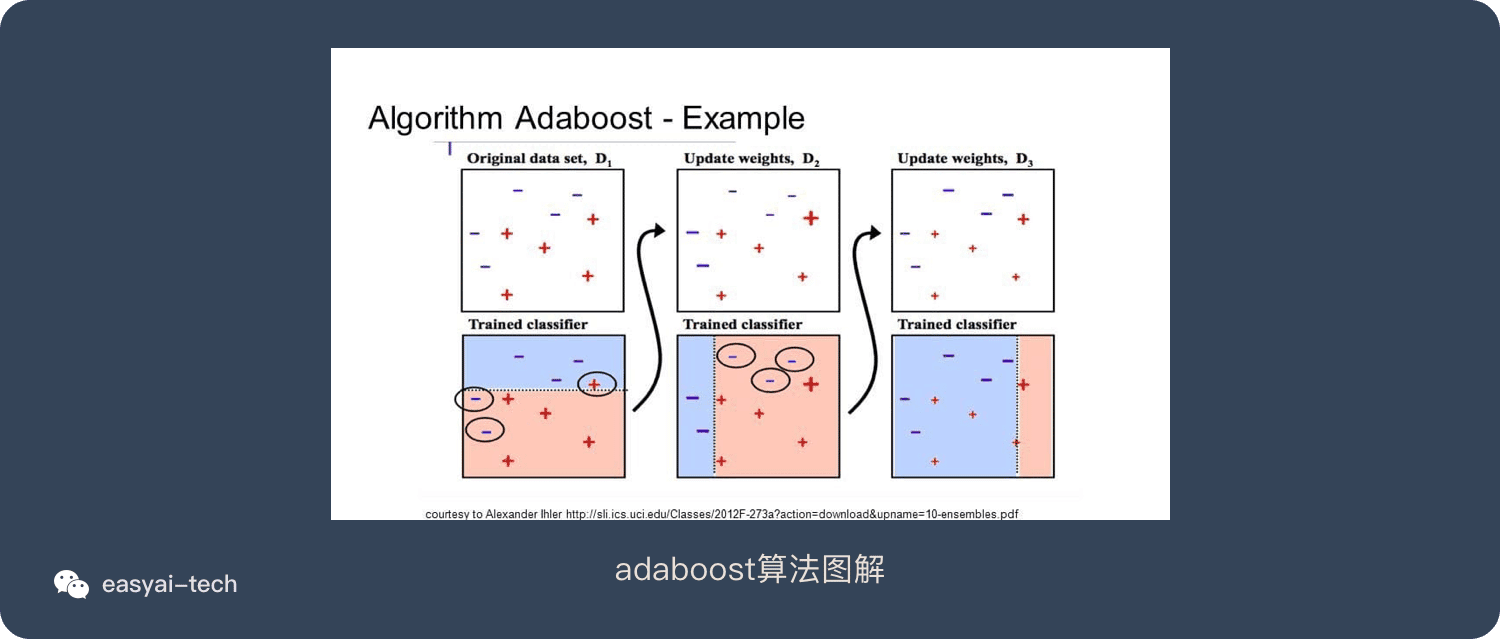
AdaBoost用于短决策树。在创建第一个树之后,每个训练实例上的树的性能用于加权创建的下一个树应该关注每个训练实例的注意力。难以预测的训练数据被赋予更多权重,而易于预测的实例被赋予更少的权重。模型一个接一个地顺序创建,每个模型更新训练实例上的权重,这些权重影响序列中下一个树所执行的学习。构建完所有树之后,将对新数据进行预测,并根据训练数据的准确性对每棵树的性能进行加权。
因为通过算法如此关注纠正错误,所以必须删除带有异常值的干净数据。
Adaboost 的 7 个优缺点

AdaBoost算法优点:
- 很好的利用了弱分类器进行级联;
- 可以将不同的分类算法作为弱分类器;
- AdaBoost具有很高的精度;
- 相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重;
Adaboost算法缺点:
- AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定;
- 数据不平衡导致分类精度下降;
- 训练比较耗时,每次重新选择当前分类器最好切分点;
百度百科和维基百科
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
AdaBoost是Adaptive Boosting的缩写,是由Yoav Freund和Robert Schapire制作的机器学习 元算法,他们因其工作而获得2003年哥德尔奖。它可以与许多其他类型的学习算法结合使用,以提高性能。其他学习算法(“弱学习者”)的输出被组合成加权和,该加权和表示提升分类器的最终输出。
AdaBoost在某种意义上是适应性的,即随后的弱学习者被调整为支持那些被先前分类器错误分类的实例。AdaBoost对噪声数据和异常值敏感。在某些问题中,它可能比其他学习算法更不容易受到过度拟合问题的影响。个体学习者可能很弱,但只要每个学习者的表现略好于随机猜测,最终的模型就可以证明可以融合到强大的学习者身上。