


我们经常听说海量数据是建立成功的机器学习项目的关键。
他是一个主要问题:许多组织不会有你需要的数据。
如果没有最基本的原材料,我们如何制作和验证机器学习理念?当资源稀少时,我们如何才能有效地获取和创建数据价值?
在我的工作场所,我们为客户生产了许多功能原型。因此,我经常需要让Small Data走很长的路。在本文中,我将分享7个提示,以便在使用小型数据集进行原型设计时改善结果。


1:意识到你的模型不会很好地概括。
这应该是第一项业务。你正在构建一个模型,其知识基于宇宙的一小部分,而且应该是唯一可以预期运行良好的地方或情况。
如果您正在构建基于室内照片选择的计算机视觉原型,请不要期望它在户外运行良好。如果你有一个基于聊天室戏弄的语言模型,不要指望它适用于幻想小说。
确保您的经理或客户了解这一点。这样,每个人都可以对模型应该提供的结果的实际期望保持一致。它还创造了一个机会,可以提出有用的新KPI来量化原型范围内外的模型性能。


2:构建良好的数据基础架构。
在许多情况下,客户端将不具备您需要的数据,并且公共数据将不是一种选择。如果您的原型的一部分需要收集和标记新数据,请确保您的基础设施创建尽可能少的摩擦力。
您需要确保数据标签非常简单,因此对于非技术人员来说也是平易近人的。我们已经开始使用Prodigy,我认为它是一个很好的工具:可访问和可扩展。根据项目的大小,您可能还需要设置自动数据摄取,这可以接收新数据并自动将其提供给标签系统。
如果快速简便地将新数据导入系统,您将获得更多数据。


3:做一些数据扩充。
您通常可以通过扩充您拥有的数据来扩展数据集。它是关于对不应显着改变模型输出的数据进行轻微更改。例如,猫的图像仍然是猫的图像,如果它旋转40度。
在大多数情况下,增强技术允许您生成更多“半独特”数据点来训练模型。作为开始,您可以尝试在数据中添加少量高斯噪声。
对于计算机视觉,有很多简洁的方法可以增强您的图像。我对Albumentations库有积极的经验,它可以在保持标签不受伤害的同时进行许多有用的图像转换。


许多人发现有用的另一种增强技术是Mixup。这种技术实际上需要两个输入图像,将它们混合在一起并组合它们的标签。

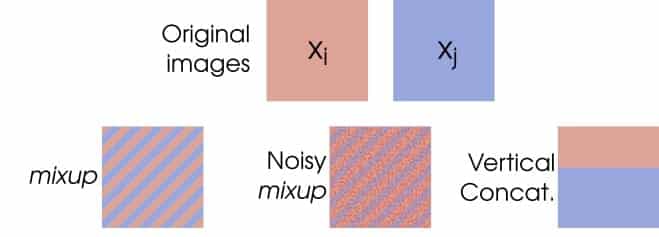
在扩充其他输入数据类型时,需要考虑哪些转换会改变标签,哪些不会改变。

4:生成一些合成数据。
如果您已经用尽了增加实际数据的选项,那么您可以开始考虑创建一些虚假数据。生成合成数据也可以是覆盖真实数据集所不具备的一些边缘情况的好方法。
例如,许多用于机器人的强化学习系统(如OpenAI的Dactyl)在部署到真实机器人之前在模拟3D环境中进行训练。对于图像识别系统,您可以类似地构建可为您提供数千个新数据点的3D场景。


创建合成数据的方法有很多种。在Kanda,我们正在开发一种基于转盘的解决方案,以创建用于对象检测的数据。如果您的数据要求非常高,则可以考虑使用Generative Adverserial Networks创建合成数据。请注意,GAN因难以训练而臭名昭着,因此请确保它首先值得。

有时您可以结合使用方法:Apple有一种非常聪明的方法,可以使用GAN处理3D建模面部的图像,使其看起来更逼真。如果你有时间,扩展数据集的真棒技术。

5.小心幸运的分裂。
在训练机器学习模型时,按照某种比例将数据集随机分成训练集和测试集是很常见的。通常,这很好。但是,在处理小型数据集时,由于培训示例数量较少,因此噪音风险很高。
在这种情况下,您可能会意外地获得幸运分割:特定数据集分割您的模型将在其中执行并且非常适合于测试集。但实际上,这可能只是因为测试集(巧合)不包含任何困难的例子。
在这种情况下,k-fold交叉验证是更好的选择。基本上,您将数据集拆分为k个 “折叠”并为每个k训练一个新模型,其中一个折叠用于测试集,其余用于训练。这可以控制您看到的测试性能不仅仅是由于幸运(或不幸)拆分。

6.使用转学习。
如果您正在使用某种标准化的数据格式,如文本,图像,视频或声音,您可以利用其他人通过转移学习将这些领域的所有先前工作。这就像站在巨人的肩膀上。
当您进行转学习时,您会选择其他人建立的模型(通常,“其他人”是Google,Facebook或主要大学)并根据您的特定需求对其进行微调。
转学习是有效的,因为与语言,图像或声音有关的大多数任务都有许多共同特征。对于计算机视觉,它可以是检测某些类型的形状,颜色或图案。
最近,我为具有高精度要求的客户开发了一个物体检测原型。通过微调已经在Google的Open Images v4数据集(大约900万张标记图像!)上训练过的MobileNet单发探测器,我能够极大地加速开发。经过一天的训练,我能够使用~1500标记的图像生成相当稳健的物体检测模型,其测试mAP为0.85。


7.尝试一群“弱学习者”。
有时,您只需面对这样一个事实,即您没有足够的数据来做任何花哨的事情。幸运的是,有许多传统的机器学习算法可以归结为对数据集大小不太敏感。
类似的算法 支持向量机 当数据集很小且数据点的维数很高时,这是一个很好的选择。
不幸的是,这些算法并不总是像最先进的方法那样准确。这就是为什么它们可以被称为“弱学习者”,至少与高度参数化的神经网络相比。
提高性能的一种方法是将这些“弱学习者”(这可能是一组支持向量机或决策树)组合在一起,以便它们“协同工作”以产生预测。这就是Ensemble Learning的意义所在。
本文转自towardsdatascience,原文地址