


背景
本文是关于产品经理如何将机器学习融入其产品的大量研究(参见下文其他文章)的一部分,由Brian Polidori和我自己在加州大学伯克利分校的MBA学习,在Vince Law的帮助下担任我们的指导老师。
该研究旨在了解产品经理如何设计,规划和构建支持ML的产品。为了达到这种理解,我们采访了各个技术公司的15位产品开发专家。在代表的15家公司中,14家公司的市值超过10亿美元,11家公开上市,6家是B2C,9家是B2B。
产品经理指导ML系列:


数据战略原则
启用机器学习(ML)产品具有持续的收集,清理和分析数据循环,以便输入ML模型。这种重复循环是ML算法的动力,并使ML产品能够为用户提供有用的见解。

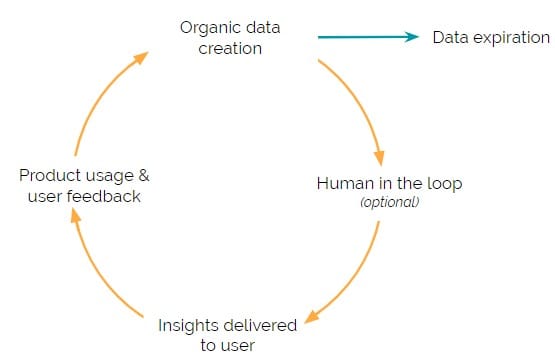
循环中的每一步都是一个独特的挑战。因此,我们通过框架和示例深入探讨了每个数据战略步骤,突出了其中一些独特的挑战。
有机数据创建
在商业领域,公司增长通常在有机和无机增长之间分解。有机增长是指公司自身业务活动带来的增长,而无机增长则来自并购。这个相同的概念可以应用于数据创建过程。
有机数据创建是指将数据(即用于通知ML模型的数据)创建为产品本身的副产品。无机数据创建是指从第三方获取(购买或免费访问)数据。所有最大的技术公司都在有机数据创建战略下运营。


Facebook知道谁建议你作为可能的朋友联系,因为你已经确认了你与其他类似的人的友谊。由于您过去的所有购买和浏览历史记录,亚马逊都知道您可能购买的其他产品。而Netflix知道接下来会推荐哪个节目,因为你看过去的节目。
一个值得注意的例外是公司刚开始时。公司可能需要无机地获取数据以构建初始ML模型,并且随着时间的推移使用该ML模型来创建必要的网络效应以开始有机数据创建过程。
要点(有机数据创建的四大好处):
- 经济高效 – ML模型需要大量数据才能进行培训,这些数据需要不断更新和刷新(参见下面的数据过期部分)。
- 代表性数据 - 有机数据创建可能包含代表您特定用户的数据,因为它实际上是由您的用户创建的。
- 竞争优势 - 作为一种天然的副产品,有机数据是专有的,可以作为竞争对手无法复制的竞争优势。
- 网络效果 - 有机数据创建可以增加网络效应的功能,因为随着用户的增加,数据也会增加,从而导致模型的改进。
人的反馈
就其本质而言,ML能够通过接收反馈来“学习”如何最佳地执行任务 – 大量反馈。此反馈主要有两种形式:
- 用户生成的反馈
- 手动人在循环审查


用户生成的反馈
用户生成的反馈是有效的数据创建。对于许多用例,用户生成的反馈相对容易捕获。例如,我们的一位受访者向我们提供了以下示例 – 这通常适用于所有搜索用例。
当用户在该公司的网站搜索栏中键入查询并点击输入时 – 显示20个结果。然后,用户快速扫描摘要文本,并且(很可能)点击其中一个。用户是从列表中选择的用户 – 这是关键。虽然这是相当明显的,但重要的是要详细说明并明确界定其重要性。
世界上唯一知道所呈现的20个结果中哪一个与用户最相关的人是实际用户。其他任何人都会猜测。因此,用户不仅可以满足自己的需求,还可以使用最准确的数据帮助训练ML模型。
因此,产品内用户反馈是您的ML模型可以获得的最有价值的反馈类型。此外,它不需要您雇用人员(不像下面讨论的人在环中),并且能够随着您的产品规模扩展。
有时,捕获用户反馈更加困难,并且必须将其他元素添加到用例中。添加这些附加元素的关键是以一种改善用户体验并确保部分采用的方式构建反馈渠道。


例如,当LinkedIn开始扩展它的InMail消息服务时,它决定引入两个回复选项。当招聘人员向您伸出援手时,LinkedIn会提供两个回复,“是”或“不,谢谢。”这是一个简单的解决方案,不仅通过让用户更快地改善用户体验,而且还向LinkedIn提供高度结构化的用户反馈意见可以用来训练其ML模型。随着时间的推移,LinkedIn推出了更多支持ML的产品,例如Smart Reply,它们受益于相同的产品内反馈机制。
关键点
- 在您的产品中创建结构化的反馈点,用户可以亲自激励他们选择提供反馈(Facebook照片标记,LinkedIn招聘人员回复)。
- 从本质上讲,单个用户的操作是ML模型可以为该特定用户接收的最准确的数据。
- 利用用户生成的反馈来增强ML模型,并在用户和ML准确度之间创建强化网络效果。
人在循环中
人与人之间的反馈是指您向一个人付费查看特定用例或数据集并提供他们受过教育的意见(例如,标签,是/否等)。尽管我们的受访者表示大多数公司可能会聘请第三方公司或创建内部团队,但您也可以将这种人在循环过程视为机械特克。
考虑到人类在循环反馈的不可扩展性,我们惊讶地发现超过一半的受访者表示他们的公司目前正在使用或计划使用人在环来为他们的ML模型提供结构化反馈。
为了将这个概念变为现实,让我们来看一个例子。
Quora是一个问答网站,由用户社区提问,回答和组织问题。排序通过平台上的所有噪声,Quora的允许用户给予好评的答案,帮助质量反应上升到顶部。


Quora注意到一些内容会收到很多内容,但经过审核,质量会低于标准,并已转变为“clickbait”内容。因此,为了增强upvote功能,Quora还决定采用人在环的反馈。Quora现在将一小部分问题和答案发送给已根据Quora标准进行培训的人(下面将详细介绍),以数字级评估饲料质量,以便将其输入ML模型。
从本质上讲,人在回路反馈是一种手动过程,因此非常昂贵。由于与人在环相关的成本过高,只有大公司似乎在广泛使用它来提供反馈。事实上,一些受访者指出,与人在环节相关的成本帮助公司围绕业务创造了“护城河”。例如,Facebook被认为拥有超过3,000名团队,致力于标签和内容审核。
当我们分析我们的受访者使用人在环的用例时,我们发现了几个首要原因。
- 用例没有绝对(即普遍真实的)量化指标来衡量绩效。因此,人类评论者是质量的最高标准,需要基于细微差别规则的主观决策。
上面的Quora示例说明了这一点。对于特定帖子,Quora用于衡量ML结果成功的参与度量可能很高,但人类解释质量(相对于规定的规则)较低。
- 如果ML模型不正确并且人类有能力在个体基础上确定某些事物是否正确,则存在显着的下行风险。
例如,如果社交网络没有正确执行内容审核,则存在重大的公共关系风险。提供规则的人可以合理地确定一条内容是否遵守或违反这些规则。
规则分类
受访者提出的关于人在循环的一个问题是难以创建指导原则,用于指导审阅者进行人工检查。指导原则不仅要具体到足以限制审稿人必须做出主观决定的“灰色”区域的数量,而且还要足够简单以便审阅者能够有效地执行任务。许多受访者提到他们公司的指导原则受到激烈争论并不断变化。
关键点
- 有时,用户生成的反馈不足以满足产品的目标,需要通过人在循环反馈来增强
- 人在环评估者花费了大量资金,有效设置这种人工审核的过程成本更高。但是,一旦这些程序根深蒂固地进入产品流程,它们就可以带来竞争优势
- 为人类审稿人创建规则分类法很困难。应该认真考虑确定标签规则以延长数据到期日期(有关更多详细信息,请参阅数据到期部分)。

数据到期
在我们采访的15人中,有11人提到了数据及时性的重要性。有些人提到了特定的法规或合同要求,迫使他们在60-90天后清除用户特定的数据。而其他人则表示旧数据不太可能提供信息(参见Reddit的排名算法)或提高预测价值。这种数据的及时性似乎不仅适用于用户生成的数据,而且适用于人在环评估的一些实例。
例如,Facebook试图在其平台上维护有关小型企业的最新信息(例如,网站,小时,电话号码等)。除了让这些小企业拥有其Facebook页面的所有权之外,Facebook还使用人在回顾的审阅者来检查一小部分业务页面,并查看数据是否是最新的。
但是,在审核人员确认小企业的数据是最新的之后,数据仍然是最新的概率开始下降。根据经验,我们听说在审查后约6个月,数据同样可能是陈旧的,因为它是最新的 – 但是,时间范围将根据具体的用例而有很大差异。
在旧数据变得陈旧且无关紧要之前,公司一直在努力获取新数据。这是公司应该围绕有机数据创建构建产品的另一个原因。
关键点
- 一旦创建了数据,它在ML模型中的有用性就开始下降,对于某些用例,这种数据衰减会在数天到数周内发生。
- 由于数据的有用性短,公司应该专注于有机数据创建,以便不断将新数据引入系统。
本文转自medium,原文地址