

背景
本文是关于产品经理如何将机器学习融入其产品的大量研究(参见下文其他文章)的一部分,由Brian Polidori和我自己在加州大学伯克利分校的MBA学习,在Vince Law的帮助下担任我们的指导老师。
该研究旨在了解产品经理如何设计,规划和构建支持机器学习(ML)的产品。为了达到这种理解,我们采访了各个技术公司的15位产品开发专家。在代表的15家公司中,14家公司的市值超过10亿美元,11家公开上市,6家是B2C,9家是B2B。
产品经理指导ML系列:

如何管理机器学习模型
产品经理需要在构建支持机器学习(ML)的产品时进行权衡和考虑。不同的产品用例需要不同的ML模型。因此,学习如何管理ML模型的核心原则是关键的产品经理技能集。
平衡精确度与召回率
每个ML模型在某些时候都是错误的。因此,在构建支持ML的产品时,您需要考虑针对特定用例的误报和漏报之间的正确平衡。
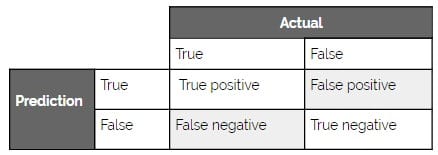
考虑这种平衡的另一种方法是精确与召回。精确度是检索到的实例中真阳性的百分比,而召回是预测的阳性数量与真阳性总数的比值。这种关系称为平衡的原因是精确度和召回率是相对负相关的(当其他条件相同时)。
虽然只有少数受访者使用精确与召回术语提到了这种平衡,但很大一部分提到了在特定用例中找到平衡的重要性。Google相册就是一个很好的例子。
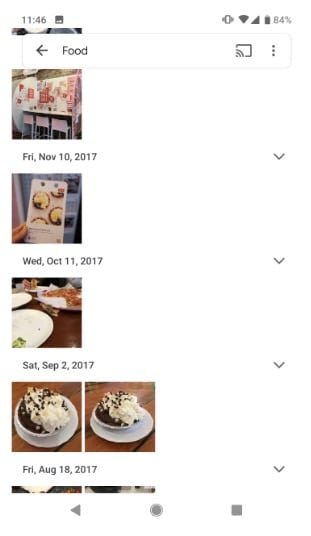
当用户在Google照片中输入搜索内容时,他们希望减少图片数量,以便更容易找到他们想要的内容。因此,目标是降低噪音,因此,误报的成本有限(因为替代方案正在查看所有照片)但是假阴性的成本很高(因为他们想要的东西可能不会浮出水面)。因此,Google Photos优先考虑高精度的高召回率。如图所示,Google照片通常包含与搜索无关的图像。
在精确与召回频谱的另一端,我们的一位受访者举了一个例子,他们的公司(社交网络)专注于高精度。用例是确定如何对用户个人订阅源中显示的内容进行排名和推荐。在进行一些实验后,该公司发现如果推荐的内容与用户不相关,则用户搅动的可能性更高。
虽然这个结果看起来很明显,但细微差别在于用户使用移动设备时流失率最高。由于房地产有限,推荐的内容将占据屏幕的很大一部分,因此,如果推荐的内容不是非常精确,用户可能会流失。
根据我们的访谈和研究,我们创建了以下一般指导原则,作为如何考虑优先顺序的起点。
关键点
何时优先考虑召回超过精确度:
- 异常检测
- 合规
- 欺诈识别
何时优先考虑精确度而不是召回:
- 有限的空间(例如,移动设备,小部分)
- 建议
- 内容审核
准确度阈值
机器学习策略的核心部分取决于实现产品市场匹配所需的最低精度水平(模型正确预测的预测分数 – 参见召回和精确部分)。产品市场契合的良好代理是价值创造,其中创造的价值越多(对公司和用户而言),产品市场越适合。因此,问题就变成了,不同准确度和价值创造之间的关系是什么?
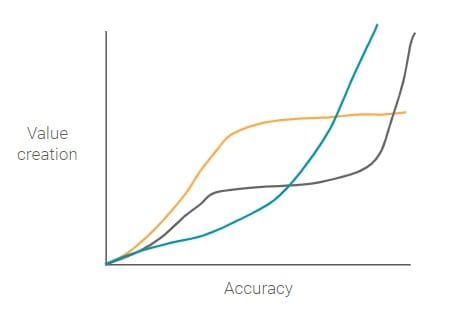
这个问题的答案取决于具体用例的细节。那么,让我们来看两个例子。
自动驾驶汽车
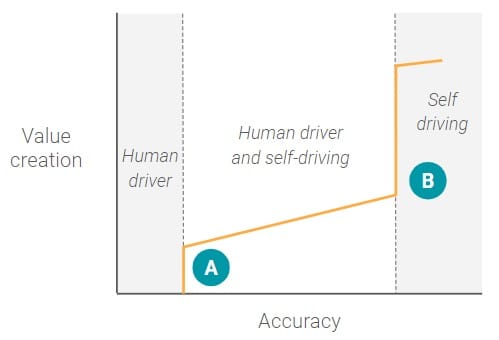
最初,当自动驾驶汽车ML模型具有非常低的准确度时,由于人类驾驶员根本不能依赖于系统,因此创建零值(或甚至可能是负值)。在某一点(A),有一个逐步的功能,其中ML模型具有足够高的精确度,人类驾驶员可以在一些高度受限的环境中开始依赖系统,例如驾驶更均匀的高速公路。一旦达到此准确度级别,就会为该特定用例创建重要的价值(或产品市场适合度)。
然而,在A点之后,系统达到一个轻微的平台,其中精度水平的增加不对应于价值创造的相应增加,因为人类驾驶员仍然需要在一部分时间内参与。例如,汽车可能能够在一段时间内停放自己,但无法处理高密度的城市街道,或者确切地知道街道一侧的哪个地方让您失望。从本质上讲,ML模型还没有达到下一个用例的最低精度阈值 – 完全自驱动能力。
一旦ML模型达到完全自动驾驶的最低精度阈值,就会有一种范例转变为一种全新的用例,根本不涉及人类驾驶员。此时,产品团队可以开始考虑从根本上改变新用例的产品,例如添加娱乐控制台或创建车队。
Google相册搜索
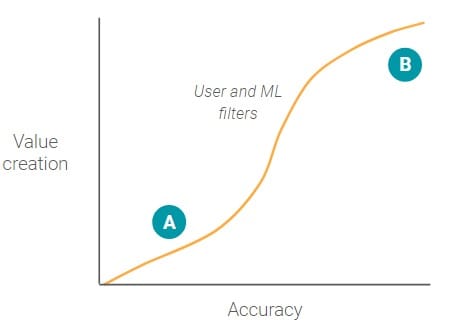
与自动驾驶准确度值创建图形相比,Google照片图像搜索没有大的逐步功能。
当用户搜索特定照片时,用户键入单词以创建过滤器并减少需要查看的照片的总数。即使精度很低,即A点,ML模型仍然可以通过减少用户需要查看的照片总数来创造价值(假设ML模型具有较低的假阴性)。
随着准确性不断提高,随着越来越多的无关照片被过滤掉,价值创造的速度也在不断增加。在B点周围的某个点,随着准确性的不断提高,价值创造的边际收益递减。这是因为过滤器已经消除了大多数其他照片,用户可以快速轻松地查看所有照片结果,而无需滚动。
每个用例都将具有不同的准确度值创建图。因此,您应仔细考虑特定用例的特征,以确定1)是否存在关键准确度阈值,以及2)在这些准确度阈值之上需要哪些产品更改。
关于准确度阈值的关键问题
- 我的用例需要的最低准确度阈值是多少?
- 机器学习是用来增加手动过程吗?
- 随着人为参与的百分比降低,产品的功能要求如何变化?
- 在什么时候你能够完全从过程中移除人类?
- 如果精度达到一定水平,整个用例会发生变化吗?
- 价值创造是否以零为界?或者,换句话说,是否可以创建的最大值减少到零,例如将欺诈减少到零?
探索与剥削

一些机器学习问题的主要挑战之一是探索和开发之间的平衡。这个问题通常用称为多臂强盗的赌场场景来说明。想象一下赌徒在一排“单臂强盗”老虎机。赌徒可以选择测试多台机器以寻找具有最高支付(探索)的机器。或者赌徒可以选择一台机器并尝试建立一个最佳策略来赢得该机器(利用)。
最大化方面的定义(通常是点击率等指标):
- 探索 - 在某种程度上随机测试各种选项以试图找到全局最大值。
- 利用 - 优化当地最大的现有问题空间。
对于支持ML的推荐产品,这种权衡是常见的。例如,Nordstroms的购物应用程序的屏幕空间有限,无法向用户推广产品。如果它向用户显示用户从未查看过的新产品或品牌,Nordstrom正在探索该用户是否有更高的全局最大值。这将为Nordstrom提供有关用户之前未知偏好的更多信息(并且可能发现漏报),但是有太多误报可能会对用户体验产生负面影响。
另一方面,Nordstrom以纯粹的剥削方式向用户展示他们看过或以前购买的产品和品牌。这种方法可以帮助Nordstroms仅根据用户已知的内容进行优化(真正的积极因素)。
这不是解决的机器学习问题; 我们采访过的许多公司都在不断优化和调整模型,以找到合适的平衡点。最可能的解决方案是使用探索和开发技术的ML模型。
关键点
- 如果您有假阴性,探索是学习的最佳方式,但过度探索可能会导致许多误报。
- 剥削是一种安全的方法,但它是限制性的,并且可能导致花费时间寻求不太理想的局部最大值。
本文转自medium,原文地址

Comments