


DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。
作为行业的标杆,DeepMind的动向一直是AI业界关注的热点。最近,这家世界最顶级的AI实验室似乎是把他们的重点放在了探索“关系”上面,6月份以来,接连发布了好几篇“带关系”的论文,比如:
- 关系归纳偏置(Relational inductive bias for physical construction in humans and machines)
- 关系深度强化学习(Relational Deep Reinforcement Learning)
- 关系RNN(Relational Recurrent Neural Networks)
论文比较多,但如果说有哪篇论文最值得看,那么一定选这篇——《关系归纳偏置、深度学习和图网络》。


这篇文章联合了DeepMind、谷歌大脑、MIT和爱丁堡大学的27名作者(其中22人来自DeepMind),用37页的篇幅,对关系归纳偏置和图网络(Graph network)进行了全面阐述。
DeepMind的研究科学家、大牛Oriol Vinyals颇为罕见的在Twitter上宣传了这项工作(他自己也是其中一位作者),并表示这份综述“pretty comprehensive”。


有很不少知名的AI学者也对这篇文章做了点评。
曾经在谷歌大脑实习,从事深度强化学习研究的Denny Britz说,他很高兴看到有人将图(Graph)的一阶逻辑和概率推理结合到一起,这个领域或许会迎来复兴。


芯片公司Graphcore的创始人Chris Gray评论说,如果这个方向继续下去并真的取得成果,那么将为AI开创一个比现如今的深度学习更加富有前景的基础。


康纳尔大学数学博士/MIT博士后Seth Stafford则认为,图神经网络(Graph NNs)可能解决图灵奖得主Judea Pearl指出的深度学习无法做因果推理的核心问题。

开辟一个比单独的深度学习更富有前景的方向
那么,这篇论文是关于什么的呢?DeepMind的观点和要点在这一段话里说得非常清楚:
这既是一篇意见书,也是一篇综述,还是一种统一。我们认为,如果AI要实现人类一样的能力,必须将组合泛化(combinatorial generalization)作为重中之重,而结构化的表示和计算是实现这一目标的关键。
正如生物学里先天因素和后天因素是共同发挥作用的,我们认为“人工构造”(hand-engineering)和“端到端”学习也不是只能从中选择其一,我们主张结合两者的优点,从它们的互补优势中受益。
在论文里,作者探讨了如何在深度学习结构(比如全连接层、卷积层和递归层)中,使用关系归纳偏置(relational inductive biases),促进对实体、对关系,以及对组成它们的规则进行学习。
他们提出了一个新的AI模块——图网络(graph network),是对以前各种对图进行操作的神经网络方法的推广和扩展。图网络具有强大的关系归纳偏置,为操纵结构化知识和生成结构化行为提供了一个直接的界面。
作者还讨论了图网络如何支持关系推理和组合泛化,为更复杂、可解释和灵活的推理模式打下基础。图灵奖得主Judea Pearl:深度学习的因果推理之殇
2018年初,承接NIPS 2017有关“深度学习炼金术”的辩论,深度学习又迎来了一位重要的批评者。
图灵奖得主、贝叶斯网络之父Judea Pearl,在ArXiv发布了他的论文《机器学习理论障碍与因果革命七大火花》,论述当前机器学习理论局限,并给出来自因果推理的7大启发。Pearl指出,当前的机器学习系统几乎完全以统计学或盲模型的方式运行,不能作为强AI的基础。他认为突破口在于“因果革命”,借鉴结构性的因果推理模型,能对自动化推理做出独特贡献。


在最近的一篇访谈中,Pearl更是直言,当前的深度学习不过只是“曲线拟合”(curve fitting)。“这听起来像是亵渎……但从数学的角度,无论你操纵数据的手段有多高明,从中读出来多少信息,你做的仍旧只是拟合一条曲线罢了。” DeepMind的提议:把传统的贝叶斯因果网络和知识图谱,与深度强化学习融合
如何解决这个问题?DeepMind认为,要从“图网络”入手。
大数医达创始人、CMU博士邓侃为我们解释了DeepMind这篇论文的研究背景。
邓侃博士介绍,机器学习界有三个主要学派,符号主义(Symbolicism)、连接主义(Connectionism)、行为主义(Actionism)。
符号主义的起源,注重研究知识表达和逻辑推理。经过几十年的研究,目前这一学派的主要成果,一个是贝叶斯因果网络,另一个是知识图谱。
贝叶斯因果网络的旗手是 Judea Pearl 教授,2011年的图灵奖获得者。但是据说 2017年 NIPS 学术会议上,老爷子演讲时,听众寥寥。2018年,老爷子出版了一本新书,“The Book of Why”,为因果网络辩护,同时批判深度学习缺乏严谨的逻辑推理过程。而知识图谱主要由搜索引擎公司,包括谷歌、微软、百度推动,目标是把搜索引擎,由关键词匹配,推进到语义匹配。
连接主义的起源是仿生学,用数学模型来模仿神经元。Marvin Minsky 教授因为对神经元研究的推动,获得了1969年图灵奖。把大量神经元拼装在一起,就形成了深度学习模型,深度学习的旗手是 Geoffrey Hinton 教授。深度学习模型最遭人诟病的缺陷,是不可解释。
行为主义把控制论引入机器学习,最著名的成果是强化学习。强化学习的旗手是 Richard Sutton 教授。近年来Google DeepMind 研究员,把传统强化学习,与深度学习融合,实现了 AlphaGo,战胜当今世界所有人类围棋高手。
DeepMind 前天发表的这篇论文,提议把传统的贝叶斯因果网络和知识图谱,与深度强化学习融合,并梳理了与这个主题相关的研究进展。DeepMind提出的“图网络”究竟是什么
在这里,有必要对说了这么多的“图网络”做一个比较详细的介绍。当然,你也可以跳过这一节,直接看后面的解读。
在《关系归纳偏置、深度学习和图网络》这篇论文里,作者详细解释了他们的“图网络”。图网络(GN)的框架定义了一类用于图形结构表示的关系推理的函数。GN 框架概括并扩展了各种的图神经网络、MPNN、以及 NLNN 方法,并支持从简单的构建块(building blocks)来构建复杂的结构。
GN 框架的主要计算单元是 GN block,即 “graph-to-graph” 模块,它将 graph 作为输入,对结构执行计算,并返回 graph 作为输出。如下面的 Box 3 所描述的,entity 由 graph 的节点(nodes),边的关系(relations)以及全局属性(global attributes)表示。

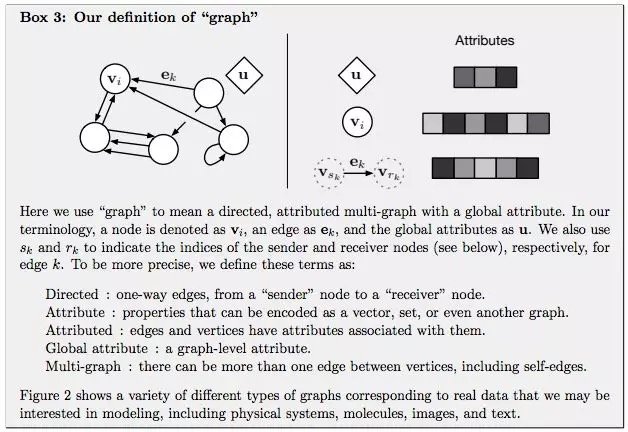
论文作者用 “graph” 表示具有全局属性的有向(directed)、有属性(attributed)的 multi-graph。一个节点(node)表示为Vi,一条边(edge)表示为ek,全局属性(global attributes)表示为u。sk和rk表示发送方(sender)和接收方(receiver)节点的指标(indices)。具体如下:
- Directed:单向,从 “sender” 节点指向 “receiver” 节点。
- Attribute:属性,可以编码为矢量(vector),集合(set),甚至另一个图(graph)
- Attributed:边和顶点具有与它们相关的属性
- Global attribute:graph-level 的属性
- Multi-graph:顶点之间有多个边
GN 框架的 block 的组织强调可定制性,并综合表示所需关系归纳偏置(inductive biases)的新架构。
用一个例子来更具体地解释 GN。考虑在任意引力场中预测一组橡胶球的运动,它们不是相互碰撞,而是有一个或多个弹簧将它们与其他球(或全部球)连接起来。我们将在下文的定义中引用这个运行示例,以说明图形表示和对其进行的计算。
“graph” 的定义
在我们的 GN 框架中,一个 graph 被定义为一个 3 元组的G=(u,V,E)。
u 表示一个全局属性;例如,u 可能代表重力场。

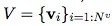
是节点集合(基数是Nv),其中每个Vi表示节点的属性。例如,V 可能表示每个球,带有位置、速度和质量这些属性。

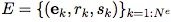
是边(基数是Ne)的集合,其中每个ek表示边的属性,rk是接收节点的 index,sk是发送节点的 index。例如,E 可以表示不同球之间存在的弹簧,以及它们对应的弹簧常数。
算法 1:一个完整的 GN block 的计算步骤


GN block 的内部结构
一个 GN block 包含三个 “update” 函数,以及三个 “aggregation” 函数:

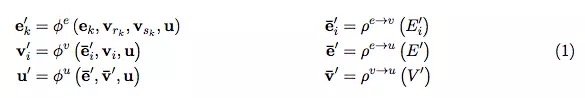
其中:

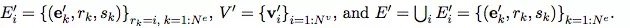


要把知识图谱和深度学习相结合,邓侃博士认为有几大难点。
1. 点向量:
知识图谱由点和边构成,点(node)用来表征实体(entity),实体又包含属性(attribute)和属性的值(value)。传统知识图谱中的实体,通常由概念符号构成,譬如自然语言的词汇。
传统知识图谱中的边,连接两个单点,也就是两个实体,边表达的是关系,关系的强弱,由权重表达,传统知识图谱的边的权重,通常是常数。
如果想把传统知识图谱与深度学习相融合,首先要做的是实现点的可微分化。用数值化的词向量来替代自然语言的词汇,是实现点的可微分化的有效方法,通常的做法是用语言模型来分析大量的文本,给每个词汇找到最贴合上下文语义的词向量。但在图谱中,传统的词向量的生成算法,不十分奏效,需要改造。
2. 超点:
前文说到,传统知识图谱中的边,连接两个单点,表达两个单点之间的关系。这个假定制约了图谱的表达能力,因为在很多场景下,多个单点组合在一起,才与其它单点或者单点组合,存在关系。我们把单点组合,称之为超点(hyper-node)。
问题是哪些单点组合在一起构成超点?人为的先验指定,当然是一个办法。从大量训练数据中,通过 dropout 或者 regulation 算法,自动学习出超点的构成,也是一个思路。
3. 超边:
传统的知识图谱中的边,表达了点与点之间的关系,关系的强弱由权重表达,通常权重是个常数。但在很多场景下,权重并非是常数。随着点的取值不同,边的权重也发生变化,而且很可能是非线性变化。
用非线性函数来表达图谱的边,称为超边(hyper-edge)。
深度学习模型可以用于模拟非线性函数。所以,知识图谱中每条边都是一个深度学习模型。模型的输入是若干个单点组成的超点,模型的输出是另一个超点。如果把每个深度学习模型,视为一棵树,根是输入,叶子是输出。那么鸟瞰整个知识图谱,实际上是深度学习模型的森林。
4. 路径:
训练知识图谱,包括训练点向量,超点、和超边的时候,一条训练数据往往是在图谱中行走的一条路径,通过拟合海量的路径,获得最贴切的点向量、超点和超边。
用拟合路径来训练图谱,存在的一个问题是,训练过程与过程结束后的评价,两者的脱节。打个比方,给你若干篇文章的提纲,以及相应的范文,让你学习如何写作文。拟合的过程,强调逐字逐句的模仿。但是评价文章的好坏,重点并不在于字句的亦步亦趋,而在于通篇文章的顺畅。
如何解决训练过程与最终评价的脱节?很有潜力的办法,是用强化学习。强化学习的精髓,在于把最终的评价,通过回溯和折现的方法,给路径过程中每一个中间状态,评估它的潜力。
但是强化学习面临的困难,在于中间状态的数量不可太多。当状态数量太多时,强化学习的训练过程,无法收敛。解决收敛问题的办法,是用一个深度学习模型,来估算所有状态的潜力值。换句话说,不需要估算所有状态的潜力值,而只需要训练一个模型的有限参数。
DeepMind 前天发表的这篇文章,提议把深度强化学习与知识图谱等相融合,并梳理了大量的相关研究。但是,论文并没有明确说明 DeepMind 偏向于哪一种具体方案。
或许,针对不同应用场景会有不同方案,并没有通用的最佳方案。图谱深度学习是下一个AI算法的热点?
许多重要的现实世界数据集都是以图或网络的形式出现,比如社交网络、知识图谱,万维网等等。 目前,已有越来越多的研究者开始关注神经网络模型对这种结构化数据集的处理。
结合DeepMind、谷歌大脑等发表的一系列的关于图深度学习的论文,是否预示“图深度学习”是下一个AI算法热点?
总之,先从这篇论文看起吧。
地址:https://arxiv.org/pdf/1806.01261.pdf
参考资料
本文转自公众号 新智元,原文地址