


你对世界了解多少很疯狂。您了解我们生活在3D环境中,物体移动,人们交谈,动物飞翔。世界上有大量的数据,其中大部分都很容易获取 – 困难的部分是开发能够分析和理解这些丰富数据的算法。生成模型是实现这一目标的最有前途的方法之一。生成模型有许多短期应用,但从长远来看,它们有可能学习数据集的自然特征,无论是类别,像素,音频样本还是完全不同的东西。
生成算法
您可以将生成算法分组到三个桶中的一个:
- 鉴于标签,他们预测相关的功能(朴素贝叶斯)
- 给定隐藏的表示,他们预测相关的特征(变分自动编码器,生成对抗网络)
- 鉴于一些功能,他们预测其余的(修复,插补)
在这篇文章中,我们将探索生成对抗网络(GAN)的一些基础知识!GAN具有令人难以置信的潜力,因为他们可以学习模仿任何数据分布。也就是说,GAN可以学习在任何领域创造类似于我们自己的世界:图像,音乐,语音。

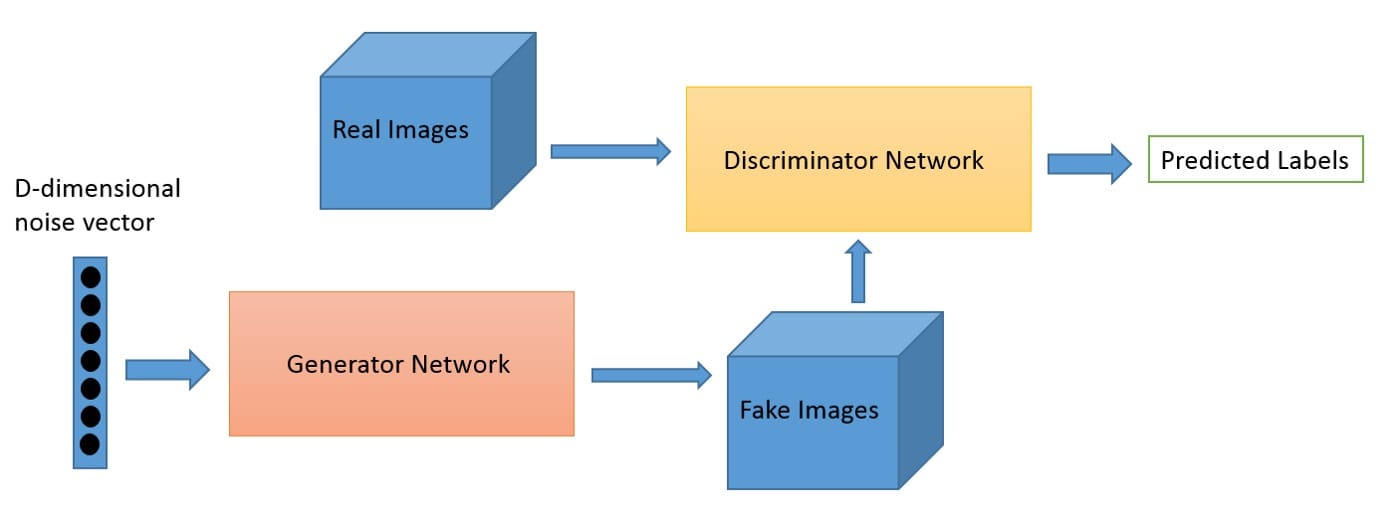
生成对抗网络(GAN)
“生成”部分
- 叫做发电机。
- 给定某个标签,尝试预测功能。
- EX:鉴于电子邮件被标记为垃圾邮件,预测(生成)电子邮件的文本。
- 生成模型学习各个类的分布。
“对抗性”部分
- 称为判别者。
- 鉴于这些功能,尝试预测标签。
- EX:根据电子邮件的文本,预测(区分)垃圾邮件或非垃圾邮件。
- 判别模型学习了类之间的界限。
GAN如何运作?
一个称为Generator的神经网络生成新的数据实例,而另一个神经网络Discriminator则评估它们的真实性。
您可以将GAN视为伪造者(发电机)和警察(Discriminator)之间的猫捉老鼠游戏。伪造者正在学习制造假钱,警察正在学习如何检测假钱。他们都在学习和提高。伪造者不断学习创造更好的假货,并且警察在检测它们时不断变得更好。最终的结果是,伪造者(发电机)现在接受了培训,可以创造出超现实的金钱!
让我们用MNIST手写数字数据集探索一个具体的例子:


我们将让Generator创建新的图像,如MNIST数据集中的图像,它取自现实世界。当从真实的MNIST数据集中显示实例时,Discriminator的目标是将它们识别为真实的。
同时,Generator正在创建传递给Discriminator的新图像。它是这样做的,希望它们也将被认为是真实的,即使它们是假的。Generator的目标是生成可通过的手写数字,以便在不被捕获的情况下进行说谎。Discriminator的目标是将来自Generator的图像分类为假的。

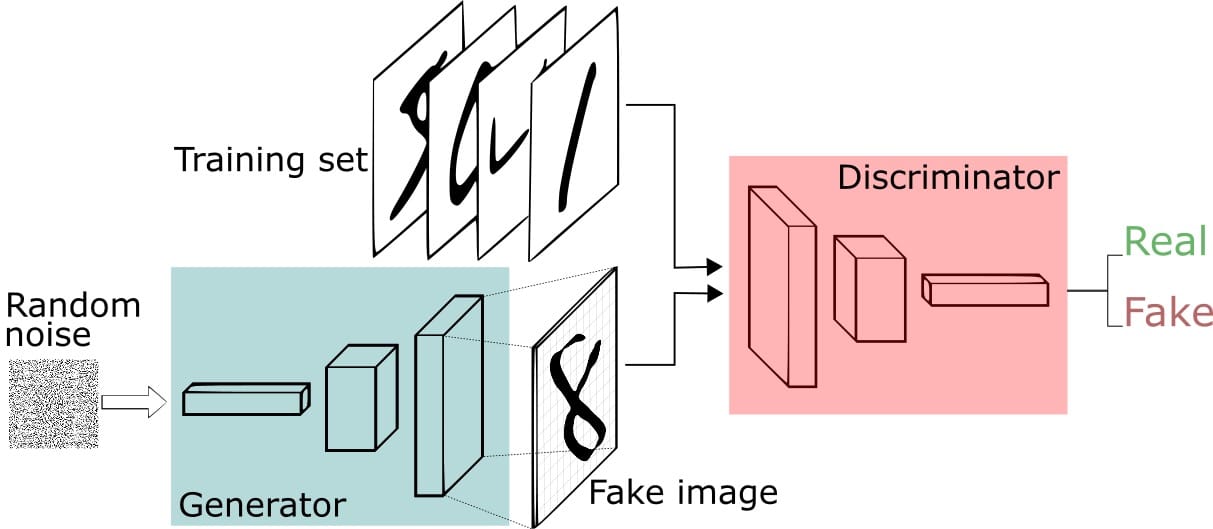
GAN步骤:
- 生成器接收随机数并返回图像。
- 将生成的图像与从实际数据集中获取的图像流一起馈送到鉴别器中。
- 鉴别器接收真实和假图像并返回概率,0到1之间的数字,1表示真实性的预测,0表示假。
两个反馈循环:
- 鉴别器处于反馈循环中,具有图像的基本事实(它们是真实的还是假的),我们知道。
- 发生器与Discriminator处于反馈循环中(Discriminator将其标记为真实或伪造,无论事实如何)。
培训GAN的技巧?
在开始训练发生器之前预先识别鉴别器将建立更清晰的梯度。
训练Discriminator时,保持Generator值不变。训练发生器时,保持Discriminator值不变。这使网络能够更好地了解它必须学习的梯度。
GAN被制定为两个网络之间的游戏,重要(并且很难!)保持它们的平衡。如果发电机或鉴别器太好,GAN可能很难学习。
GAN需要很长时间才能训练。在单个GPU上,GAN可能需要数小时,在单个CPU上,GAN可能需要数天。
GAN代码示例
足够的话。以下是由Erik Linder创建的Keras实施的GAN示例:
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build and compile the generator
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# The generator takes noise as input and generated imgs
z = Input(shape=(100,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The valid takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator) takes
# noise as input => generates images => determines validity
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (100,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half batch of images
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (half_batch, 100))
# Generate a half batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
valid_y = np.array([1] * batch_size)
# Train the generator
g_loss = self.combined.train_on_batch(noise, valid_y)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("gan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, save_interval=200)如何改善GAN?
GAN刚刚在2014年发明 – 它们非常新!GAN是一个很有前途的生成模型家族,因为与其他方法不同,它们可以生成非常干净和清晰的图像,并学习包含有关基础数据的有价值信息的权重。但是,如上所述,可能难以使Discriminator和Generator网络保持平衡。有很多正在进行的工作使GAN培训更加稳定。
除了生成漂亮的图片之外,还开发了一种利用GAN进行半监督学习的方法,该方法涉及鉴别器产生指示输入标签的附加输出。这种方法可以使用极少数标记示例在数据集上实现最前沿结果。例如,在MNIST上,通过完全连接的神经网络,每个类只有10个标记示例,实现了99.1%的准确度 – 这一结果非常接近使用所有60,000个标记示例的完全监督方法的最佳已知结果。这是非常有希望的,因为在实践中获得标记的示例可能非常昂贵。
结论
GAN仍然是如此新鲜 – 我很高兴看到他们去了哪里!不是吗?
本文转自towardsdatascience,原文地址