


机器学习全靠调参?这个思路已经过时了。
谷歌大脑团队发布了一项新研究:
只靠神经网络架构搜索出的网络,不训练,不调参,就能直接执行任务。
这样的网络叫做WANN,权重不可知神经网络。
它在MNIST数字分类任务上,未经训练和权重调整,就达到了92%的准确率,和训练后的线性分类器表现相当。
除了监督学习,WANN还能胜任许多强化学习任务。
团队成员之一的大佬David Ha,把成果发上了推特,已经获得了1300多赞:

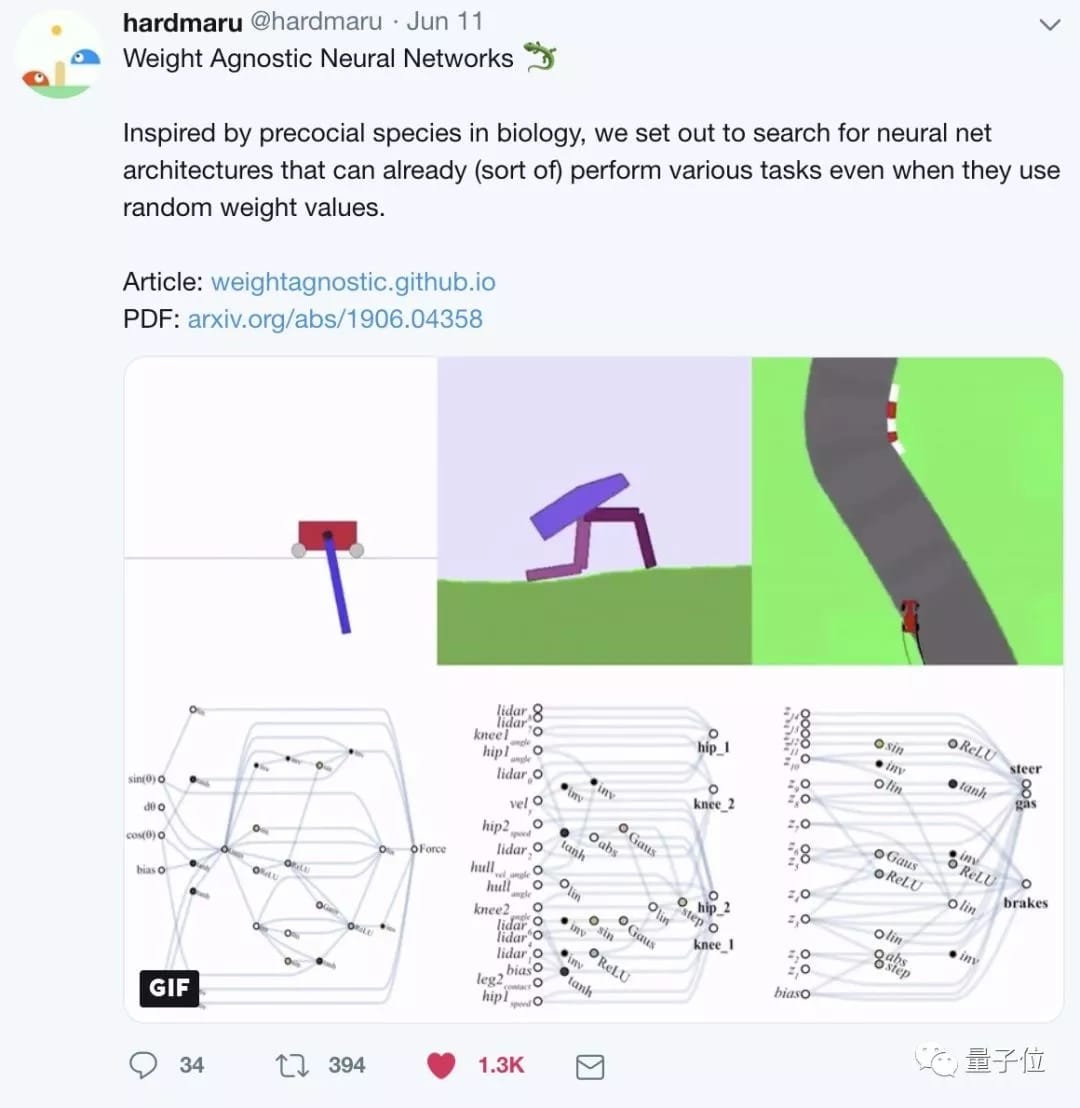
那么,先来看看效果吧。
效果
谷歌大脑用WANN处理了3种强化学习任务。
(给每一组神经元,共享同一个权重。)
第一项任务,Cart-Pole Swing-Up。

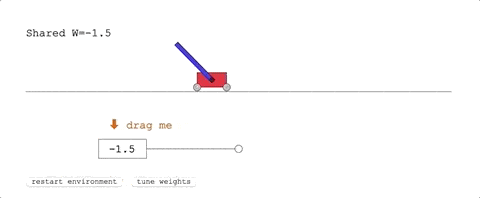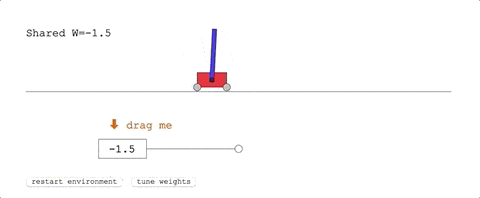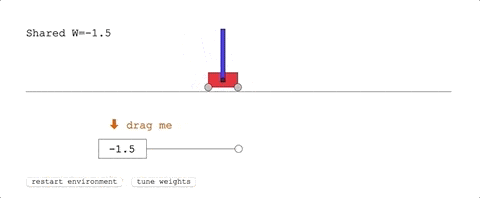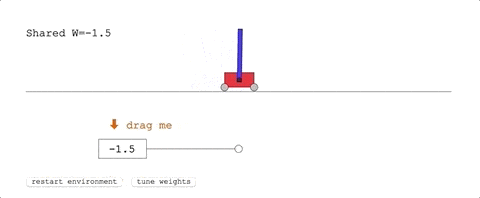
这是经典的控制任务,一条滑轨,一台小车,车上一根杆子。
小车在滑轨的范围里跑,要把杆子从自然下垂的状态摇上来,保持在直立的位置不掉下来。
(这个任务比单纯的Cart-Pole要难一些:
Cart-Pole杆子的初始位置就是向上直立,不需要小车把它摇上来,只要保持就可以。)
难度体现在,没有办法用线性控制器 (Linear Controller) 来解决。每一个时间步的奖励,都是基于小车到滑轨一头的距离,以及杆子摆动的角度。
WANN的最佳网络 (Champion Network) 长这样:

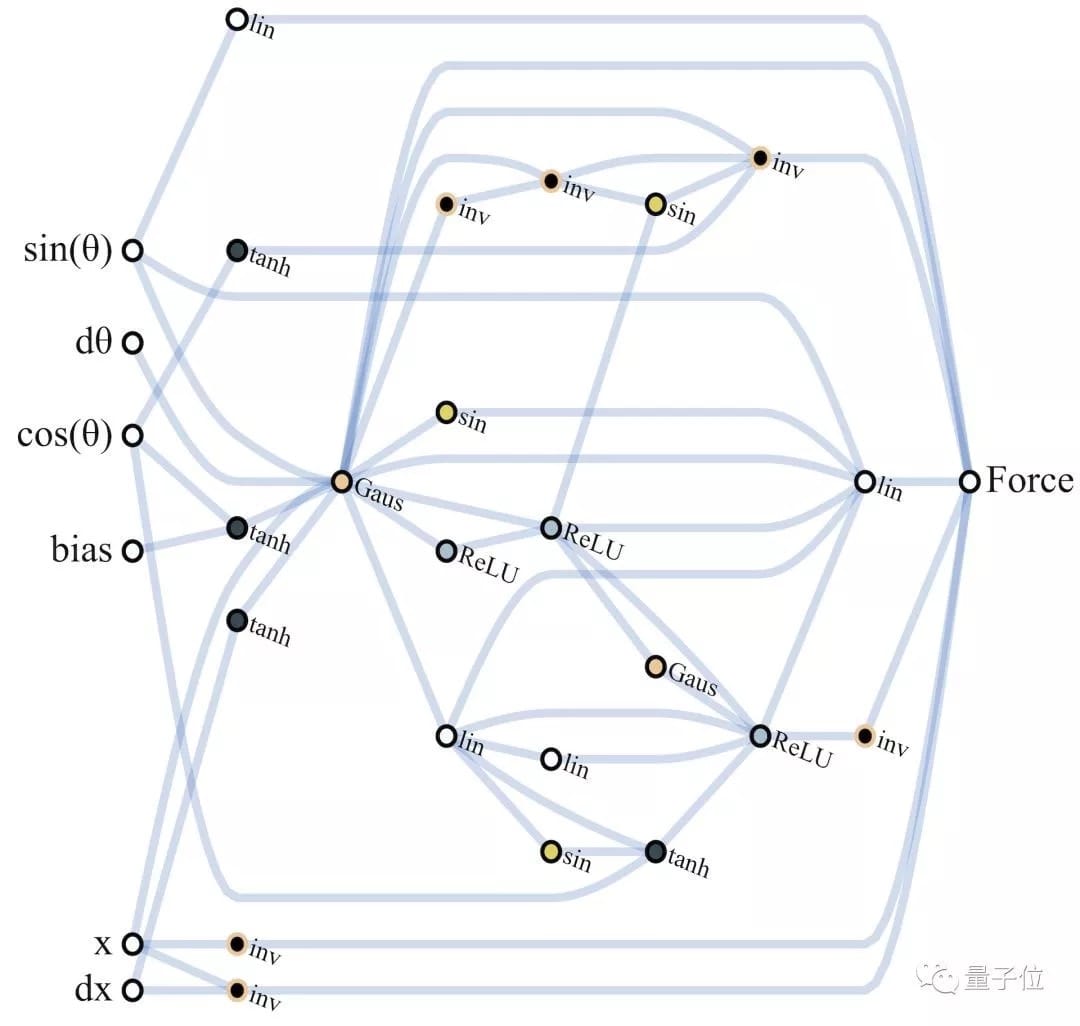
它在没有训练的状态下,已经表现优异:


表现最好的共享权重,给了团队十分满意的结果:只用几次摆动便达到了平衡状态。
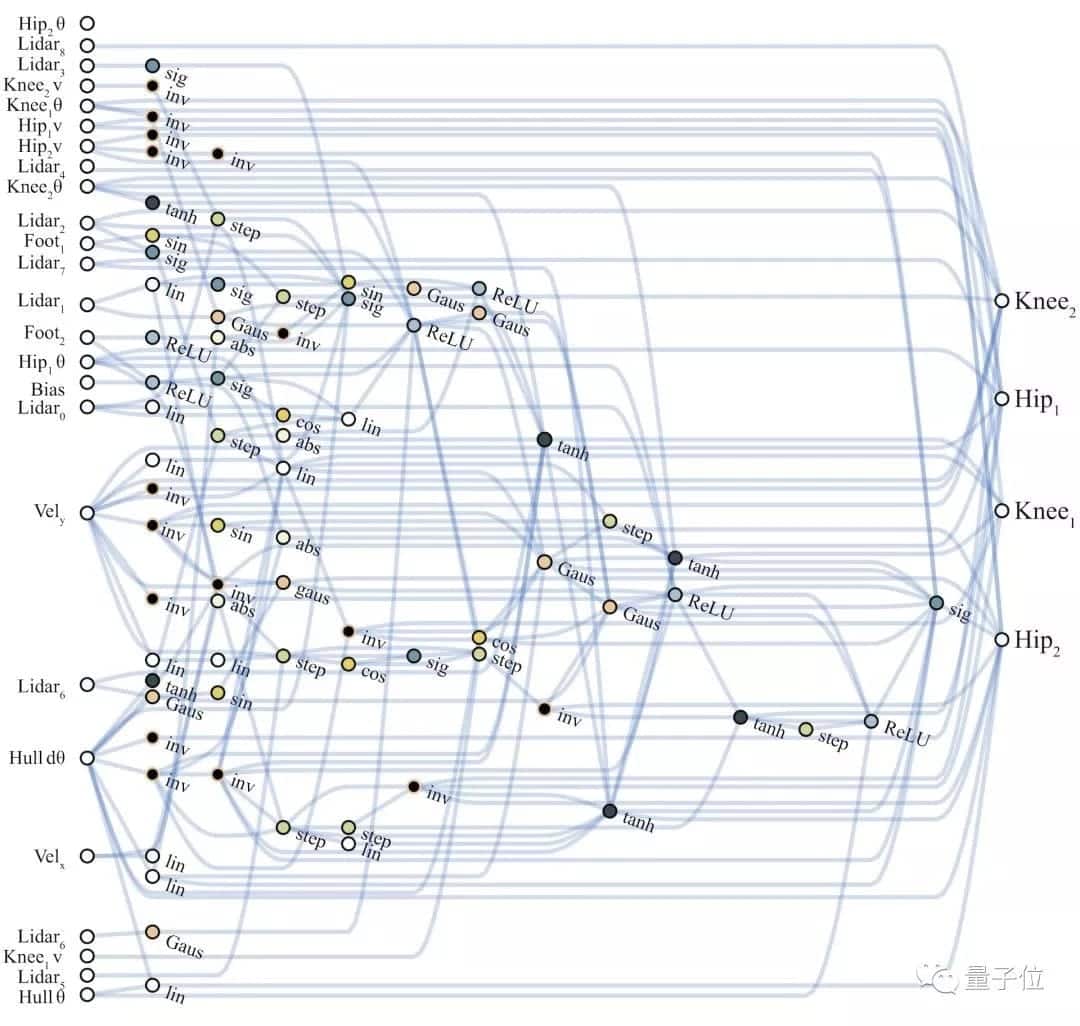
第二项任务,Bipedal Waker-v2。


一只两足“生物”,要在随机生成的道路上往前走,越过凸起,跨过陷坑。奖励多少,就看它从出发到挂掉走了多长的路,以及电机扭矩的成本 (为了鼓励高效运动) 。
每条腿的运动,都是由一个髋关节、和一个膝关节来控制的。有24个输入,会指导它的运动:包括“激光雷达”探测的前方地形数据,本体感受到的关节运动速度等等。
比起第一项任务中的低维输入,这里可能的网络连接就更多样了:
所以,需要WANN对从输入到输出的布线方式,有所选择。
这个高维任务,WANN也优质完成了。
你看,这是搜索出的最佳架构,比刚才的低维任务复杂了许多:
它在-1.5的权重下奔跑,长这样:


第三项任务,CarRacing-v0。
这是一个自上而下的 (Top-Down) 、像素环境里的赛车游戏。
一辆车,由三个连续命令来控制:油门、转向、制动。目标是在规定的时间里,经过尽可能多的砖块。赛道是随机生成的。
研究人员把解释每个像素 (Pixel Interpretation) 的工作交给了一个预训练的变分自编码器 (VAE) ,它可以把像素表征压缩到16个潜在维度。
这16维就是网络输入的维度。学到的特征是用来检测WANN学习抽象关联 (Abstract Associations) 的能力,而不是编码不同输入之间显式的几何关系。
这是WANN最佳网络,在-1.4共享权重下、未经训练的赛车成果:


虽然路走得有些蜿蜒,但很少偏离跑到。
而把最佳网络微调一下,不用训练,便更加顺滑了:


总结一下,在简单程度和模块化程度上,第二、三项任务都表现得优秀,两足控制器只用了25个可能输入中的17个,忽略了许多LIDAR传感器和膝关节的速度。
WANN架构不止能在不训练单个权重的情况下完成任务,而且只用了210个网络连接 (Connections) ,比当前State-of-the-Art模型用到的2804个连接,少了一个数量级。
做完强化学习,团队又瞄准了MNIST,把WANN拓展到了监督学习的分类任务上。
一个普通的网络,在参数随机初始化的情况下,MNIST上面的准确率可能只有10%左右。
而新方法搜索到的网络架构WANN,用随机权重去跑,准确率已经超过了80%;
如果像刚刚提到的那样,喂给它多个权值的合集,准确率就达到了91.6%。

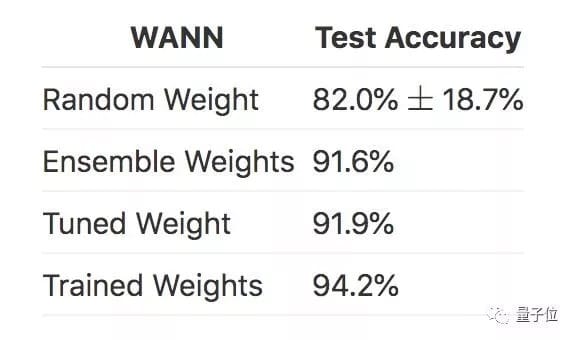
对比一下,经过微调的权重,带来的准确率是91.9%,训练过的权重,可以带来94.2%的准确率。
再对比一下,拥有几千个权重的线性分类器:


也只是和WANN完全没训练、没微调、仅仅喂食了一些随机权重时的准确率相当。
论文里强调,MINST手写数字分类是高维分类任务。WANN表现得非常出色。
并且没有哪个权值,显得比其他值更优秀,大家表现得十分均衡:所以随机权重是可行的。


不过,每个不同的权重形成的不同网络,有各自擅长分辨的数字,所以可以把一个拥有多个权值的WANN,用作一个自给自足的合集 (Self-Contained Ensemble) 。
实现原理
不训练权重参数获得极高准确度,WANN是如何做到的呢?
神经网络不仅有权重偏置这些参数,网络的拓扑结构、激活函数的选择都会影响最终结果。


谷歌大脑的研究人员在论文开头就提出质疑:神经网络的权重参数与其架构相比有多重要?在没有学习任何权重参数的情况下,神经网络架构可以在多大程度上影响给定任务的解决方案。
为此,研究人员提出了一种神经网络架构的搜索方法,无需训练权重找到执行强化学习任务的最小神经网络架构。
谷歌研究人员还把这种方法用在监督学习领域,仅使用随机权重,就能在MNIST上实现就比随机猜测高得多的准确率。
论文从架构搜索、贝叶斯神经网络、算法信息论、网络剪枝、神经科学这些理论中获得启发。
为了生成WANN,必须将权重对网络的影响最小化,用权重随机采样可以保证最终的网络是架构优化的产物,但是在高维空间进行权重随机采样的难度太大。
研究人员采取了“简单粗暴”的方法,对所有权重强制进行权重共享(weight-sharing),让权重值的数量减少到一个。这种高效的近似可以推动对更好架构的搜索。
操作步骤
解决了权重初始化的问题,接下来的问题就是如何收搜索权重不可知神经网络。它分为四个步骤:


1、创建初始的最小神经网络拓扑群。
2、通过多个rollout评估每个网络,并对每个rollout分配不同的共享权重值。
3、根据性能和复杂程度对网络进行排序。
4、根据排名最高的网络拓扑来创建新的群,通过竞争结果进行概率性的选择。
然后,算法从第2步开始重复,在连续迭代中,产生复杂度逐渐增加的权重不可知拓扑(weight agnostic topologies )。
拓扑搜索
用于搜索神经网络拓扑的操作受到神经进化算法(NEAT)的启发。在NEAT中,拓扑和权重值同时优化,研究人员忽略权重,只进行拓扑搜索操作。


上图展示了网络拓扑空间搜索的具体操作:
一开始网络上是最左侧的最小拓扑结构,仅有部分输入和输出是相连的。
然后,网络按以下三种方式进行更改:
1、插入节点:拆分现有连接插入新节点。
2、添加连接:连接两个之前未连接的节点,添加新连接。
3、更改激活函数:重新分配隐藏节点的激活函数。
图的最右侧展示了权重在[2,2]取值范围内可能的激活函数,如线性函数、阶跃函数、正弦余弦函数、ReLU等等。
权重依然重要
WANN与传统的固定拓扑网络相比,可以使用单个的随机共享权重也能获得更好的结果。


虽然WANN在多项任务中取得了最佳结果,但WANN并不完全独立于权重值,当随机分配单个权重值时,有时也会失败。
WANN通过编码输入和输出之间的关系起作用,虽然权重的大小的重要性并不高,但它们的一致性,尤其是符号的一致性才是关键。
随机共享权重的另一个好处是,调整单个参数的影响变得不重要,无需使用基于梯度的方法。
强化学习任务中的结果让作者考虑推广WANN方法的应用范围。他们又测试了WANN在图像分类基础任务MNIST上的表现,结果在权重接近0时效果不佳。


有Reddit网友质疑WANN的结果,对于随机权重接近于0的情况,该网络的性能并不好,先强化学习实验中的具体表现就是,小车会跑出限定范围。


对此,作者给出解释,在权重趋于0的情况下,网络的输出也会趋于0,所以后期的优化很难达到较好的性能。
传送门
源代码:
https://github.com/weightagnostic/weightagnostic.github.io
本文转载于公众号 人工智能学家,原文地址