
本文详解 YouTube 的推荐机制,他们是如何给用户推荐下一个视频的。

Google新技术帮助我们了解神经网络的思维方式
可解释性仍然是现代深度学习应用的最大挑战之一。计算模型和深度学习研究的最新进展使得能够创建高度复杂的模型,其中包括数千个隐藏层和数千万个神经元。虽然创建令人难以置信的高级深度神经网络模型相对简单,但了解这些模型如何创建和使用知识仍然是一个挑战。最近,Google Brain团队的研究人员发表了一篇论文,提出了一种名为概念激活向量(CAV)的新方法,它为深度学习模型的可解释性提供了一个新的视角。
可解释性与准确性
要理解CAV技术,了解深度学习模型中可解释性挑战的本质非常重要。在当前一代深度学习技术中,模型的准确性与我们解释其知识的能力之间存在着永久的摩擦。可解释性 – 准确性摩擦是能够完成复杂知识任务和理解这些任务是如何完成之间的摩擦。知识与控制,绩效与责任,效率与简单……选择你最喜欢的困境,所有这些都可以通过平衡准确性和可解释性之间的权衡来解释。
您是否关心获得最佳结果,或者您是否关心如何产生这些结果?这是数据科学家在每个深度学习场景中都需要回答的问题。许多深度学习技术本质上是复杂的,虽然它们在许多场景中都非常准确,但它们的解释却非常难以理解。如果我们可以在一个与准确性和可解释性相关的图表中绘制一些最着名的深度学习模型,我们将获得如下内容:
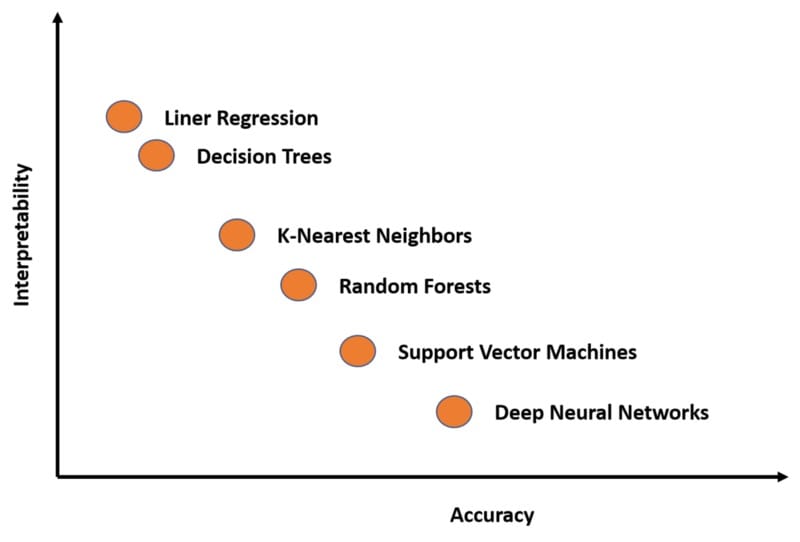
深度学习模型中的可解释性不是一个单一的概念,可以跨多个层次看到:
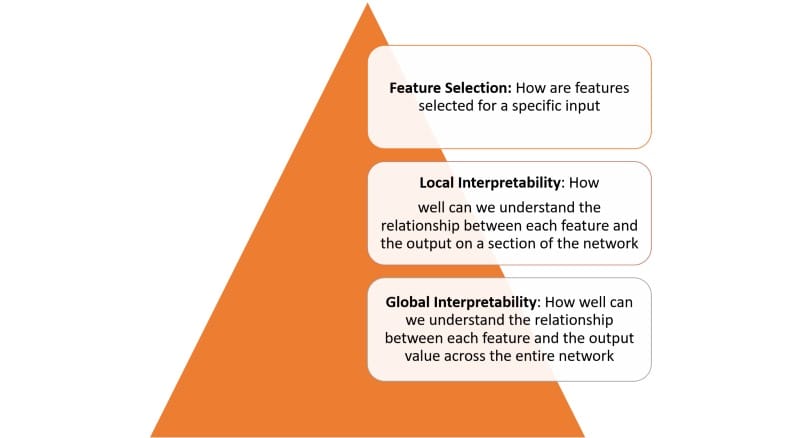
实现上图中定义的每个层的可解释性需要几个基本构建块。在最近的一篇论文中,谷歌的研究人员概述了他们认为可解释性的一些基本构建块。
Google总结了可解释性原则如下:
– 了解隐藏层的作用:深层学习模型中的大部分知识都是在隐藏层中形成的。在宏观层面理解不同隐藏层的功能对于解释深度学习模型至关重要。
– 了解节点的激活方式:可解释性的关键不在于理解网络中各个神经元的功能,而是在同一空间位置一起激发的互连神经元群。通过互连神经元组对网络进行分段将提供更简单的抽象级别来理解其功能。
– 理解概念是如何形成的:了解神经网络形成的深度,然后可以组合成最终输出的个体概念是可解释性的另一个关键构建块。
这些原则是Google新CAV技术背后的理论基础。
概念激活向量
遵循上一节中讨论的想法,可解释性的自然方法应该是根据它所考虑的输入特征来描述深度学习模型的预测。一个典型的例子是逻辑回归分类器,其中系数权重通常被解释为每个特征的重要性。然而,大多数深度学习模型对诸如像素值之类的特征进行操作,这些特征与人类容易理解的高级概念不对应。此外,模型的内部值(例如,神经激活)似乎是不可理解的。虽然诸如显着图之类的技术在测量特定像素区域的重要性方面是有效的,但是它们无法与更高级别的概念相关联。
CAV背后的核心思想是衡量概念在模型输出中的相关性。概念的CAV只是该概念的一组示例的值(例如,激活)方向上的向量。在他们的论文中,Google研究团队概述了一种名为Testing with CAV(TCAV)的新线性可解释方法,该方法使用方向导数来量化模型预测对CAV学习的基础高级概念的敏感性。从概念上讲,TCAV的定义有四个目标:
– 可访问性:用户几乎不需要ML专业知识。
– 定制:适应任何概念(例如,性别),并不限于培训期间考虑的概念。
– 插件就绪:无需重新训练或修改ML型号即可工作。
– 全局量化:可以使用单一定量度量来解释整个类或一组示例,而不仅仅是解释单个数据输入。

为实现上述目标,TCAV方法分为三个基本步骤:
1)为模型定义相关概念。
2)理解预测对这些概念的敏感性。
3)推断每个概念对每个模型预测类的相对重要性的全局定量解释。

TCAV方法的第一步是定义感兴趣的概念(CAV)。TCAV通过选择一组代表该概念的示例或找到标记为概念的独立数据集来实现此目的。通过训练线性分类器来学习CAV,以区分概念的示例和任何层中的示例所产生的激活。
第二步是生成一个TCAV分数,用于量化预测对特定概念的敏感性。TCAV通过使用方向性导数来实现这一点,该方向导数用于衡量ML预测对神经激活层的概念方向输入变化的敏感性。
最后一步尝试评估学习CAV的全局相关性,以避免依赖不相关的CAV。毕竟,TCAV技术的一个缺陷是有可能学习无意义的CAV。毕竟,使用随机选择的一组图像仍然会产生CAV。基于这种随机概念的测试不太可能有意义。为了应对这一挑战,TCAV引入了统计显着性检验,该检验针对随机数量的训练运行(通常为500次)评估CAV。该想法是,有意义的概念应该导致TCAV分数在训练运行中表现一致。
TCAV在行动
与其他可解释性方法相比,Google Brain团队进行了多次实验来评估TCAV的效率。在一项最引人注目的测试中,该团队使用了一个显着图,试图预测标题或图像的相关性,以了解出租车的概念。显着性图的输出如下所示:
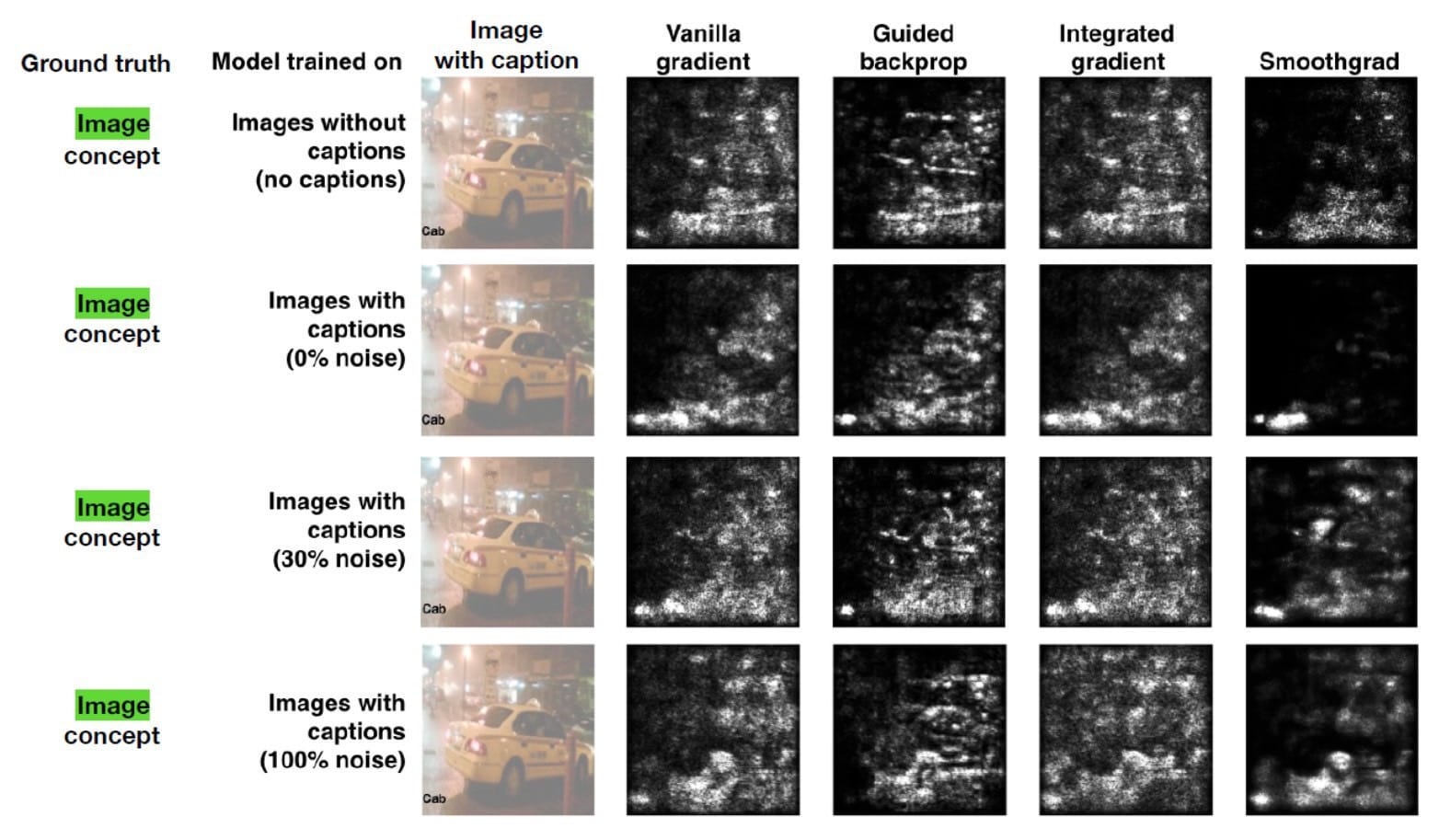
使用这些图像作为测试数据集,Google Brain团队在Amazon Mechanical Turk上使用50人进行了实验。每个工作人员执行一系列六个任务(3个对象类x 2s效率图类型),所有这些任务都针对单个模型。任务顺序是随机的。在每项任务中,工作人员首先看到四个图像及其相应的显着性面具。然后,他们评估了他们认为图像对模型的重要程度(10分制),标题对模型的重要程度(10分制),以及他们对答案的自信程度(5分制)。总共,特种飞行员评定了60个独特的图像(120个独特的显着图)。
实验的基本事实是图像概念比标题概念更相关。然而,当观察显着性图时,人们认为标题概念更重要(具有0%噪声的模型),或者没有辨别出差异(具有100%噪声的模型)。相比之下,TCAV结果正确地表明图像概念更重要。

TCAV是过去几年中最具创新性的神经网络解释方法之一。初始技术的代码可以在GitHub上获得,我们应该期望看到一些主流深度学习框架适应的想法。
本文转自towardsdatascience,原文地址
谷歌发布颠覆性研究:不训练不调参,AI自动构建超强网络
谷歌大脑团队发布了一项新研究:只靠神经网络架构搜索出的网络,不训练,不调参,就能直接执行任务。这样的网络叫做WANN,权重不可知神经网络。
Google手写字符识别的新进展
15年时Google曾经推出了支持82种语言的手写输入,并在去年升级为100种语言。但随着机器学习的迅速发展,研究人员也在不断重构着以往的方法为用户带来更快更准的体验。