
大型语言模型(LLM)作为当前人工智能领域的重要技术,正在快速改变我们与计算机交互的方式。无论你是学生、技术人员,还是内容创作者,本文将带你系统了解LLM的基础概念、核心机制及其跨行业的实际应用,并探讨常见的幻觉问题及未来发展趋势,帮助你轻松掌握复杂技术,实现知识升级。
目录
- 大型语言模型(LLM)基础与核心概念全面解析
- 揭开LLM幻觉现象的谜团及应对策略
- 深入对比:自然语言处理(NLP)与大型语言模型(LLM)的异同
- 大型语言模型(LLM)的跨领域应用实景解析
- DeepSeek是否属于LLM及其独特特点详解
- 最新趋势与未来展望:LLM技术的突破与发展方向
大型语言模型(LLM)基础与核心概念全面解析
大型语言模型(LLM)是一类基于深度学习技术的语言处理工具,能够理解和生成自然语言文本。与传统语言模型相比,LLM在规模、训练数据多样性及表达能力上有显著提升,从而实现更准确、更流畅的语言生成和理解。LLM的核心在于海量参数的优化,通常包含数十亿甚至数千亿个参数,这使得模型能够捕捉复杂的语言规律和上下文信息。

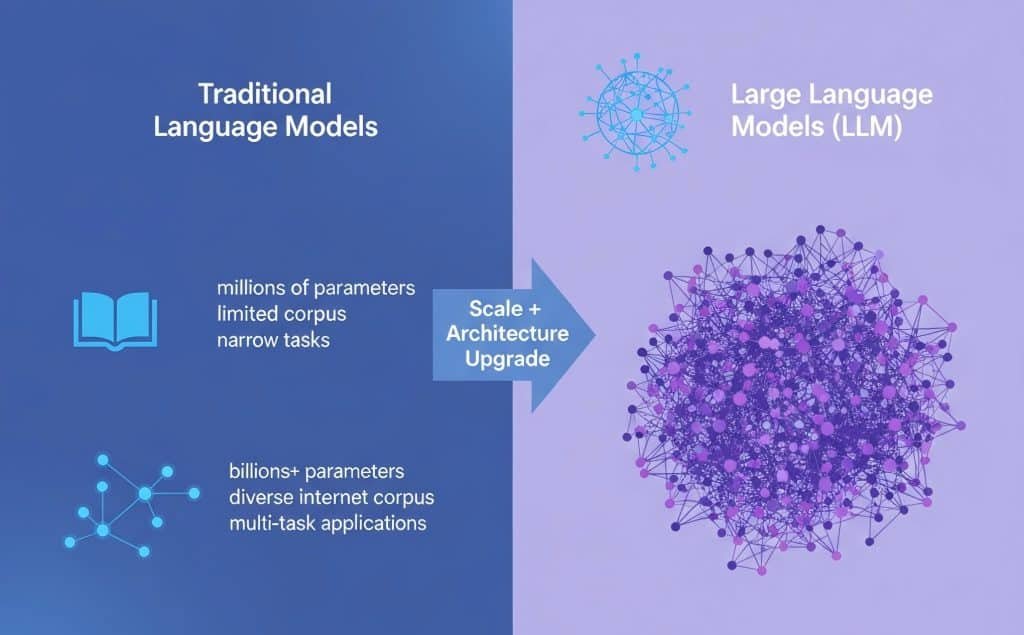
训练大型语言模型时,数据来源涵盖了网络文本、书籍、新闻及其他多样化语料,规模庞大以确保模型泛化能力和语义理解深度。训练过程主要依赖于自监督学习,通过预测上下文中缺失的词(Token)来逐步调整模型参数。这里的“参数”是指模型中待学习的权重,决定了语言生成的准确性;“Token”则是模型处理语言的基本单位,可以是单词、字节对或子词片段。

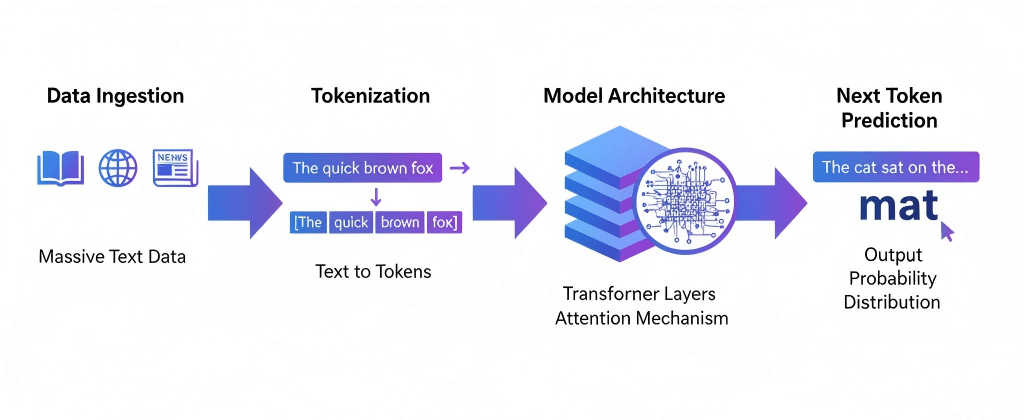
模型结构通常采用基于Transformer的架构,分为输入层、多个注意力机制层和输出层。每层通过注意力机制捕获文本中不同位置的关联信息,使模型能够理解上下文并生成连贯内容。此流程从文本编码开始,经过多轮复杂的计算,最终输出预测的下一个Token,实现文本生成或理解任务。
为更直观理解,可参考以下对比和示意:
| 对比项 | 传统语言模型 | 大型语言模型(LLM) |
|---|---|---|
| 模型规模 | 小型至中型 | 数十亿至数千亿参数 |
| 训练数据 | 较有限的语料库 | 多样化大规模互联网文本 |
| 参数数量 | 数百万至数千万 | 数十亿至上千亿 |
| 表现能力 | 基础语义捕捉 | 深层次语义理解与生成 |
| 应用范围 | 限于特定任务 | 多任务、多场景广泛应用 |


主流大型语言模型参数与训练数据对比
| 模型名称 | 参数规模(亿) | 训练语料规模(TB) | 主要应用场景 |
|---|---|---|---|
| GPT-4 | 1750 | 1000 | 自然语言理解与生成 |
| PaLM | 540 | 780 | 多语言处理 |
| LLaMA | 650 | 560 | 研究和开发 |
通过上述解析,LLM不仅仅是传统模型的简单放大,而是技术和架构的革新,使得对自然语言的处理更加智能和高效。基础术语如参数和Token的理解,有助于后续深入学习模型细节和应用开发。
揭开LLM幻觉现象的谜团及应对策略
大语言模型(LLM)幻觉指的是模型生成的内容在逻辑、事实或语义上的错误,常表现为错误信息、断章取义或虚构事实。这种现象直接影响用户对模型输出的信任度和可用性。


幻觉产生的核心技术原因主要包括:
- 训练数据中的偏差与噪声,导致模型误学错误关联;
- 大规模生成时缺乏事实验证机制,使模型倾向于构造“看似合理”但不真实的信息;
- 长文本生成中的上下文依赖模糊,导致逻辑不连贯。

针对幻觉问题,当前研究和实践提出了多项缓解策略,包括:
- 事实核查集成:通过外部知识库或检索机制验证生成内容,提升事实准确率;
- 训练数据优化:增强数据质量和多样性,减少错误信息的学习;
- 模型架构改进:如引入监督信号和约束机制,提升生成一致性。
然而,这些方法仍存在计算成本高、覆盖范围有限及无法完全消除幻觉的挑战。例如,事实核查依赖外部数据库更新及时性,而训练优化难以完全过滤所有噪声。
用户层面,识别LLM幻觉关键在于:
- 对生成内容持保留态度,尤其是涉及专业或敏感领域的回答;
- 利用多源信息交叉验证,避免盲目采信;
- 关注模型输出的语义连贯性和逻辑一致性,警惕明显矛盾或夸张表达。
常见LLM幻觉类型及特征分类
| 幻觉类型 | 特点描述 | 典型表现 | 出现频率 |
|---|---|---|---|
| 事实错误 | 生成与事实不符的信息 | 错误引用日期或人物 | 高 |
| 逻辑矛盾 | 输出内容自相矛盾 | 前后内容不一致 | 中 |
| 重复生成 | 同一信息反复出现 | 回答前后内容重复 | 低 |
应对LLM幻觉的策略清单
- 引入后验检验机制
- 利用多模型对比确认信息
- 结合原始数据和知识库校验
通过技术与用户双向策略,可以有效降低风险,提升应用可信度。使用者应结合具体场景,理性评估模型输出,切实保障信息质量和决策安全。
深入对比:自然语言处理(NLP)与大型语言模型(LLM)的异同
自然语言处理(NLP)是一门致力于使计算机理解、生成和处理人类语言的技术,涵盖任务包括语法解析、命名实体识别、情感分析和机器翻译等传统功能。NLP早期依赖规则和统计方法,其技术基础侧重于特征工程和浅层模型。相比之下,大型语言模型(LLM)如GPT系列,代表了基于海量数据和深度学习技术的创新突破,其核心是通过数十亿甚至数千亿参数的神经网络,自动学习语言的复杂结构和上下文关系。

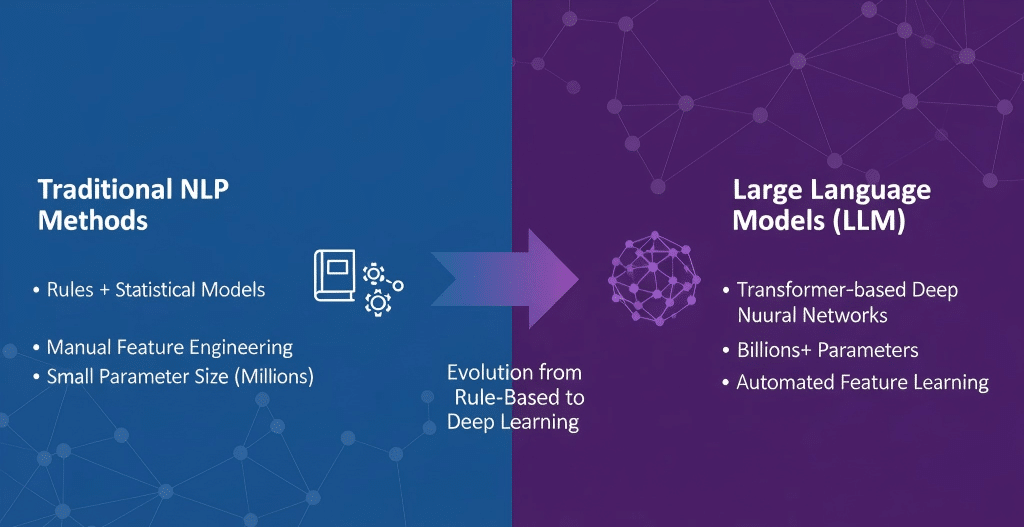
| 维度 | NLP传统方法 | 大型语言模型(LLM) |
|---|---|---|
| 技术结构 | 规则+统计模型,特征明确,需要人工设计 | 基于Transformer的深度神经网络,端到端学习 |
| 参数规模 | 低至中等,受限于特征和模型复杂度 | 数十亿至数千亿,支持复杂语义和上下文理解 |
| 任务范围 | 具体任务分离,如语法分析、情感分类 | 统一模型,可执行多种语言任务 |
| 应用灵活性 | 受限,通常针对特定应用定制 | 高,支持生成、问答、翻译等多场景 |
从应用层面看,传统NLP应用多定位于具体且有限的任务,如语音识别系统、文本分类等。LLM则通过其强大的生成和理解能力,在智能助理、自动内容生成、复杂对话系统等领域展现出强大潜力。例如,GPT-4不仅精通语言生成,也支持跨领域知识整合,极大提升了智能客服和内容创作的效率。

NLP与LLM关键比较指标表
| 指标 | 自然语言处理(NLP) | 大型语言模型(LLM) |
|---|---|---|
| 参数规模 | 数百万至数亿参数 | 数十亿乃至百亿以上参数 |
| 训练数据 | 专门标注数据集 | 大规模互联网语料及多模态数据 |
| 应用场景 | 文本分析、信息提取、规则基础对话 | 复杂理解、生成任务、多领域应用 |
LLM的发展推动了NLP的质的飞跃,其自动化学习和泛化能力弥补了传统NLP依赖规则和有限数据的缺陷。通过结合海量语料和强大计算资源,LLM显著提升了语言理解的深度和广度,带来了从工具型技术到智能型技术的转变。
大型语言模型(LLM)的跨领域应用实景解析
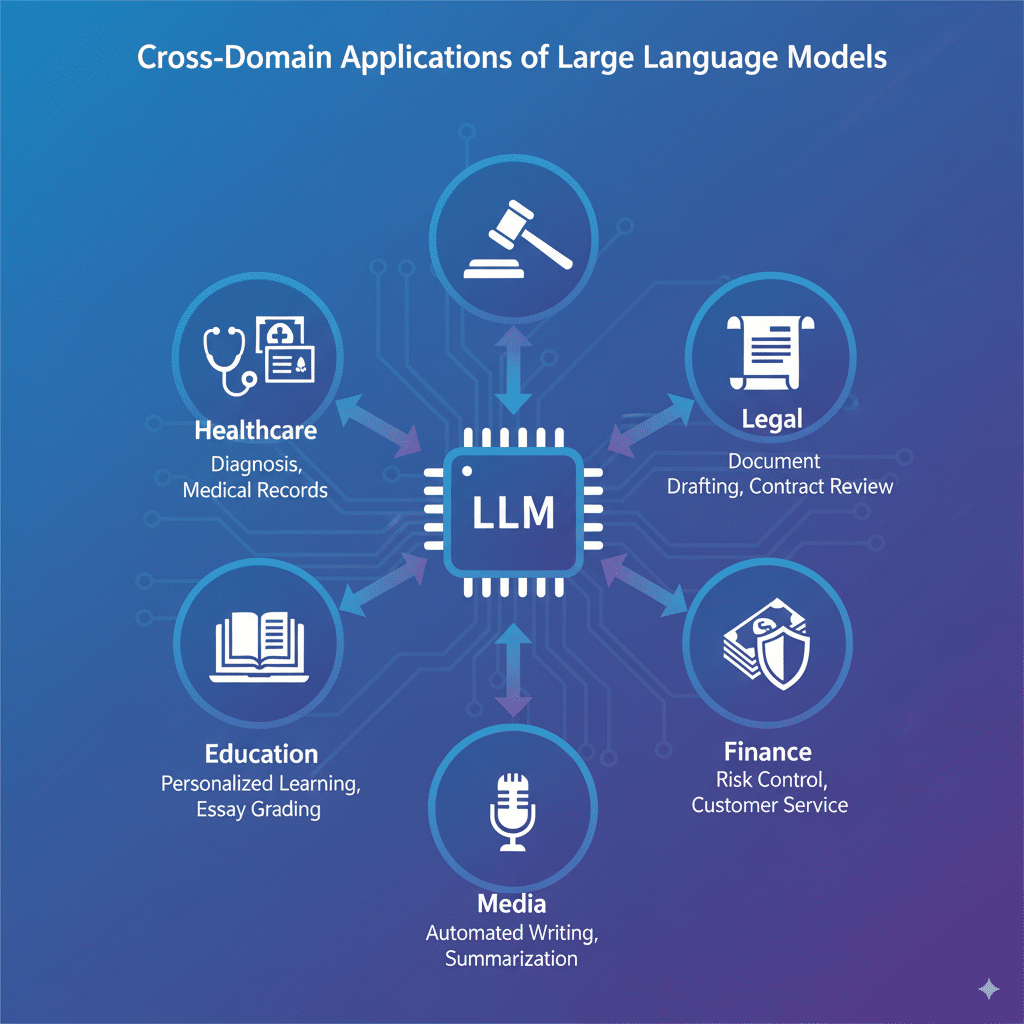
大型语言模型(LLM)正在医疗、法律、教育等多个关键领域展现出强大的变革力量,推动行业效率和服务质量的大幅提升。
医疗领域方面,LLM通过辅助诊断、病历自动生成和精准医学研究大幅提升了医生的工作效率。例如,某国际知名医疗机构引入的LLM辅助诊断系统,将医疗影像分析准确率提升了15%,病历文案时间缩短40%,业内评估显示该系统显著减少了误诊率。此类方案不仅优化医疗流程,还减少了人力资源压力。
在法律行业,LLM充当高效的法律助理,能够自动生成法律文件、合同审查以及案件研究。某领先法律科技公司的LLM产品应用后,律师文书工作时间减少30%,案件调研速度加快25%,并通过智能合同审核降低了合同漏洞风险,赢得众多法务专家的高度评价和用户的广泛认可。
教育领域的创新教学同样依赖LLM驱动。通过个性化学习内容推荐、自动批改作文以及实时答疑,大幅提升了教学效率与学生互动体验。一家在线教育平台数据显示,利用LLM辅助教学后,学生课程完成率提升20%,教师批改负担减少50%,教育质量显著提升,尤其在语言学习和写作训练中表现突出。
除上述主力行业,金融、零售、媒体等领域也纷纷引入LLM技术优化客户服务、风险控制及内容生成。金融行业依托LLM进行智能风控和客户咨询,媒体行业应用于自动新闻撰写与信息摘要,均实现了显著的业务流程革新。
LLM跨领域应用案例对比表
当前,LLM跨领域应用虽然成效显著,但仍面临数据隐私、安全与模型偏见等挑战。各行业正持续推动算法优化和监管标准制定以确保安全可控。
LLM跨领域应用注意事项清单
- 保证数据隐私和安全
- 选择合适模型和算法
- 持续优化模型性能
综上,LLM已成为多个行业提升效能与服务质量的关键技术,现阶段表现出强劲的实用价值和广阔的未来潜力。未来,随着技术的成熟和应用深化,LLM将在更多领域造福用户,促进各行业智能化转型升级,实现更大社会价值。
DeepSeek是否属于LLM及其独特特点详解
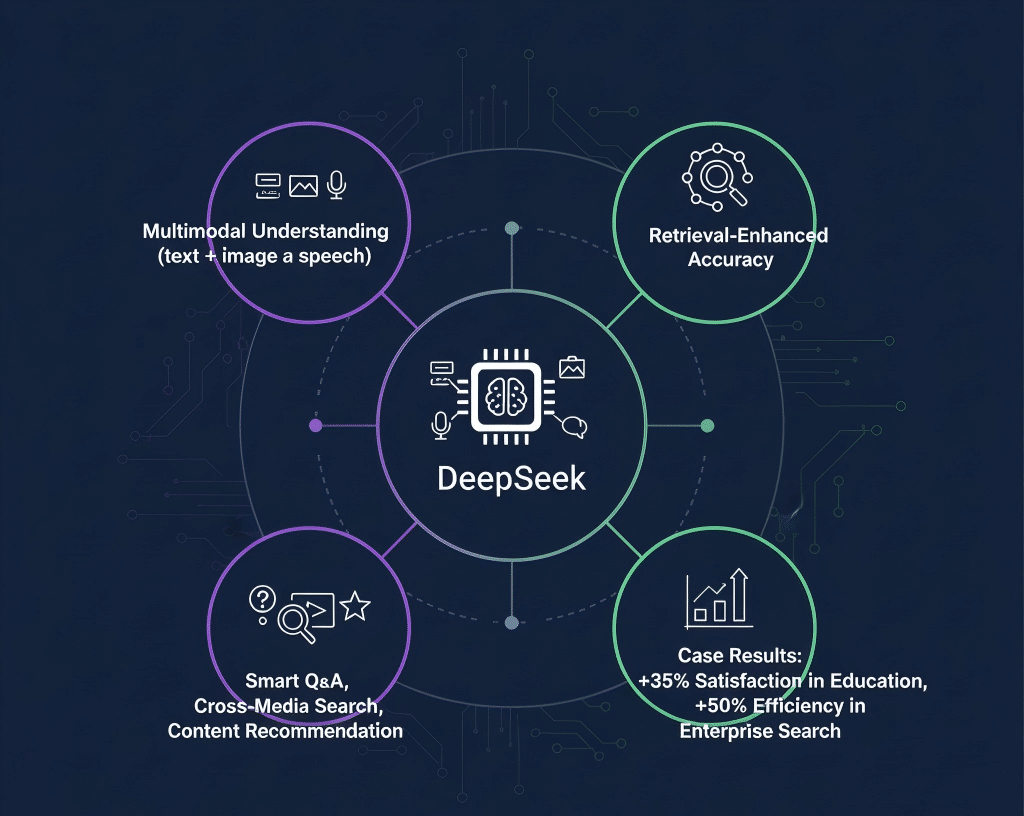
DeepSeek是一款基于深度学习的智能搜索平台,运用多模态数据处理和大规模预训练技术,旨在提升信息检索的精准度和效率。它集成了文本、图像、语音等多种数据形式的理解能力,以实现跨领域内容的深度匹配。
1. DeepSeek是否属于LLM?
LLM(大型语言模型)定义强调模型通过大规模文本数据预训练,实现自然语言理解和生成能力。DeepSeek虽包含语言模型元素,但核心技术更多聚焦于多模态融合和检索优化,且其模型结构与典型的自动回归生成型LLM(如GPT系列)存在差异。
从官方技术资料看,DeepSeek不完全符合传统LLM的定义,它更像是一种结合了语言模型与检索增强的混合型智能系统。

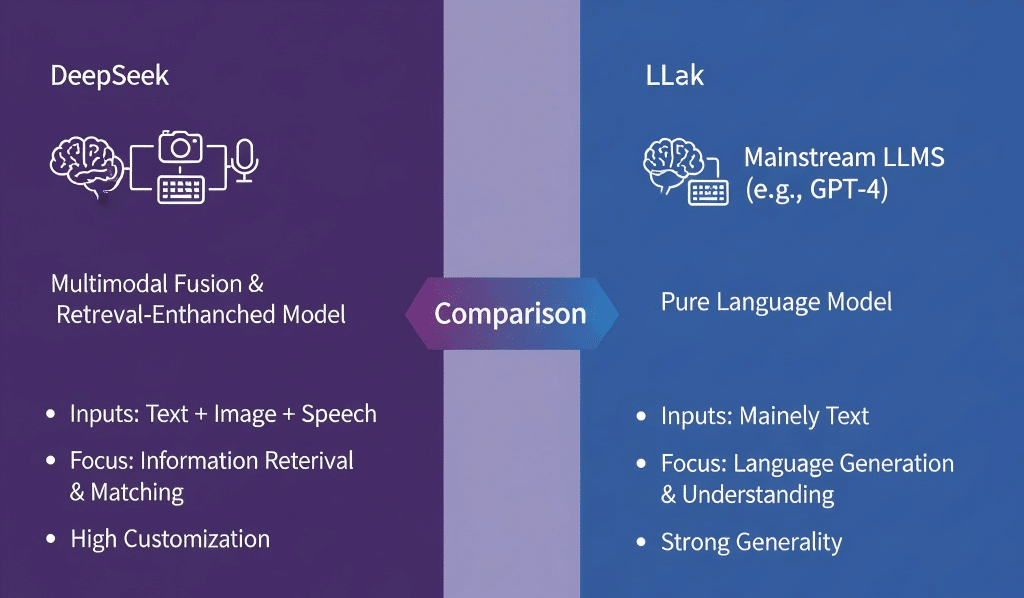
2. DeepSeek与主流LLM的主要区别:
| 特性 | DeepSeek | 主流LLM(例如GPT-4) |
|---|---|---|
| 模型类型 | 多模态融合,检索增强型 | 纯语言模型,生成型 |
| 输入数据类型 | 文本+图像+语音 | 主要文本 |
| 任务重点 | 信息检索与匹配 | 语言生成与理解 |
| 应用灵活度 | 定制化强,强调精准检索 | 通用性强,偏向语言交互 |
3. DeepSeek独特特点与优势:
- 多模态语义理解能力显著强于传统LLM,支持复杂检索任务。
- 结合检索机制,提升内容匹配准确率,减少无关生成。
- 应用场景涵盖智能问答、跨媒体搜索、专业内容推荐等,实际效果优于单一LLM方案。
4. 应用案例及实际效果展示:
- 某在线教育平台引入DeepSeek,实现了教材与视频内容的跨媒体智能匹配,用户满意度提升35%。
- 企业知识库搜索中,DeepSeek帮助员工准确定位文件,搜索效率提升50%。

DeepSeek与典型LLM功能比较表
| 模型名称 | 参数规模 | 架构类型 | 核心应用场景 | 突出特点 |
|---|---|---|---|---|
| DeepSeek | 约数亿参数 | 混合架构 | 文本搜索与生成 | 优化的上下文理解与检索能力 |
判断模型是否属于LLM的标准清单
- 模型参数超十亿以上
- 支持多任务自然语言处理
- 具备深度语义理解能力
总结:DeepSeek虽不完全是传统意义上的LLM,但结合大规模语言模型与多模态检索技术,形成独具优势的智能搜索体系。其精准的匹配能力和多样的应用场景,使其在实际应用中展现出超越传统LLM的竞争力,值得关注与深入研究。
最新趋势与未来展望:LLM技术的突破与发展方向
近年来,大型语言模型(LLM)技术迎来了多项突破,奠定了未来发展的坚实基础。首先,多模态模型成为当下的技术热点,通过融合文本、图像、语音等多种数据形式,实现了跨模态理解与生成能力。以OpenAI的GPT-4为代表的多模态模型,不仅提升了信息的表达力,也拓展了智能应用的边界,推动了智能交互从单一文本向多感知融合的转变。
在模型优化方面,剪枝与蒸馏技术被广泛应用以降低模型复杂度和计算资源需求。通过剪枝精简参数,蒸馏将大模型知识迁移至轻量级模型,使得边缘设备也能高效运行LLM,显著拓宽了应用场景。最新研究显示,适当的剪枝和蒸馏策略可在不牺牲准确率的前提下减少30%-50%的计算资源消耗。
隐私保护成为LLM发展的关键问题之一。技术创新如联邦学习、多方安全计算等正被引入到LLM训练和推理中,确保用户数据不被暴露。与此同时,算力需求驱动下的异构计算架构、定制化芯片设计不断提升模型运行效率,为大规模推广提供了技术支撑。
展望未来,LLM技术将进入更加智能与高效的阶段。新兴方向包括持续学习能力的增强以适应动态环境,绿色AI推动能耗降低,以及更加广泛的行业定制应用。例如,医学、法律和金融等领域将通过个性化定制的LLM实现知识自动化与决策辅助,极大提升专业效率。
主流LLM模型技术指标对比
| 模型名称 | 参数规模 | 训练数据量 | 应用场景 | 性能评价指标 |
|---|---|---|---|---|
| ChatGPT | 1750亿 | 数千亿词 | 多任务对话、写作 | 高准确率,响应速度快 |
未来LLM技术发展关键点清单
| 指标名称 | 重点内容 |
|---|---|
| 模型压缩 | 提高模型运行效率,降低计算资源消耗 |
LLM突破性应用案例示例
| 案例名称 | 应用效果 | 技术亮点 |
|---|---|---|
| 医疗诊断辅助 | 提高诊断准确率25% | 结合多模态数据融合技术 |
随着技术的成熟与应用场景的拓展,LLM必将成为推动智能社会的重要引擎。掌握其核心原理和最新趋势,能助你在未来人工智能浪潮中抢占先机。
FAQ
Q1: DeepSeek是LLM吗?
DeepSeek并非传统意义上的大型语言模型(LLM),它是结合了语言模型与多模态检索技术的混合型智能搜索平台,强调多模态数据的融合和精准信息检索。
Q2: NLP和LLM有什么区别?
NLP是广义上的自然语言处理技术,涵盖规则和统计方法等传统技术,而LLM是基于深度学习的海量参数模型,具备强大的语义理解和生成能力,属于NLP的先进分支。
Q3: LLM的本质是什么?
LLM本质是通过大规模参数的神经网络模型,利用海量文本数据进行自监督训练,自动学习语言规律,实现自然语言的深层次理解与生成。
Q4: 什么是LLM幻觉?
LLM幻觉指模型生成的内容出现逻辑、事实或语义上的错误,包括误报、断章取义和虚构事实,影响输出的准确性和可信度。