
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 Transformer(知乎版本)?
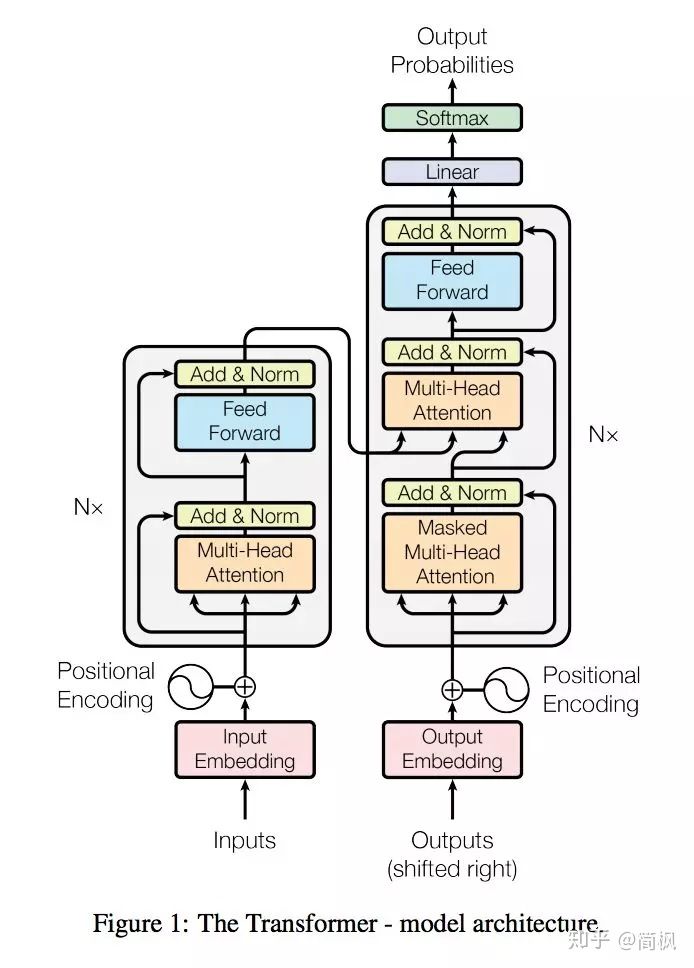
如上图所示,咋一看,Transformer 的架构是不是有点复杂。。。没事,下面慢慢讲。。。
和经典的 seq2seq 模型一样,Transformer 模型中也采用了 encoer-decoder 架构。上图的左半边用 NX 框出来的,就代表一层 encoder,其中论文里面的 encoder 一共有6层这样的结构。上图的右半边用 NX 框出来的,则代表一层 decoder,同样也有6层。
定义输入序列首先经过 word embedding,再和 positional encoding 相加后,输入到 encoder 中。输出序列经过的处理和输入序列一样,然后输入到 decoder。
最后,decoder 的输出经过一个线性层,再接 Softmax。
于上便是 Transformer 的整体框架,下面先来介绍 encoder 和 decoder。
什么是 Transformer(微软研究院笨笨)?
Transformer在2017年由Google在题为《Attention Is All You Need》的论文中提出。Transformer是一个完全基于注意力机制的编解码器模型,它抛弃了之前其它模型引入注意力机制后仍然保留的循环与卷积结构,而采用了自注意力(Self-attention)机制,在任务表现、并行能力和易于训练性方面都有大幅的提高。
在 Transformer 出现之前,基于神经网络的机器翻译模型多数都采用了 RNN的模型架构,它们依靠循环功能进行有序的序列操作。虽然 RNN 架构有较强的序列建模能力,但是存在训练速度慢,训练质量低等问题。
与基于 RNN 的方法不同,Transformer 模型中没有循环结构,而是把序列中的所有单词或者符号并行处理,同时借助自注意力机制对句子中所有单词之间的关系直接进行建模,而无需考虑各自的位置。具体而言,如果要计算给定单词的下一个表征,Transformer 会将该单词与句子中的其它单词一一对比,并得出这些单词的注意力分数。注意力分数决定其它单词对给定词汇的语义影响。之后,注意力分数用作所有单词表征的平均权重,这些表征输入全连接网络,生成新表征。
由于 Transformer 并行处理所有的词,以及每个单词都可以在多个处理步骤内与其它单词之间产生联系,它的训练速度比 RNN 模型更快,在翻译任务中的表现也比 RNN 模型更好。除了计算性能和更高的准确度,Transformer 另一个亮点是可以对网络关注的句子部分进行可视化,尤其是在处理或翻译一个给定词时,因此可以深入了解信息是如何通过网络传播的。
之后,Google的研究人员们又对标准的 Transformer 模型进行了拓展,采用了一种新型的、注重效率的时间并行循环结构,让它具有通用计算能力,并在更多任务中取得了更好的结果。
改进的模型(Universal Transformer)在保留Transformer 模型原有并行结构的基础上,把 Transformer 一组几个各异的固定的变换函数替换成了一组由单个的、时间并行的循环变换函数构成的结构。相比于 RNN一个符号接着一个符号从左至右依次处理序列,Universal Transformer 和 Transformer 能够一次同时处理所有的符号,但 Universal Transformer 接下来会根据自注意力机制对每个符号的解释做数次并行的循环处理修饰。Universal Transformer 中时间并行的循环机制不仅比 RNN 中使用的串行循环速度更快,也让 Universal Transformer 比标准的前馈 Transformer 更加强大。
上面内容转载在公众号 微软研究院AI头条,原文地址
1 Comment
视频无法播放。。。