


【前一阵子英伟达的StyleGAN可谓是火了一把,近日又出大招了!以往图像到图像转换需要大量的图像做训练样本,但是在英伟达的这项工作中,仅需小样本就可以做到图像到图像的转换(代码已开源)!
小样本,大成就!
当我们看到一只站着的老虎时,我们很容易想象出来它躺着的样子。


这是因为我们根据其它动物平躺的姿势就是可以做联想。


然而,对于机器来说就没有这么简单了。在现存的非监督图像到图像转换模型需要大量的训练图像。


不仅如此,一个模型能够转换图像的另一个前提是图像中的对象必须在训练集中存在。
近期,英伟达、康纳尔大学和阿尔托大学联合发表了一篇文章——小样本(few-shot)非监督图像到图像转换。


论文地址:
https://arxiv.org/pdf/1905.01723.pdf
简单来说,就是输入一只金毛,在训练过程当中,即便第一次看到一种新动物,也能让它像金毛那样吐舌头、闭嘴巴、歪头。


若是输入一张炒面的图,该模型也可以让其它食物变成炒面。


这项工作还提供了在线测试,新智元小编们便拿自家的猫主子“西瓜”和“多比”做了一下测试:


输入“西瓜”得到的结果


输入“多比”得到的结果
在线测试连接如下,读者们快快玩起来吧:
https://nvlabs.github.io/FUNIT/petswap.html
该项目的代码也已开源,地址如下:
https://github.com/NVlabs/FUNITFUNIT
2阶段图像转换,非常有趣!
我们提出的FUNIT框架旨在通过利用在测试时可用的几个目标类图像,将源类的图像映射到目标类的类似图像。
为了训练FUNIT,我们使用来自一组对象类(例如各种动物物种的图像)中的图像,称为源类(source classes)。我们不假设任何两个类之间存在配对的图像(即,不同物种的任何两个动物都不会是完全相同的姿势)。
我们使用源类里的图像来训练一个multi-class无监督图像到图像转换模型。
在测试过程中,我们从一个称为目标类(target class)的新对象类中提供少量几张图像。模型必须利用少量的目标图像来将源类里的任何图像转换为目标类里的类似图像。

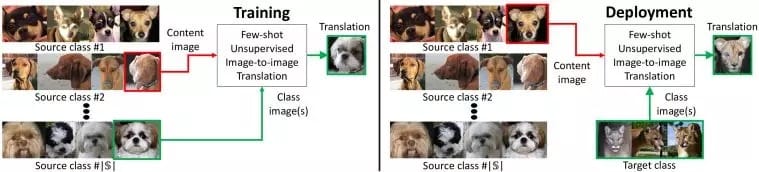
训练。训练集由各种对象类(源类)的图像组成。我们训练了一个模型在这些源对象类之间转换图像。
部署。我们向训练模型显示极少量目标类里的图像,这就足以将源类的图像转换为目标类的类似图像了,即使模型在训练期间从未见过目标类的任何图像。
需要注意的是,FUNIT生成器有两个输入:1)一个内容图像;2)一组目标类图像。它的目的是生成与目标类图像相似的输入图像的转换。
我们的框架由一个有条件的图像发生器G和一个多任务对抗性鉴别器D组成。
与现有无监督image-to-image translation框架中有条件的图像生成器不同,它们是将一张图像作为输入,而我们的生成器G需要同时将一张内容图像x和一组K类图像{y1, …, yK}作为输入,生成输出图像x¯,公式如下:

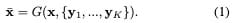
实验结果:姿态和种类一起转换,超越基准模型
主要结果


如表1所示,FUNIT框架在Animal Faces和North American Birds两个数据集的所有性能指标都优于用于小样本无监督图像到图像转换任务的基线模型。
FUNIT在Animal Faces数据集的1-shot和5-shot设置上分别达到82.36和96.05 的Top-5 测试精度,以及在North American Birds数据集上分别达到60.19和75.75的Top-5 测试精度。
这些指标都明显优于相应的基准模型。


在图2中,我们对FUNIT-5计算的few-shot translation的结果进行了可视化。





从上到下分别是来自动物面孔、鸟、花和食物数据集的结果。每个示例随机展示了2张目标类中的图像,输入内容图像x,以及转换后的输出图像x¯。
结果表明,模型能够成功地将源类的图像转换为新的类中的相似图像。对象在输入内容图像x和相应输出图像x¯中的姿态基本保持不变。输出图像也非常逼真,类似于目标类中的图像。
图3提供FUNIT与基线模型的结果比较。可以看到,FUNIT生成了高质量的图像转换输出。


图3:小样本图像到图像转换效果的比较。
从左到右的列分别是输入内容图像x,两个输入目标类图像y1,y2,来自不公平的StarGAN基线的转换结果,来自公平的StarGAN基线的转换结果,以及来自FUNIT框架的结果。
参考链接:
https://arxiv.org/pdf/1905.01723.pdf
https://nvlabs.github.io/FUNIT/petswap.html
https://github.com/NVlabs/FUNIT
本文转自公众号 新智元,原文地址