


本文转载自公众号 读芯术,原文地址
RNN的训练有别于普通前馈神经网络,反向传播中会产生权重矩阵的连乘,使得长时间步下的微弱偏移得到放大,产生梯度消失和爆炸,上文介绍的正交初始化和激活函数的选择,目的都是让参数矩阵的特征值尽量维持在1附近。我们本文介绍一种“曲线救国”的方式,它并不直接改变权重的特征值,而是将神经元参数化,通过生成线性自循环的路径,取消了原本RNN中的权重参数W,这就是长短时记忆单元LSTM(long short-term memory)。
这里面有一个广泛的误解,这个单元并不是拥有长时记忆和短时记忆的单元,而是一个长的短时记忆单元,短时记忆在心理学上就表示着工作记忆,类似于内存。从英文名字可以看出来,是long short-term memory,而非long-short term memory。
我们在之前的《如何理解神经网络的循环结构》中曾经阐明了循环结构的本质,它对于不同时间步上的数据序列使用了同样的网络结构,只是将某个或者几个层存储起来用作下一时间步的输入,这个存储的结构就是记忆单元:


如图为RNN的简单结构,我们依次输入序列化数据,前一个时间步的隐层会将得到的数据存放到memory单元,然后再将memory单元乘以矩阵W进入到下一个时间步的隐层。
在上图中,我们下一个时间步的memory单元的存储的信息(Ct)就是:


我们取消权重参数W,并对这个memory单元做重参数化:
- 由一个门(gate)来参数化存储的步骤,当这个门打开时,我们才会将信息存放到memory单元,这个门叫做输入门(Input Gate)。
- memory单元要不要将信息流入到下一个时间步,也由一个门控制,只有当这个门打开时,我们才会将信息输入到下一个时间步,这个门叫做输出门(Output Gate)。
memory单元并非是一个实体,完全可以嵌入到隐藏层本身,我们在这个操作之上又增添了两个门,用来控制输入和输出,就得到了一个基本结构:


其中,输入和输出由sigmoid函数控制,sigmoid函数的输出在[0,1],可以很好的刻画门的开启或者关闭状态,值的大小就可以表示门被开启的程度。我们将输入门的结果用一个函数Fi来表示,输出门的结果用Fo来表示,为了保证输入门的开启和关闭状态对输入的影响,我们将其直接相乘再一起进入memory,memory的状态我们用C来表示:


这样存入到memory的值就受到了输入门的调节,当其完全关闭时,就代表着信息没有流入。接下来,在输出的时候,我们再次相乘输出门的结果,但是,如果我们希望输入门和输出门的尽可能独立一些,因为直接相乘必然会导致当输入门很小时,输出门即便很大,也不会产生多少输出,所以,我们使用一个函数g作用在memory的结果上,再进行输出门的控制处理:


此时我们得到了一个较为复杂的神经元,输入门控制了信息的流入,输出门控制了信息的流出,那么看起来我们的memory单元是不必要的,但是在RNN中,我们必然采用权重W来控制流通的信息,在LSTM中,我们并没有使用权重,而只是采用简单的相加:


随着序列越来越长,时间步越来越大,前一步的memory会流入到我们下一步的memory,会使得后面的memory单元存储的数值越来越大。此时,有两种可能的后果:
- 如果我们的函数g也是一个带有挤压性质的激活函数,那么过大的值将会使得这个激活函数永远处于激活状态,失去了学习能力。
- 如果我们的函数g是ReLU类型的函数,值变得非常巨大时,会使得输出门失效,因为输出门的值再小,当它乘以一个庞大的值时,也会变的非常大。
无论是哪种情况,都在表明我们需要在memory单元中丢弃一些信息,LSTM的解决办法是在原本的单元中加入一个遗忘门(forget gate),它的作用是重参数化记忆单元,将记忆单元输入的信息乘以遗忘门的结果Ff,存入到记忆单元中作为信息,所以当前的信息就变为了:


可以写出公式如下:

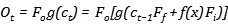
需要特别注意的是,如果我们使用sigmoid函数作为激活函数,那么当遗忘门为1时,就代表着将前一步的信息原封不动的存入到当前,这与它的名字恰好相反,也就是说,当遗忘门关闭时,它会忘记,当遗忘门打开时,它才会回忆。(有点拗口)
整个流程就是,我们将当前时间步的数据乘以输入门的结果,同时前一步的记忆单元乘以遗忘门的结果,两者相加,一起乘以输出门的结果,得到下一层的输出,同时此时的记忆单元参与到下一时间步的运算。


这是一幅大家喜闻乐见的LSTM的示意图,如果你看懂了前面的内容,那么可以和我一起来走一遍,1代表着遗忘门,2代表着输入门,3代表着输出门,中间的符号有➕,✖️,就代表着两种运算,从左到右,上一步的记忆单元C(t-1)与遗忘门相乘,再加上输入门与输入的相乘结果得到当前的记忆单元Ct,Ct沿箭头参与到下一时间步的记忆运算。同时Ct与输出门相乘得输出Ht,Ht沿着箭头参与到下一时间步的输入运算。
在理解LSTM的工作流程之后,我们自然会问它是如何解决长期依赖的问题,有的人会认为这是因为它包含了短时记忆和长时记忆,有的人则会看图说话,说这是因为上一层的信息无损的流入下一层。这两种说法都是错误的。
真正的答案就在上文的取消权重W。在普通RNN中,随着时间步,同一记忆单元存储的信息会越来越多,就选择使用一个权重参数W来学习到自己保留或者去除掉哪些信息,但却会带来长期依赖的问题。整个LSTM的最精华的部分是遗忘门的设计,它不通过权重W就可以解决掉信息冗余的问题,由


变为了


当遗忘门打开时,接近于1,在反复传播中就以更小的几率产生梯度消失。在实践中,我们往往也要保证遗忘门在大多数时间上是被打开的。