


本文转载自公众号 PaperWeekly,原文地址
香侬科技近期提出 Glyce,首次在深度学习的框架下使用中文字形信息(Glyph),横扫 13 项中文自然语言任务记录,其中包括:(1) 字级别语言模型 (2) 词级别语言模型 (3) 中文分词 (4) 命名实体识别 (5) 词性标注 (6) 句法依存分析 (7) 语义决策标注 (8) 语义相似度 (9) 意图识别 (10) 情感分析 (11) 机器翻译 (12) 文本分类 (13) 篇章分析。


论文链接:https://arxiv.org/abs/1901.10125
论文简介
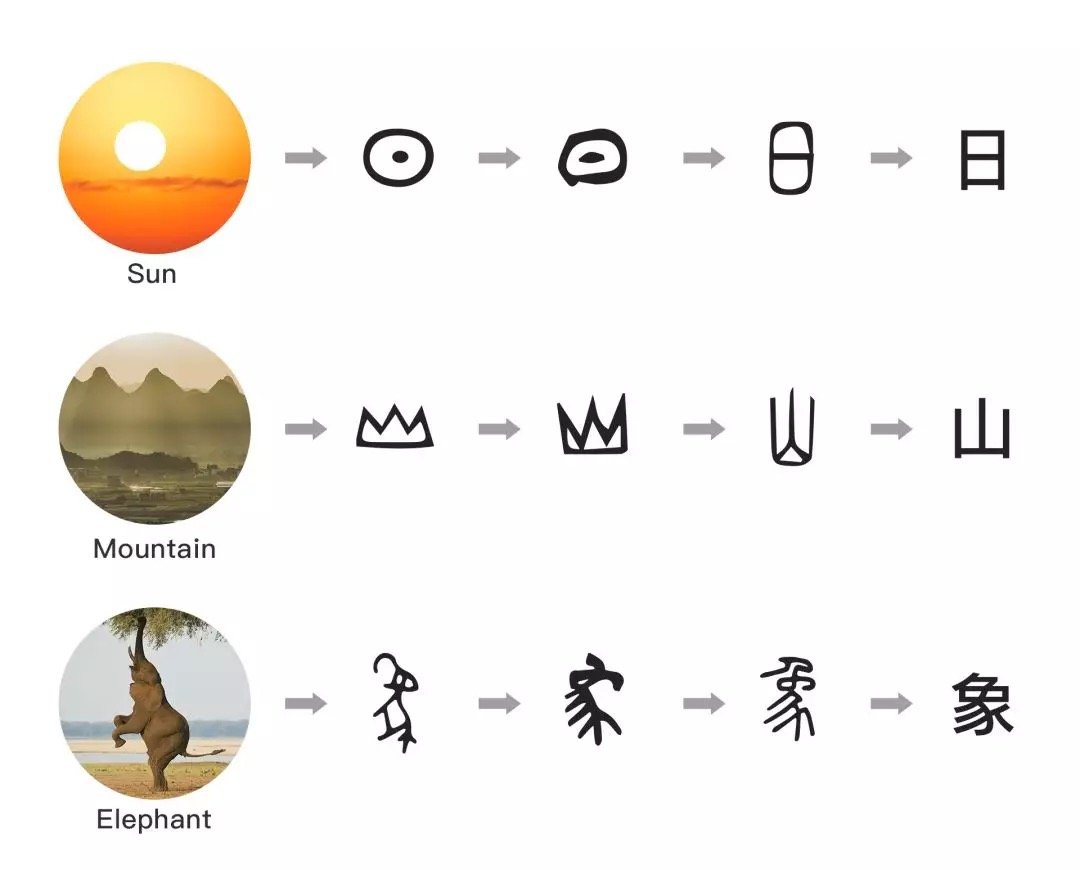
汉字是象形文字(logographic language),历经几千年的历史演变,是当今世界上依然被使用的最古老的文字。汉字与英文有本质的区别,因为大多数汉字的起源是图形,汉字的字形中蕴藏着丰富的语音信息。即便是不识字的人,有时候也可以大概猜到一个字的大概意思。
相反,英文很难从字形中猜出语义,因为英文是 alphabetic language,所基于的罗马字母反应更多的是文字的读音,而并不是语义。
然而当今中文自然语言处理的方法,大多是基于英文 NLP 的处理流程:以词或者字的 ID 为基准,每一个词或者字有一个对应的向量,并没有考虑汉语字形的信息。
Glyce 提出了基于中文字形的语义表示:把汉字当成一个图片,然后用卷积神经网络学习出语义,这样便可以充分利用汉字中的图形信息,增强了深度学习向量的语意表达能力。Glyce 在总共 13 项、近乎所有中文自然语言处理任务上刷新了历史记录。

论文详解
理论上将中文字符当成图片直接输入至卷积神经网络便可以。但是这样实现的效果并不好。Glyce 试图从三个方面解决这个问题:
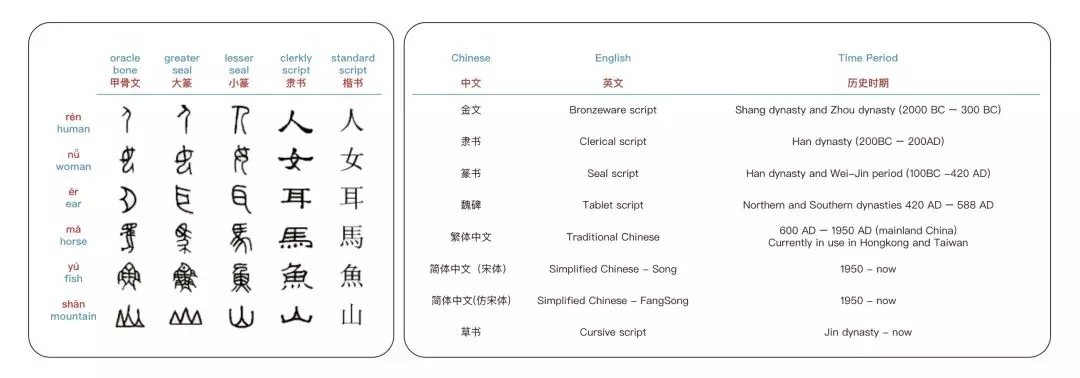
运用不同历史时期的中文字符
如今广泛使用的简体中文字符是经过漫长的历史演变而来的。简体中文书写更加方便,但是同时也丢失了大量的原始图形信息。Glyce 提出需要运用不同历史时期的中文字符,从周商时期的金文,汉代的隶书,魏晋时期的篆书,南北朝时期的魏碑,以及繁体、简体中文。这些不同类别的字符在语义上更全面涵盖了语义信息。

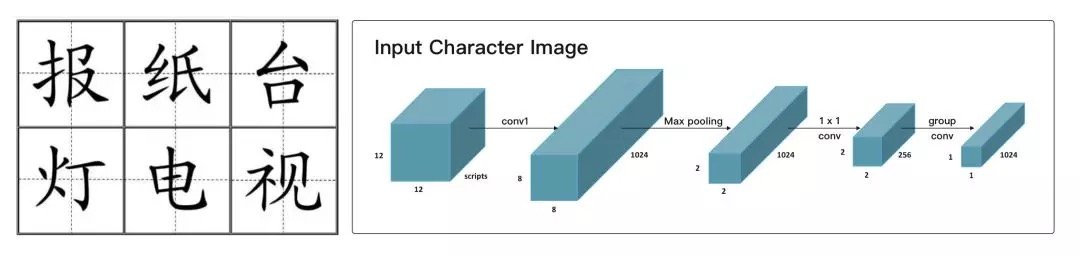
提出符合中文字形的Tianzige(田字格)-CNN架构
Glyce 提出了一些修改 CNN 内部架构的意见,让模型更适合处理中文字形。主要的改进集中在两个方面,第一是为了防止过拟合,减小 CNN 中所涉及的参数量,比如将 conv 层变成 grouped conv。还有第二个比较有意思的点是最后一层通过 pooling 将图像输入变成 2*2 的 grids。文中提到这个模型非常符合中文的田字格模式,而田字格结构其实非常符合中文文字的书写顺序。

Multi-task Learning(多任务学习)
相比于图像分类任务大多有几百万或者上千万的训练数据,汉字只有上千个。即便算上不同字体,模型只能够见到几万个不同的字符图像样本。这对图像的泛化能力提出了挑战。
为了解决这个问题,Glyce 提出需要用图像分类任务作为辅助模型(auxiliary training objective)。CNN 输出的 glyph 向量将同时被输入到基于字符的分类任务中。实际的训练函数是 task-specific 的损失函数和字形图像识别损失函数的线性加权:

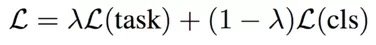

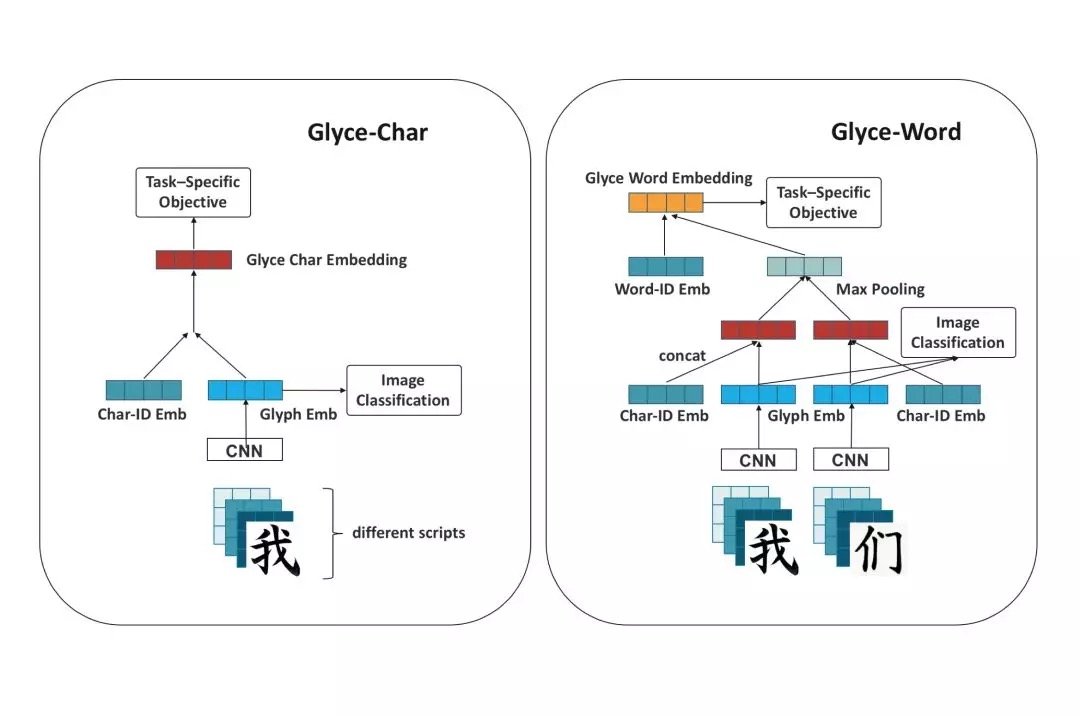
Glyce中文字向量
Glyce 将来自不同历史时期的相同字符堆积形成不同的 channel,并且通过 CNN 对这些图像信息进行编码得到了 glyph 向量。得到的 glyph 向量输入到图像分类模型得到字形图像识别的损失函数。然后通过 highway network 或者全连接的方式将 glyph 向量和对应的中文 char-id 向量进行结合得到了最终的 Glyce 中文字向量。
Glyce中文词向量
由于中文的词都可以看成是由中文的字组成,Glyce 通过充分利用组成中文词中的汉字得到更加细粒度的词的语意信息。使用 Glyce 字向量的方式得到词中的对应字的表示。
因为中文词中字的个数的不确定性,Glyce 通过 max pooling 层对所有得到的 Glyce 字向量进行特征的筛选,用来保持了维度的不变性。最终得到的向量通过和 word-id 向量进行拼接得到最终的 Glyce 中文词向量。
实验
使用 Glyce 的编码方式分别在:(1)字级别语言模型(2)词级别语言模型(3)中文分词(4)命名实体识别(5)词性标注(6)句法依存分析(7)语义决策标注(8)语义相似度(9)意图识别(10)情感分析(11)机器翻译(12)文本分类(13)篇章分析,共 13 个中文自然语言处理任务上进行了实验。
实验结果刷新了所有实验任务的记录,充分展示了 Glyce 在中文向量语意表示编码的有效性和鲁棒性,并且展示了 Glyce 的设计优势。
字级别语言模型


字级别语言模型采用了 Chinese Tree-Bank 6.0 (CTB6.0)语料,并且采用 PPL(困惑度)作为最终的评价指标。通过使用 8 种历史字体和图像分类的损失函数,基于字级别的语言模型的 PPL(困惑度)达到了 50.67。
词级别语言模型


词级别的语言模型采用了 Chinese Tree-Bank 6.0 (CTB6.0)语料,并且采用 PPL(困惑度)作为最终的评价指标。经过对照实验,word-ID 向量和 glyce 词向量在词级别的语言模型上效果最好,PPL(困惑度)达到了 175.1。
中文分词

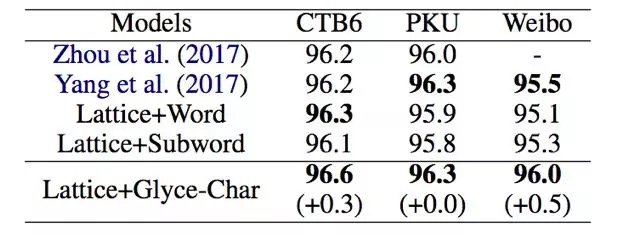
中文分词任务采用了 CTB6,PKU 和 Weibo 的数据集。Glyce 字向量结合之前最优的模型 Lattice-LSTM 在 CTB6 和 Weibo 数据上达到了新的最优的结果。在 PKU 的数据上达到了呵之前最优结果相同的结果。
命名实体识别


命名实体识别采用了 OntoNotes,MSRA 和 resume 的数据集,并且采用 F1 作为最终的评价指标。实验结果表示,Glyce-char 模型刷新了这三个数据集的新纪录。在 OntoNotes,MSRA,Resume 上分别超过了之前最优模型 Lattice-LSTM 0.93,0.71 和 1.21 个点。
词性标注

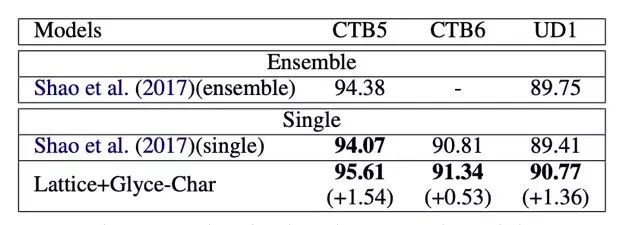
词性标注采用了 CTB5, CTB6,UD1 的数据集。单个模型使用 Glyce 词向量在 CTB5 和 UD1 数据上分别超过之前的 state-of-the-art 1.54 和 1.36 个百分点。Glyce 单模型效果在 CTB5 和 UD1 上超过之前多模型集合的最优结果。
句法依存分析

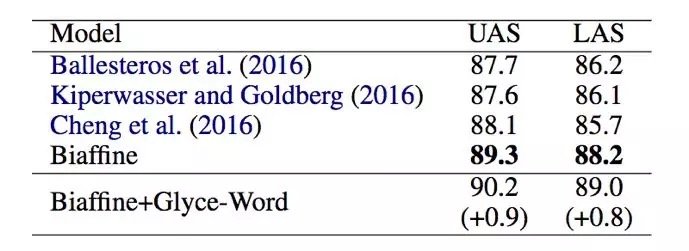
句法依存分析采用了 Chinese Penn Treebank 5.1 的数据。Glyce 词向量结合之前最优的 Biaffien 模型把结果在 UAS 和 LAS 数据集上和最优结果比较分别提高了 0.9 和 0.8。
语义决策标注

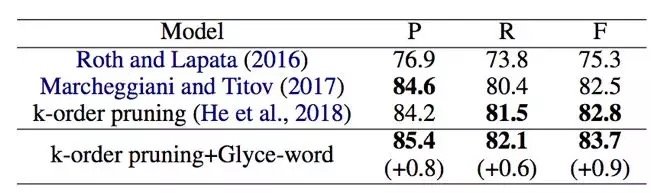
语义决策标注的实验采用了 CoNLL-2009 的数据,并且采用 F1 作为最终的评价指标。最优模型 k-order pruning 和 Glyce 词向量超过了之前最优模型 0.9 的 F1 值。
语义相似度


语义相似度的实验采用了 BQ Corpus 的数据集,并且采用准确率和 F1 作为最终的评价指标。Glyce 字向量结合 BiMPM 模型在之前最优结果的基础上提高了 0.97 个点,成为了新的 state-of-the-art。
意图识别


意图识别的任务使用了 LCQMC 的数据集进行了实验,并且采用准确率和 F1 作为最终的评价指标。通过训练 BiMPM 结合 Glyce 字向量在 F1 上超过了之前的最优结果 1.4,在 ACC 上超过了之前的最优结果 1.9。
情感分析


情感分析的任务采用了 Dianping,JD Full, JD Binary 三个数据集,并且采用准确率作为最终的评价指标。Glyce 字向量结合 Bi-LSTM 模型分别在这三个数据集上面取得了最优的结果。
中文-英文机器翻译

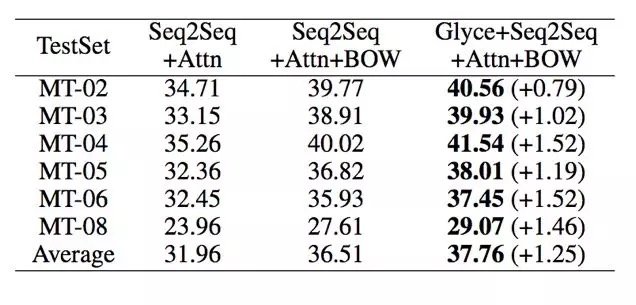
中文-英文机器翻译任务的训练集来自 LDC 语料,验证集来自 NIST2002 语料。测试集分别是 NIST2003,2004,2005,2006 和 2008,并且采用 BLEU 作为最终的评价指标。Glyce 词向量结合 Seq2Seq+Attention 模型,测试集上 BLEU 值达到了新的最优结果。
文本分类


文本分类的任务采用了 Fudan corpus, IFeng, ChinaNews 三个数据集,并且采用准确率作为评价指标。Glyce 字向量结合 Bi-LSTM 模型在这三个数据集上分别取得了最优的结果。
篇章分析

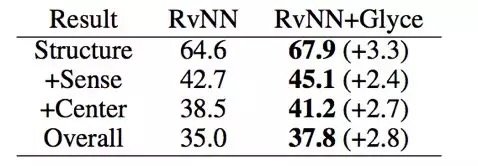
篇章分析的任务采用了 Chinese Discourse Treebank (CDTB)的数据集,并且采用准确率作为评价指标。采用了之前 SOTA 模型 RvNN 和 Glyce 字向量,刷新了在 CDTB 数据上的准确率的最优结果。
总结
提出的 Glyce 的中文字符级表示模型,通过使用不同历史时期的字符图像,丰富了中文字向量和词向量的语意信息。通过使用 Glyce 对中文字符的建模方式,我们刷新了几乎所有的中文自然语言处理任务的 state-of-the-art。Glyce 的成功为以中文为代表的象形文字提供了新的研究方向。
文章作者
Glyce 作者数量多达九个。Wei Wu(吴炜)与 Yuxian Meng(孟昱先)并列为第一作者。Wei Wu(吴炜)在字符级语言模型任务上设计并实现了第一个 Glyce-char 模型。Yuxian Meng(孟昱先)提出了 Tianzige-CNN 结构,图像分类作为辅助目标函数和衰变 λ。Jiwei Li(李纪为)提出使用不同历史时期的中文字符。Yuxian Meng(孟昱先)负责词级语言模型和意图分类的结果;Wei Wu(吴炜)负责中文分词,命名实体识别和词性标注的结果。Qinghong Han(韩庆宏)负责语义角色标注的结果;Xiaoya Li(李晓雅)负责中文-英文机器翻译的结果;Muyu Li(李慕宇)负责句法依存分析和词性标注的结果;Mei Jie(梅杰)负责篇章分析的结果;Nie Ping(聂平)负责语义相似度的结果;Xiaofei Sun(孙晓飞)负责文本分类和情感分析的结果。Jiwei Li(李纪为)为 Glyce 通讯作者。