


机器学习、人工智能、深度学习是什么关系?
1956 年提出 AI 概念,短短3年后(1959) Arthur Samuel 就提出了机器学习的概念:
Field of study that gives computers the ability to learn without being explicitly programmed.
机器学习研究和构建的是一种特殊算法(而非某一个特定的算法),能够让计算机自己在数据中学习从而进行预测。
所以,机器学习不是某种具体的算法,而是很多算法的统称。
机器学习包含了很多种不同的算法,深度学习就是其中之一,其他方法包括决策树,聚类,贝叶斯等。
深度学习的灵感来自大脑的结构和功能,即许多神经元的互连。人工神经网络(ANN)是模拟大脑生物结构的算法。
不管是机器学习还是深度学习,都属于人工智能(AI)的范畴。所以人工智能、机器学习、深度学习可以用下面的图来表示:

详细了解人工智能:《「2019更新」什么是人工智能?(AI的本质+发展史+局限性)》
详细了解深度学习:《一文看懂深度学习(白话解释+8个优缺点+4个典型算法)》


什么是机器学习?
在解释机器学习的原理之前,先把最精髓的基本思路介绍给大家,理解了机器学习最本质的东西,就能更好的利用机器学习,同时这个解决问题的思维还可以用到工作和生活中。
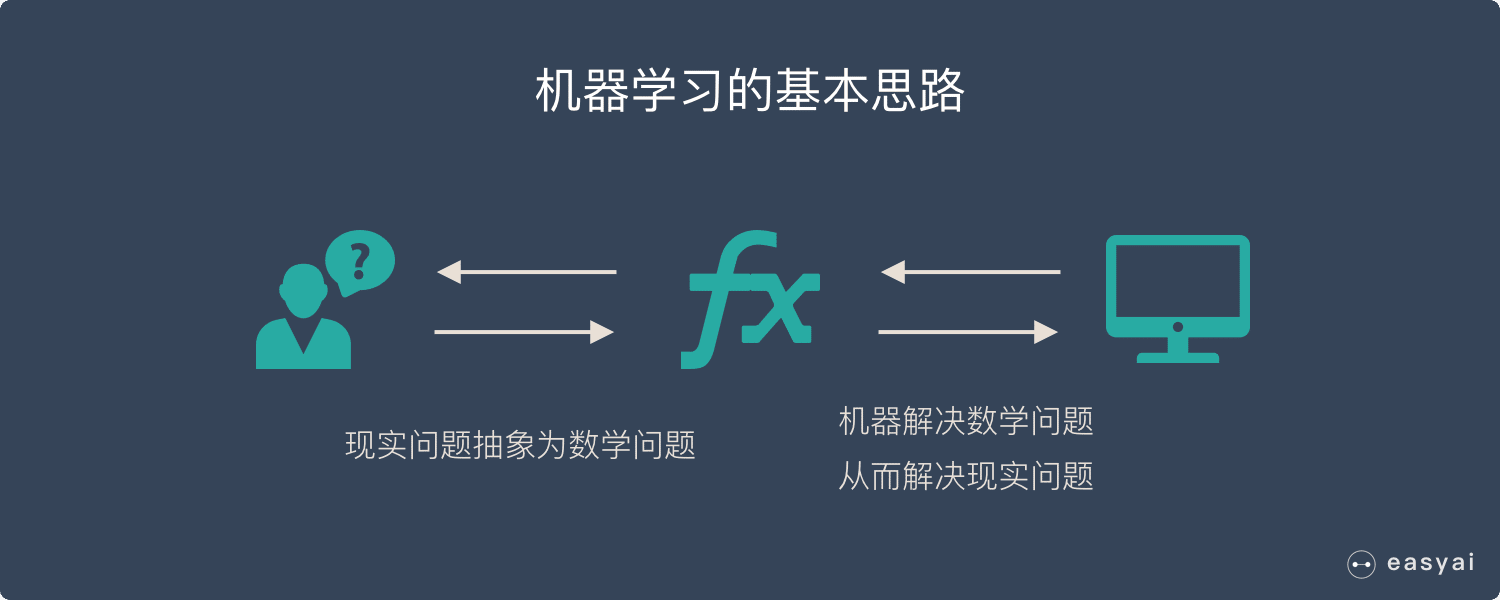
机器学习的基本思路
- 把现实生活中的问题抽象成数学模型,并且很清楚模型中不同参数的作用
- 利用数学方法对这个数学模型进行求解,从而解决现实生活中的问题
- 评估这个数学模型,是否真正的解决了现实生活中的问题,解决的如何?
无论使用什么算法,使用什么样的数据,最根本的思路都逃不出上面的3步!
当我们理解了这个基本思路,我们就能发现:
不是所有问题都可以转换成数学问题的。那些没有办法转换的现实问题 AI 就没有办法解决。同时最难的部分也就是把现实问题转换为数学问题这一步。
机器学习的原理
下面以监督学习为例,给大家讲解一下机器学习的实现原理。
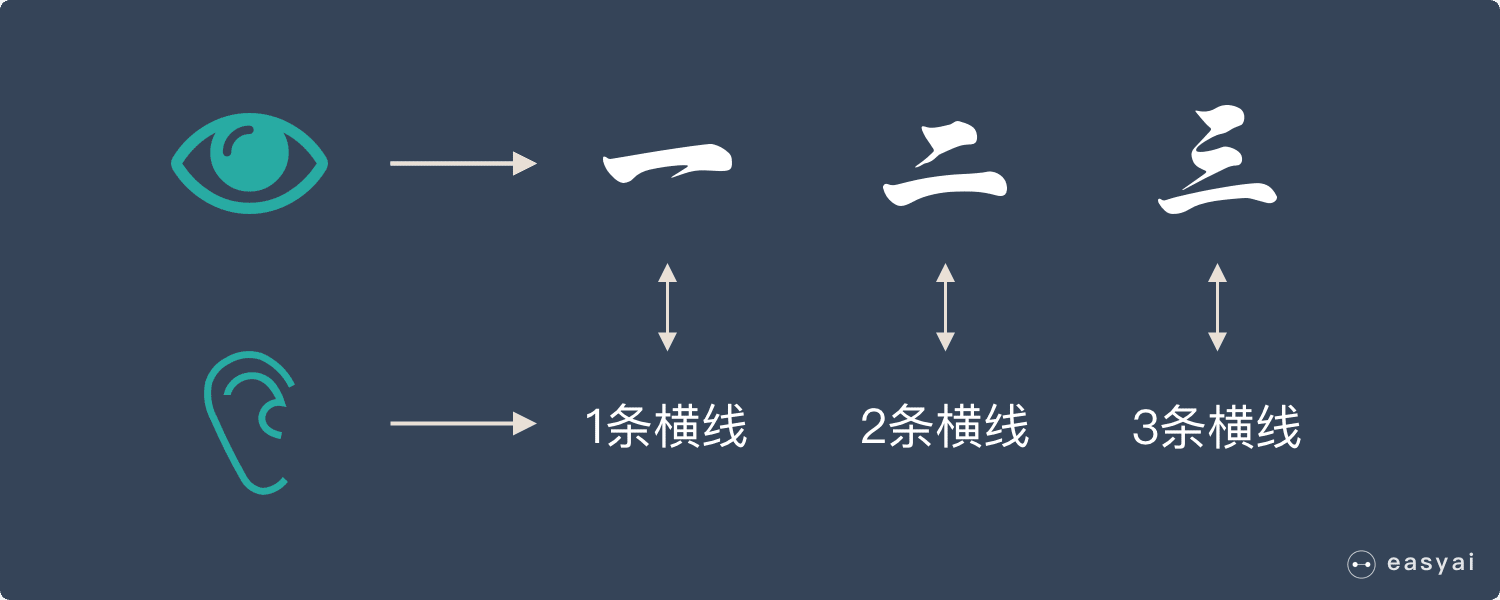
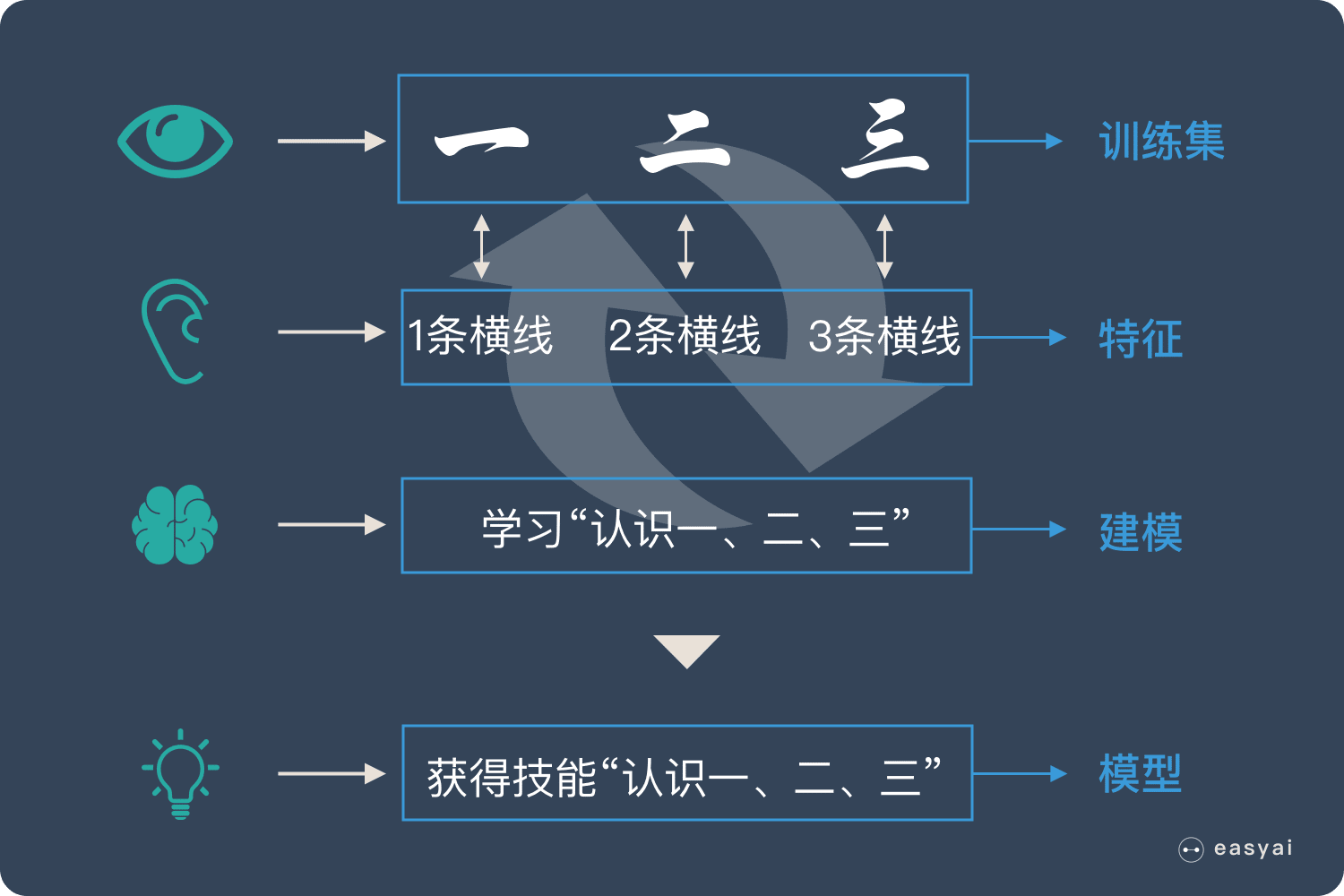
假如我们正在教小朋友识字(一、二、三)。我们首先会拿出3张卡片,然后便让小朋友看卡片,一边说“一条横线的是一、两条横线的是二、三条横线的是三”。
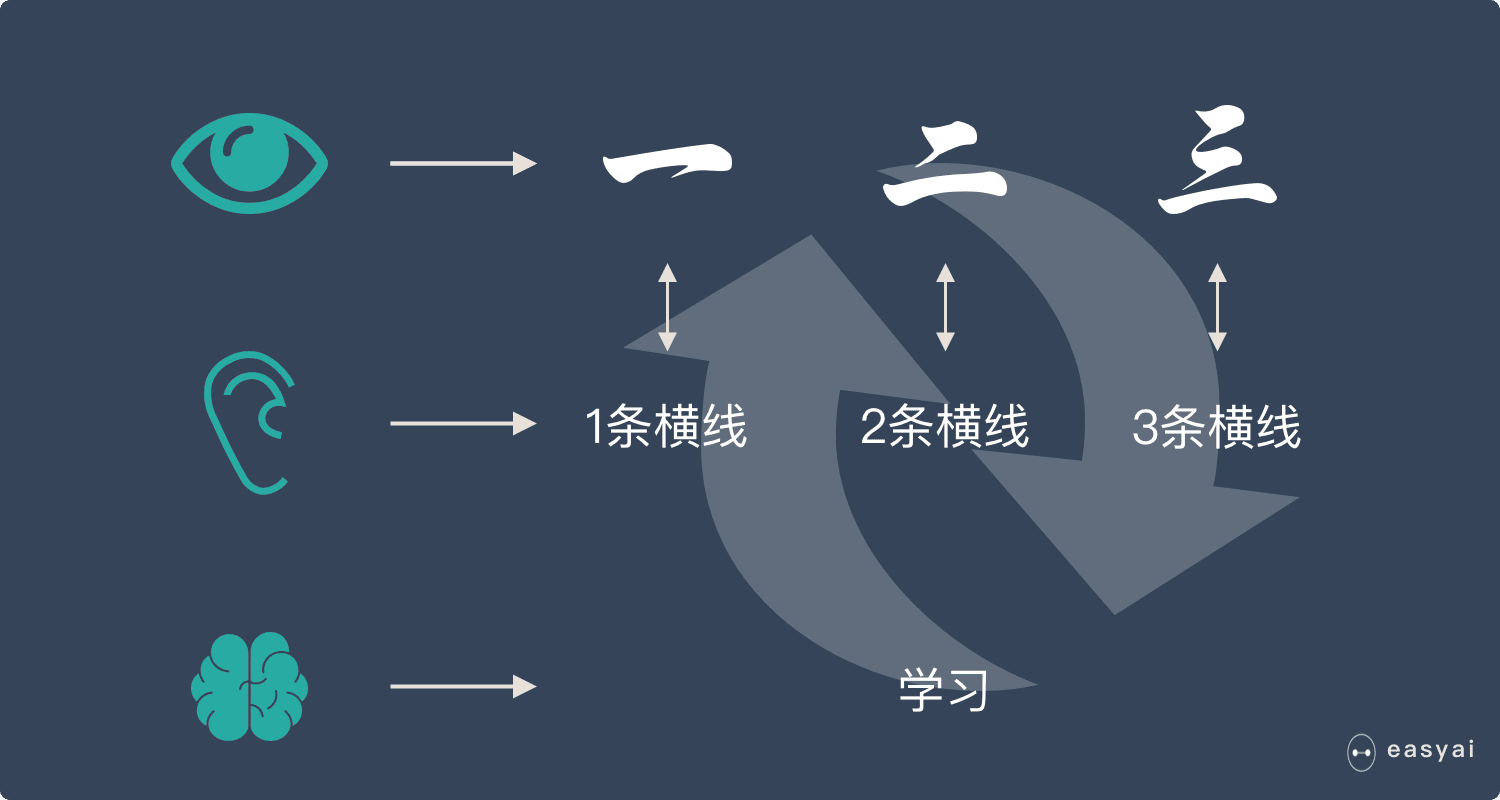
不断重复上面的过程,小朋友的大脑就在不停的学习。

当重复的次数足够多时,小朋友就学会了一个新技能——认识汉字:一、二、三。
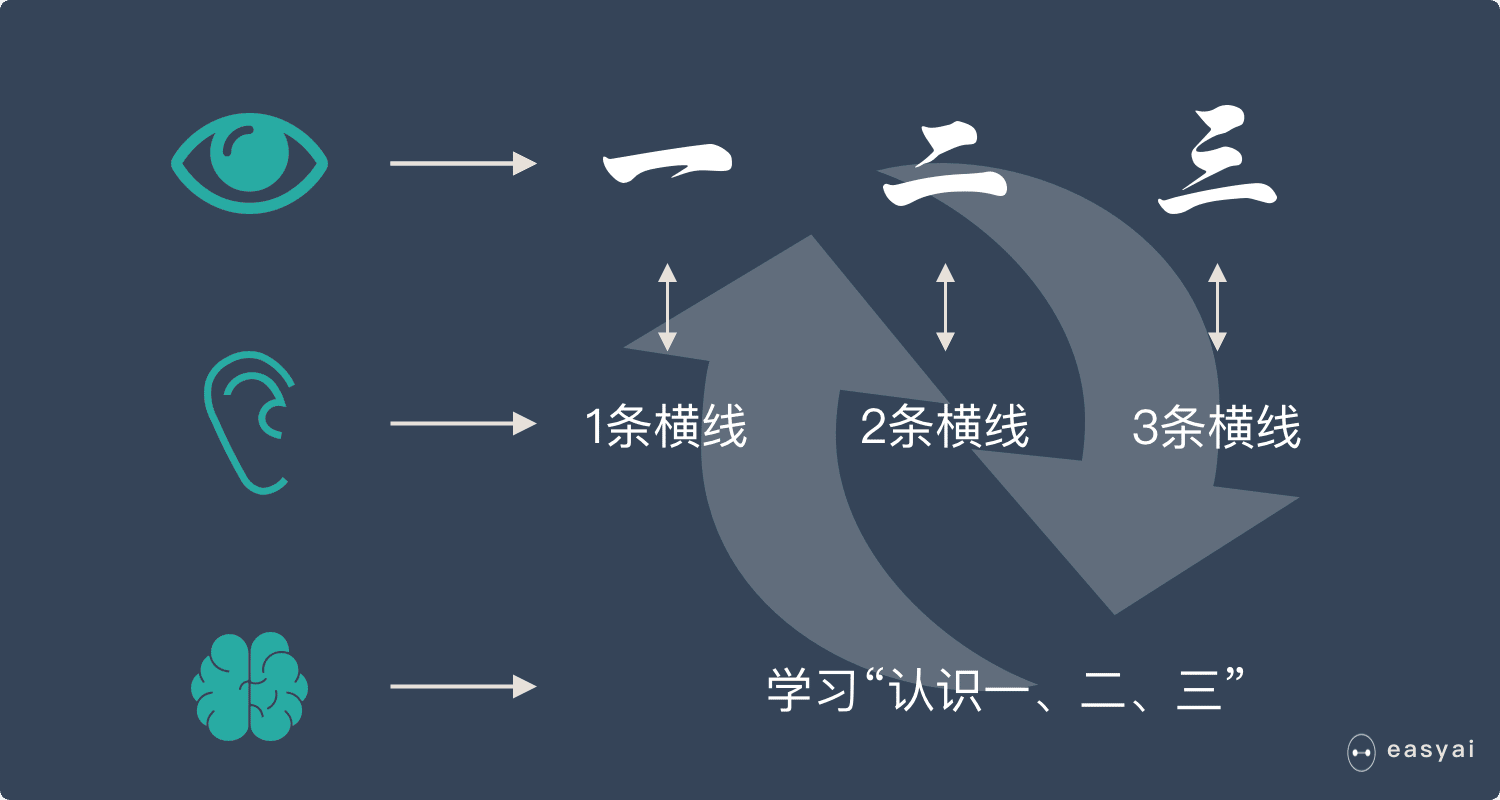
我们用上面人类的学习过程来类比机器学习。机器学习跟上面提到的人类学习过程很相似。
- 上面提到的认字的卡片在机器学习中叫——训练集
- 上面提到的“一条横线,两条横线”这种区分不同汉字的属性叫——特征
- 小朋友不断学习的过程叫——建模
- 学会了识字后总结出来的规律叫——模型
通过训练集,不断识别特征,不断建模,最后形成有效的模型,这个过程就叫“机器学习”!

监督学习、非监督学习、强化学习
机器学习根据训练方法大致可以分为3大类:
- 监督学习
- 非监督学习
- 强化学习
除此之外,大家可能还听过“半监督学习”之类的说法,但是那些都是基于上面3类的变种,本质没有改变。
监督学习
监督学习是指我们给算法一个数据集,并且给定正确答案。机器通过数据来学习正确答案的计算方法。
举个栗子:
我们准备了一大堆猫和狗的照片,我们想让机器学会如何识别猫和狗。当我们使用监督学习的时候,我们需要给这些照片打上标签。
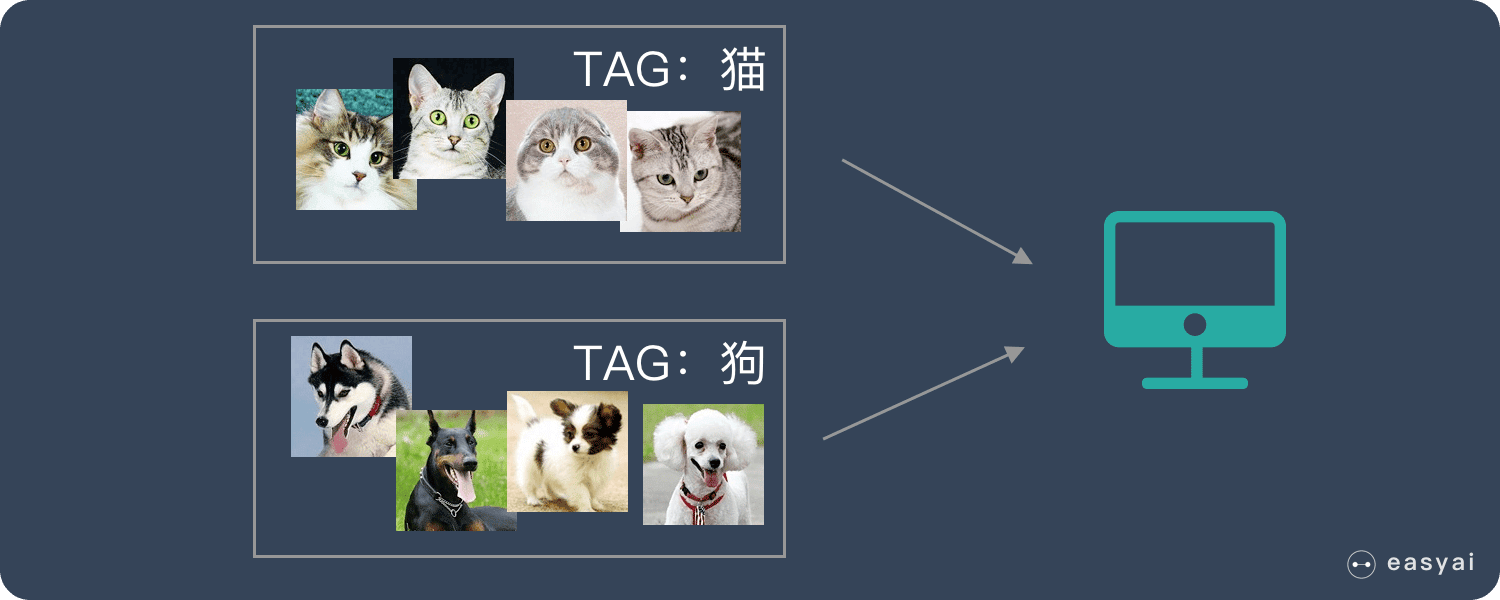
我们给照片打的标签就是“正确答案”,机器通过大量学习,就可以学会在新照片中认出猫和狗。
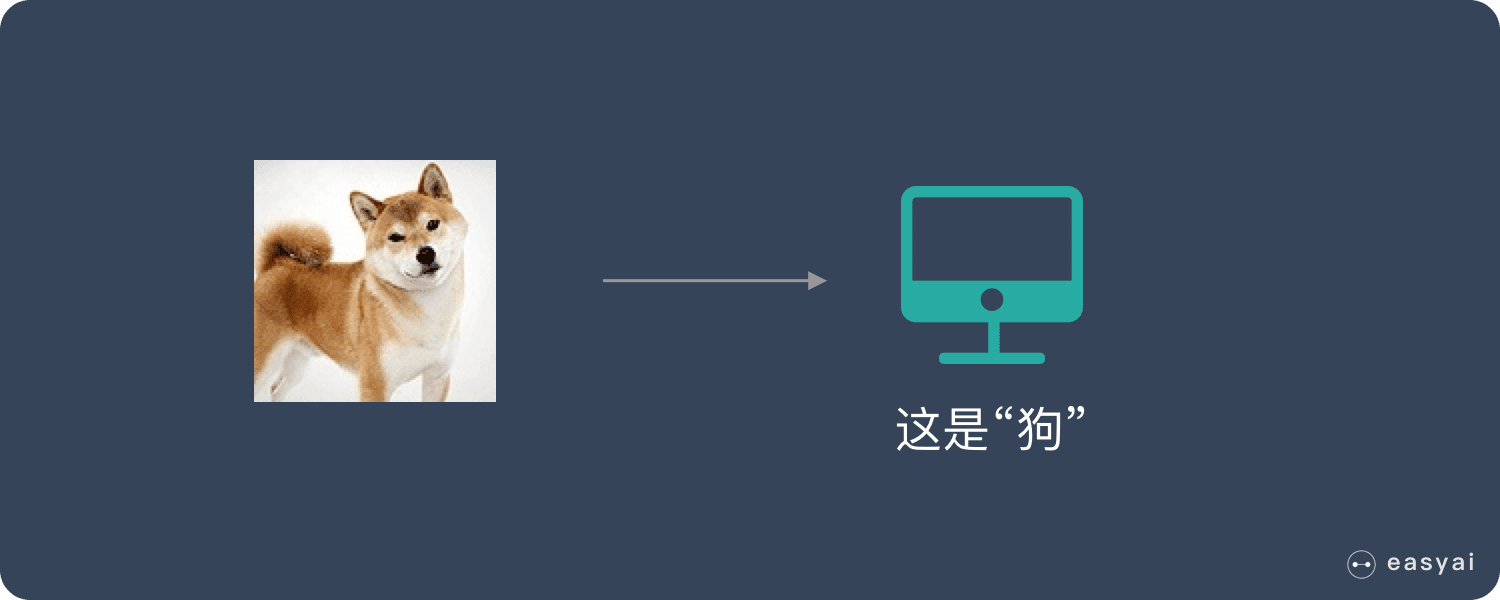
这种通过大量人工打标签来帮助机器学习的方式就是监督学习。这种学习方式效果非常好,但是成本也非常高。
了解更多关于 监督学习
非监督学习
非监督学习中,给定的数据集没有“正确答案”,所有的数据都是一样的。无监督学习的任务是从给定的数据集中,挖掘出潜在的结构。
举个栗子:
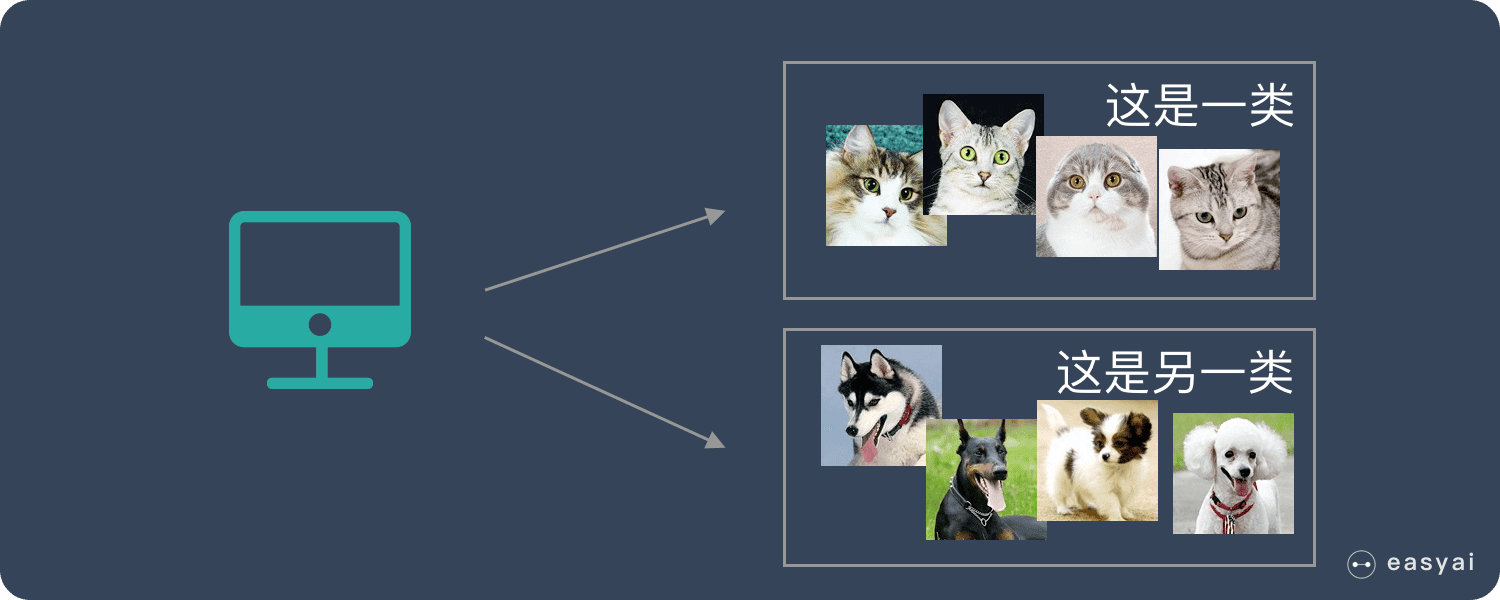
我们把一堆猫和狗的照片给机器,不给这些照片打任何标签,但是我们希望机器能够将这些照片分分类。

通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
非监督学习中,虽然照片分为了猫和狗,但是机器并不知道哪个是猫,哪个是狗。对于机器来说,相当于分成了 A、B 两类。
强化学习
强化学习更接近生物学习的本质,因此有望获得更高的智能。它关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。通过强化学习,一个智能体应该知道在什么状态下应该采取什么行为。
最典型的场景就是打游戏。
2019年1月25日,AlphaStar(Google 研发的人工智能程序,采用了强化学习的训练方式) 完虐星际争霸的职业选手职业选手“TLO”和“MANA”。新闻链接
了解更多关于 强化学习
机器学习实操的7个步骤
通过上面的内容,我们对机器学习已经有一些模糊的概念了,这个时候肯定会特别好奇:到底怎么使用机器学习?
机器学习在实际操作层面一共分为7步:
- 收集数据
- 数据准备
- 选择一个模型
- 训练
- 评估
- 参数调整
- 预测(开始使用)

假设我们的任务是通过酒精度和颜色来区分红酒和啤酒,下面详细介绍一下机器学习中每一个步骤是如何工作的。

步骤1:收集数据
我们在超市买来一堆不同种类的啤酒和红酒,然后再买来测量颜色的光谱仪和用于测量酒精度的设备。
这个时候,我们把买来的所有酒都标记出他的颜色和酒精度,会形成下面这张表格。
| 颜色 | 酒精度 | 种类 |
|---|---|---|
| 610 | 5 | 啤酒 |
| 599 | 13 | 红酒 |
| 693 | 14 | 红酒 |
| … | … | … |
这一步非常重要,因为数据的数量和质量直接决定了预测模型的好坏。
步骤2:数据准备
在这个例子中,我们的数据是很工整的,但是在实际情况中,我们收集到的数据会有很多问题,所以会涉及到数据清洗等工作。
当数据本身没有什么问题后,我们将数据分成3个部分:训练集(60%)、验证集(20%)、测试集(20%),用于后面的验证和评估工作。

关于数据准备部分,还有非常多的技巧,感兴趣的可以看看《AI 数据集最常见的6大问题(附解决方案)》
步骤3:选择一个模型
研究人员和数据科学家多年来创造了许多模型。有些非常适合图像数据,有些非常适合于序列(如文本或音乐),有些用于数字数据,有些用于基于文本的数据。
在我们的例子中,由于我们只有2个特征,颜色和酒精度,我们可以使用一个小的线性模型,这是一个相当简单的模型。
步骤4:训练
大部分人都认为这个是最重要的部分,其实并非如此~ 数据数量和质量、还有模型的选择比训练本身重要更多(训练知识台上的3分钟,更重要的是台下的10年功)。
这个过程就不需要人来参与的,机器独立就可以完成,整个过程就好像是在做算术题。因为机器学习的本质就是将问题转化为数学问题,然后解答数学题的过程。
步骤5:评估
一旦训练完成,就可以评估模型是否有用。这是我们之前预留的验证集和测试集发挥作用的地方。评估的指标主要有 准确率、召回率、F值。
这个过程可以让我们看到模型如何对尚未看到的数是如何做预测的。这意味着代表模型在现实世界中的表现。
步骤6:参数调整
完成评估后,您可能希望了解是否可以以任何方式进一步改进训练。我们可以通过调整参数来做到这一点。当我们进行训练时,我们隐含地假设了一些参数,我们可以通过认为的调整这些参数让模型表现的更出色。
步骤7:预测
我们上面的6个步骤都是为了这一步来服务的。这也是机器学习的价值。这个时候,当我们买来一瓶新的酒,只要告诉机器他的颜色和酒精度,他就会告诉你,这时啤酒还是红酒了。


YouTube 上有一个视频介绍了这7个步骤 The 7 Steps of Machine Learning(需要科学上网)
15种经典机器学习算法
| 训练方式 | |
|---|---|
| 线性回归 | 监督学习 |
| 逻辑回归 | 监督学习 |
| 线性判别分析 | 监督学习 |
| 决策树 | 监督学习 |
| 朴素贝叶斯 | 监督学习 |
| K邻近 | 监督学习 |
| 学习向量量化 | 监督学习 |
| 支持向量机 | 监督学习 |
| 随机森林 | 监督学习 |
| AdaBoost | 监督学习 |
| 高斯混合模型 | 非监督学习 |
| 限制波尔兹曼机 | 非监督学习 |
| K-means 聚类 | 非监督学习 |
| 最大期望算法 | 非监督学习 |
百度百科+维基百科
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
机器学习是利用计算机算法和统计模型是计算机系统使用,逐步提高完成特定任务的能力。
机器学习建立样本数据的数学模型,称为“ 训练数据 ”,以便在不明确编程以执行任务的情况下进行预测或决策。机器学习算法用于电子邮件过滤,网络入侵者检测和计算机视觉的应用,开发用于执行任务的特定指令的算法是不可行的。机器学习与计算统计密切相关,计算统计侧重于使用计算机进行预测。数学优化的研究为机器学习领域提供了方法,理论和应用领域。数据挖掘是机器学习中的一个研究领域,侧重于通过无监督学习进行探索性数据分析。在跨业务问题的应用中,机器学习也被称为预测分析。