

自然语言生成 – NLG 是 NLP 的重要组成部分,他的主要目的是降低人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式。
本文除了介绍 NLG 的基本概念,还会介绍 NLG 的3个 Level、6个步骤和3个典型的应用。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 NLG?
NLG 是 NLP 的一部分
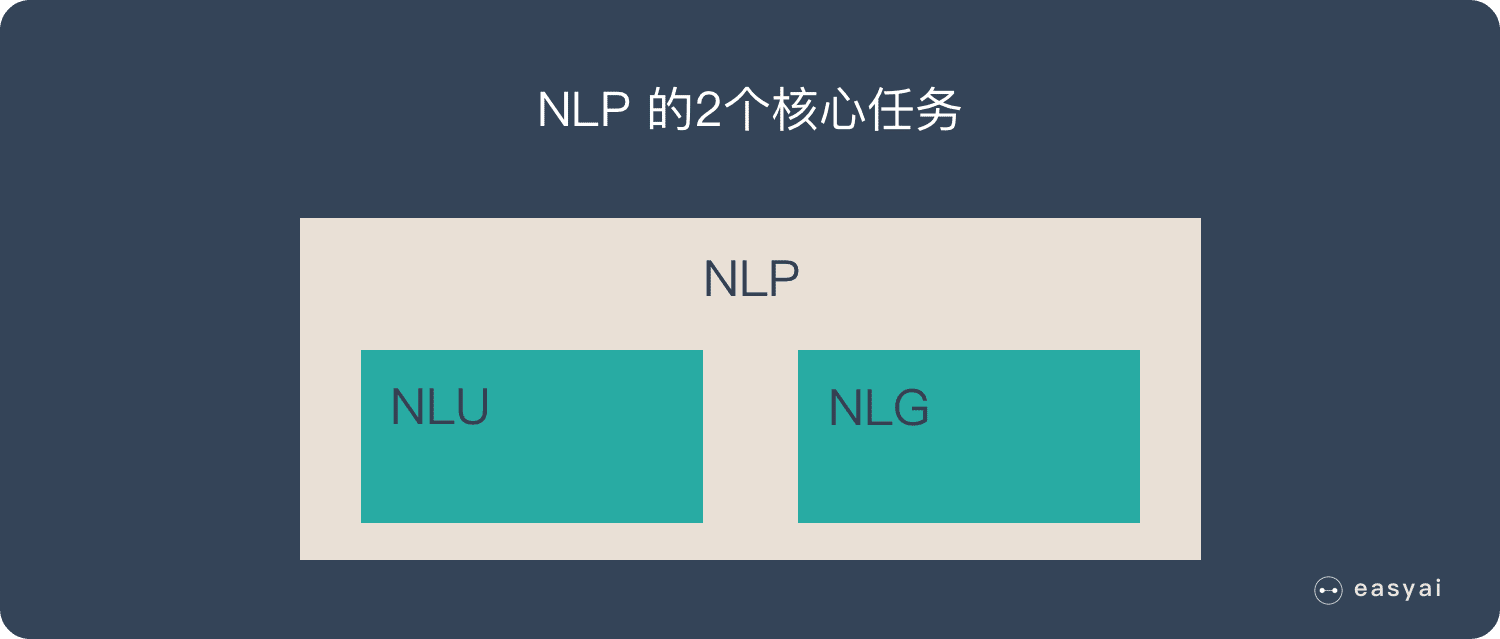
NLP = NLU + NLG
自然语言生成 – NLG 是 NLP 的重要组成部分。NLU 负责理解内容,NLG 负责生成内容。
以智能音箱为例,当用户说“几点了?”,首先需要利用 NLU 技术判断用户意图,理解用户想要什么,然后利用 NLG 技术说出“现在是6点50分”。
自然语言生成 – NLG 是什么?

NLG 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
自然语言生成 – NLG 有2种方式:
- text – to – text:文本到语言的生成
- data – to – text :数据到语言的生成
NLG 的3个 Level

简单的数据合并:自然语言处理的简化形式,这将允许将数据转换为文本(通过类似Excel的函数)。为了关联,以邮件合并(MS Word mailmerge)为例,其中间隙填充了一些数据,这些数据是从另一个源(例如MS Excel中的表格)中检索的。
模板化的 NLG :这种形式的NLG使用模板驱动模式来显示输出。以足球比赛得分板为例。数据动态地保持更改,并由预定义的业务规则集(如if / else循环语句)生成。

高级 NLG :这种形式的自然语言生成就像人类一样。它理解意图,添加智能,考虑上下文,并将结果呈现在用户可以轻松阅读和理解的富有洞察力的叙述中。
NLG 的6个步骤

第一步:内容确定 – Content Determination
作为第一步,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 – Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达「什么时间」「什么地点」「哪2支球队」,然后再表达「比赛的概况」,最后表达「比赛的结局」。
第三步:句子聚合 – Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 – Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 – Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
NLG 的3种典型应用
NLG 的不管如何应用,大部分都是下面的3种目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产
下面给大家列一些比较典型的应用:

自动写新闻
某些领域的新闻是有比较明显的规则的,比如体育新闻。目前很多新闻已经借助 NLG 来完成了。
聊天机器人
大家了解聊天机器人都是从 Siri 开始的,最近几年又出现了智能音箱的热潮。
除了大家日常生活中很熟悉的领域,客服工作也正在被机器人替代,甚至一些电话客服也是机器人。

BI 的解读和报告生成
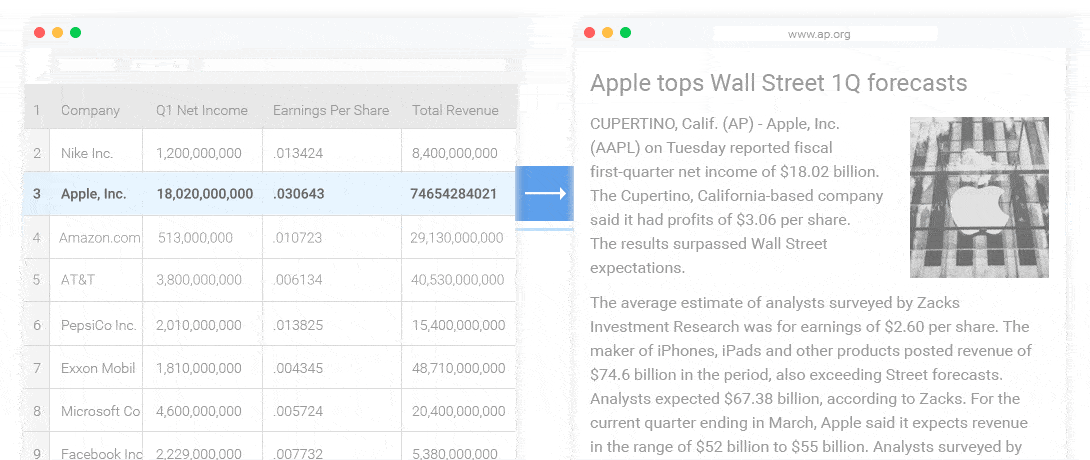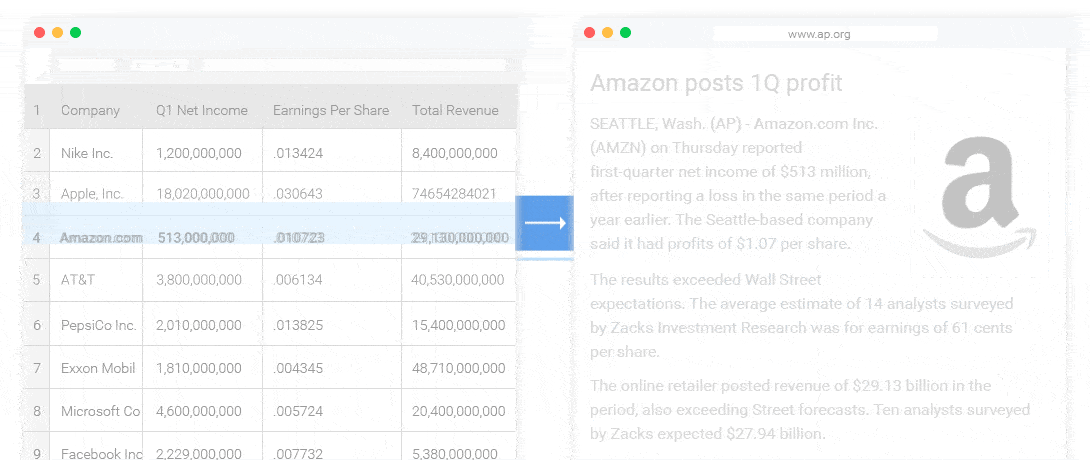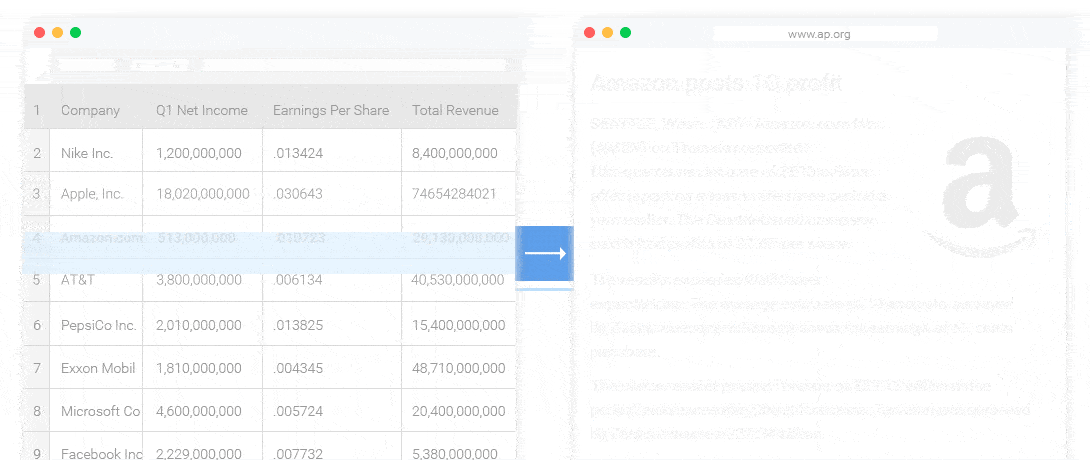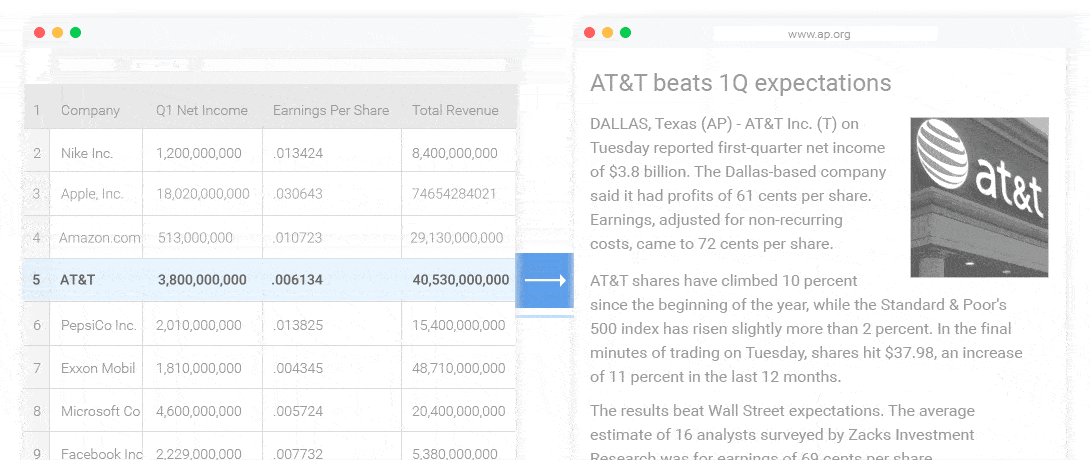
几乎各行各业都有自己的数据统计和分析工具。这些工具可以产生各式各样的图表,但是输出结论和观点还是需要依赖人。NLG 的一个很重要的应用就是解读这些数据,自动的输出结论和观点。(如下图所示)

总结
自然语言生成 – NLG 是 NLP 的重要组成部分,他的主要目的是降低人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式。
NLG 的3个level:
- 简单的数据合并
- 模块化的 NLG
- 高级 NLG
NLG 的6个步骤:
- 内容确定 – Content Determination
- 文本结构 – Text Structuring
- 句子聚合 – Sentence Aggregation
- 语法化 – Lexicalisation
- 参考表达式生成 – Referring Expression Generation|REG
- 语言实现 – Linguistic Realisation
NLG 应用的3个目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产
NLG 的3个典型应用:
- 自动写新闻
- 聊天机器人
- BI 的解读和报告生成
百度百科版本+维基百科
自然语言生成是研究使计算机具有人一样的表达和写作的功能。即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,来自动生成一段高质量的自然语言文本。
自然语言处理包括自然语言理解和自然语言生成。自然语言生成是人工智能和计算语言学的分支,相应的语言生成系统是基于语言信息处理的计算机模型,其工作过程与自然语言分析相反,是从抽象的概念层次开始,通过选择并执行一定的语义和语法规则来生成文本。
自然语言生成(NLG)是语言技术的一个方面,侧重于从结构化数据或结构化表示(如知识库或逻辑形式)生成自然语言。当这种形式表征被解释为心理表征的模型时,心理语言学家更喜欢语言生成这个术语。
可以说一个NLG系统就像一个翻译器将数据转换成自然语言表示。然而,由于自然语言的固有表现力,产生最终语言的方法与编译器的方法不同。NLG已经存在了很长时间,但商业NLG技术最近才被广泛使用。
2 Comments
我合理怀疑这篇文章也是机器人写的
去看看发布的时间吧