说明:以下内容并非原创,由开发者提供,纯免费帮忙,不为产品背书。
据调查显示,使用思维导图的产品经理更有可能在职场上脱颖而出,成功率高达80%!
在这个信息爆炸的时代,如何高效地组织、整理、挖掘和应用知识,成为每一位产品经理所面临的挑战。
面对这一挑战,思维导图成为了大厂经理们高薪的秘密武器。
而TreeMind树图就是思维导图中的加速器,搭载媲美GPT的人工智能大模型,AI一句话即可生成逻辑清晰、层级分明的思维导图,让产品经理的工作更轻松。
一、产品简介
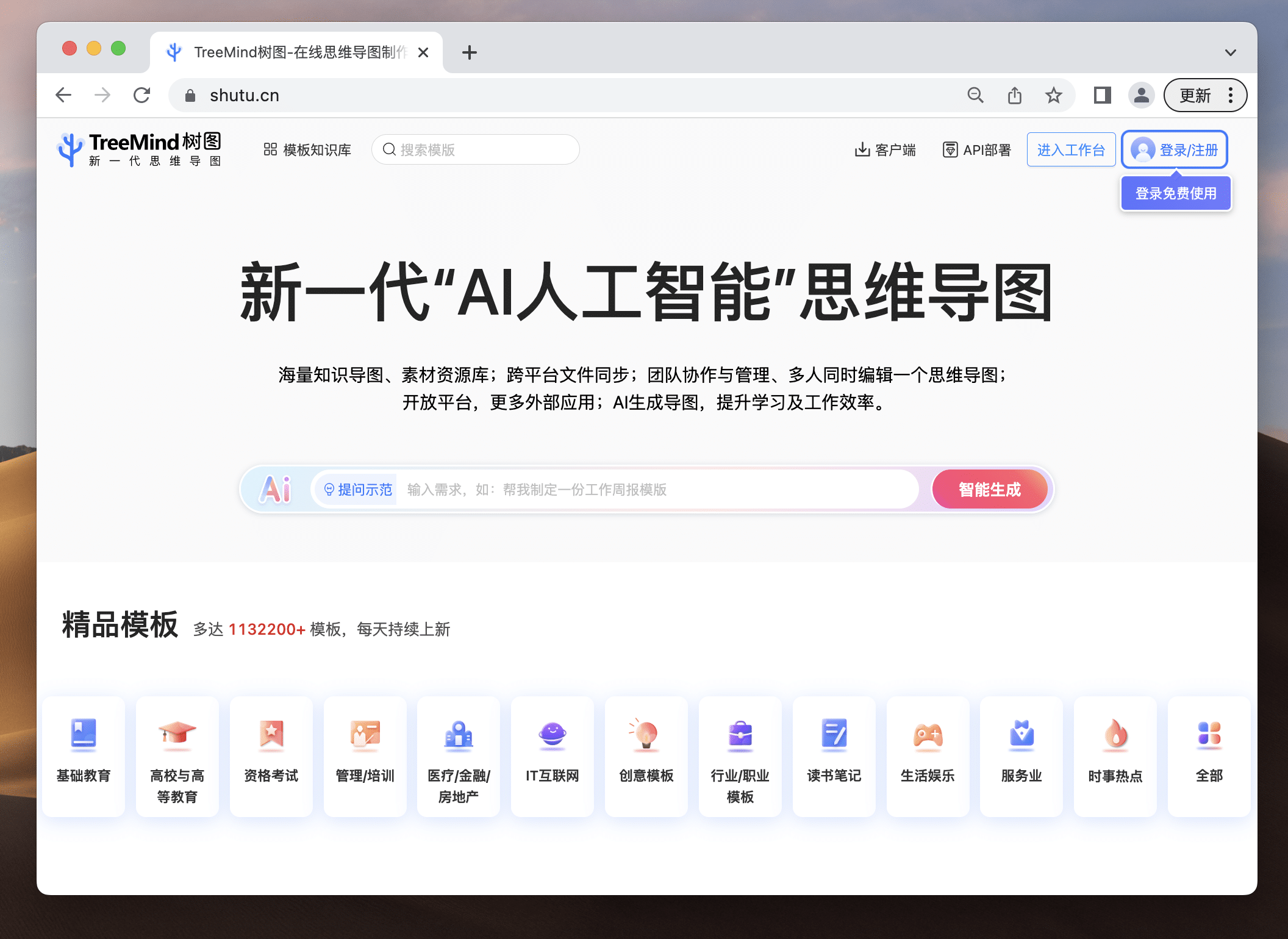
作为首批「AIGC+思维导图」平台,TreeMind树图一句话即可生成详实的思维导图,开启了AI生成思维导图新时代,能够快速提升你的学习和工作效率。还有上百万的模板,满足各行各业、不同细分领域需求,是真正思维导图届的“百科全书”。
戳这里体验:https://shutu.cn/?from=cpjldrgznxxk
二、9大核心功能
- AI一句话生成思维导图
- AI智能助手随时提问,生产力MAX
- 百万模板随心挑选 1,132,200模板,每天都在上新
- 丰富的素材类型 海量设计资源库
- 跨平台文件同步 随时随地可查看
- 团队空间 支持多人同时管理团队
- 脱离PPT 直接在树图演示
- 开放平台 接入更多外部应用
- 分屏模式 一屏完成读写绘图
……
三、特色介绍
1、AI一句话生成思维导图
从未做过思维导图的小白不知从哪开始?不要慌!提出需求,结合当下最火的ChatGPT,树图AI直接帮你一键生成定制化思维导图,并且还支持随意修改,新用户注册就送2000字的AI字数体验!免费的羊毛,你还不薅?
AI思维导图智能库功能齐全强大,不管你是工作汇报还是提炼读书笔记,就算是当下最火的视频脚本解析,它都能帮你准确生成,大大提高你的生活和工作效率!并且智能库还会不断更新,不会面临重复或内容过时的局面。生成的思维导图不限节点增删,哪里需要改哪里!
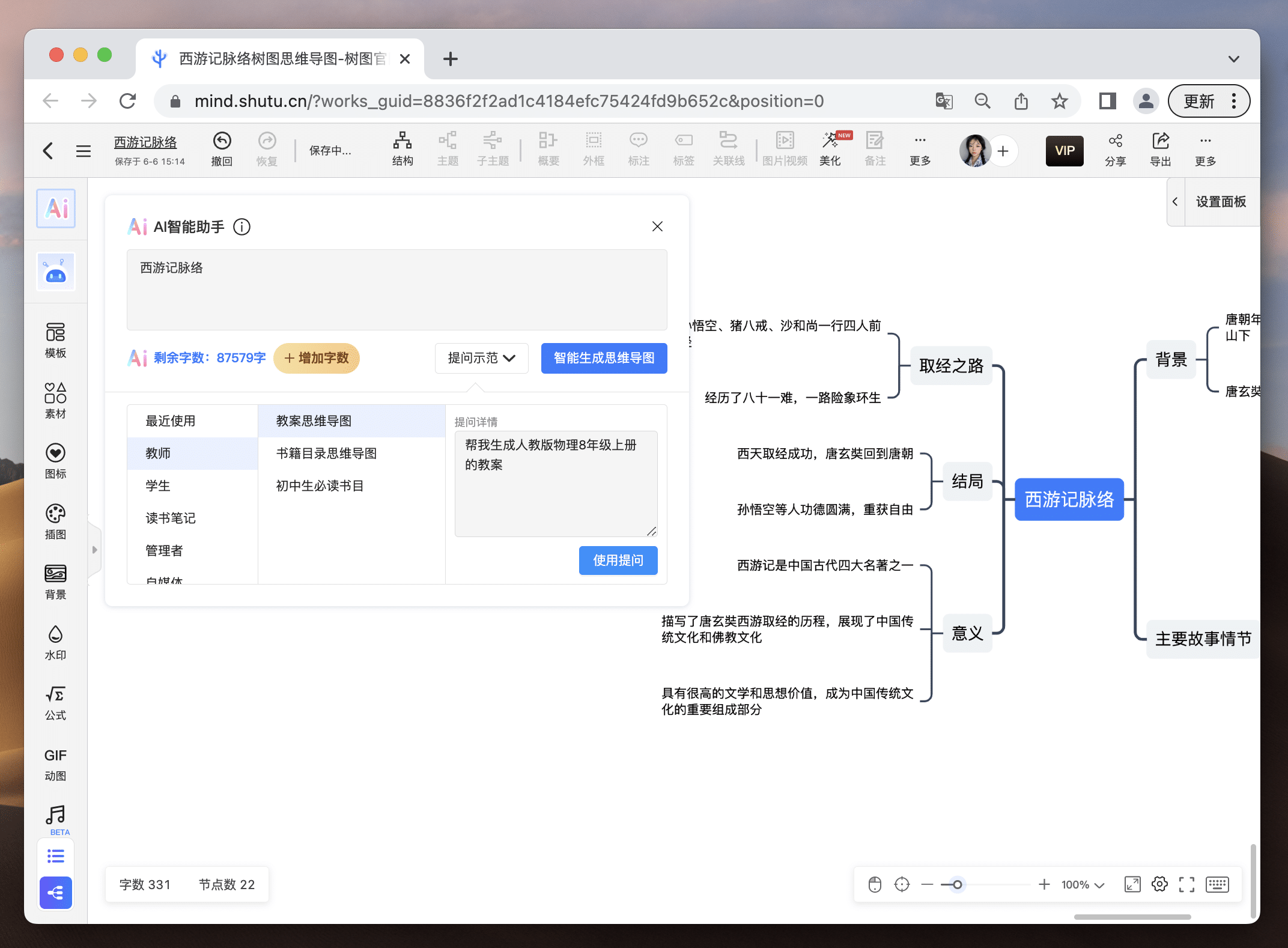
自己做的思维导图没有灵感?你还能让AI参考你的思路继续扩写,拒绝灵感枯竭!让你站在巨人的肩膀开阔眼界,让你的思维和灵感立刻涌现。
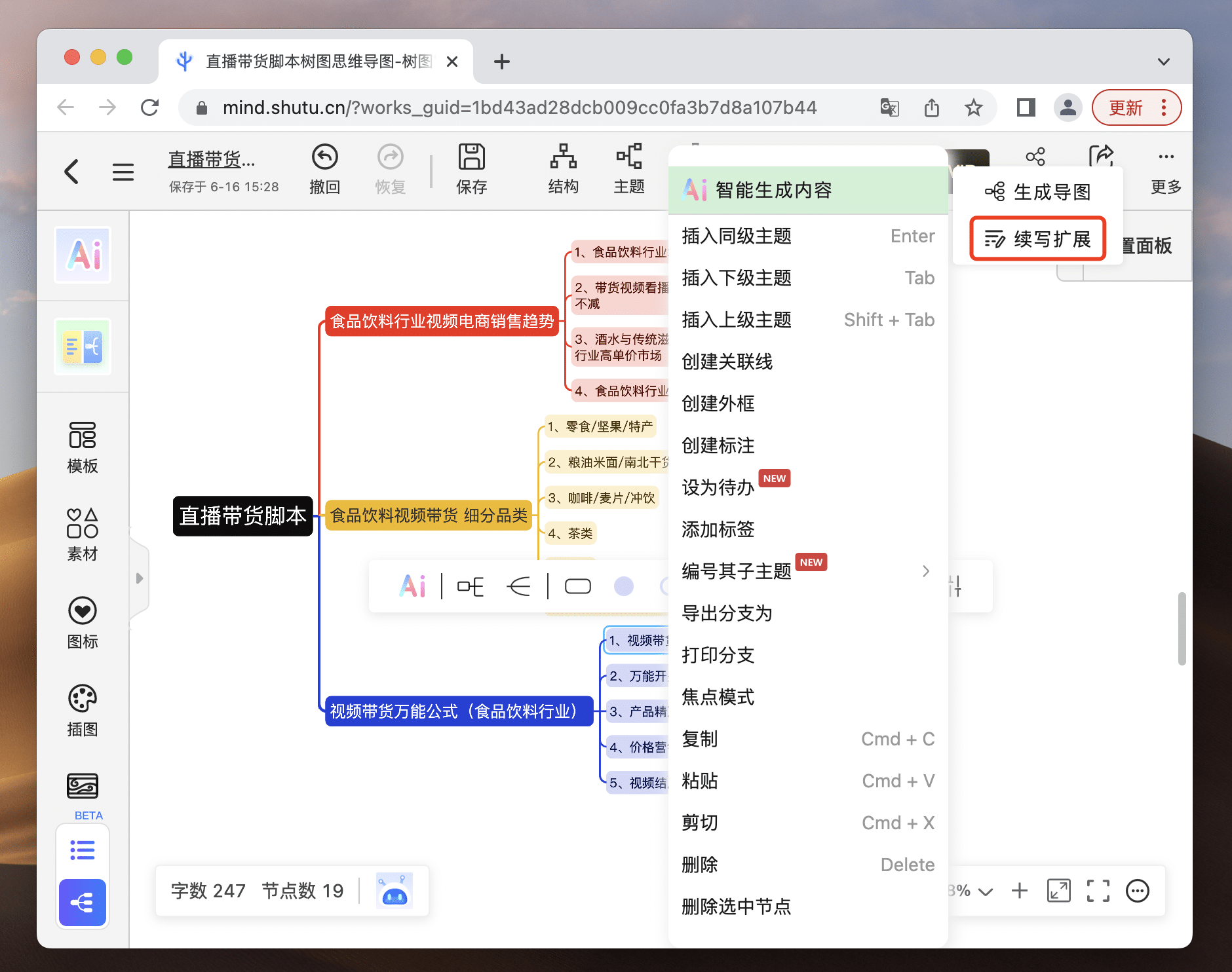
2、应用场景广泛
无论是需求整理、产品规划、市场分析、或者是团队沟通,只要涉及到信息的整理和传递,TreeMind树图都能为您提供极大的帮助。
- 需求整理:通过导图直观展示各个需求间的关系,帮助团队对产品的方向有更明确的认知。
- 产品规划:将产品的生命周期、功能模块、用户体验等要点一览无余地展现出来,方便团队参考和实施。
- 市场分析:结合AI技术,智能提取市场数据中的关键信息,生成直观的思维导图,助力产品经理迅速把握市场动态。
- 团队沟通:在会议或日常工作中,利用TreeMind树图实时记录、整理关键点,确保沟通效果。TreeMind树图甚至还能让您脱离PPT,直接用思维导图进行演示。
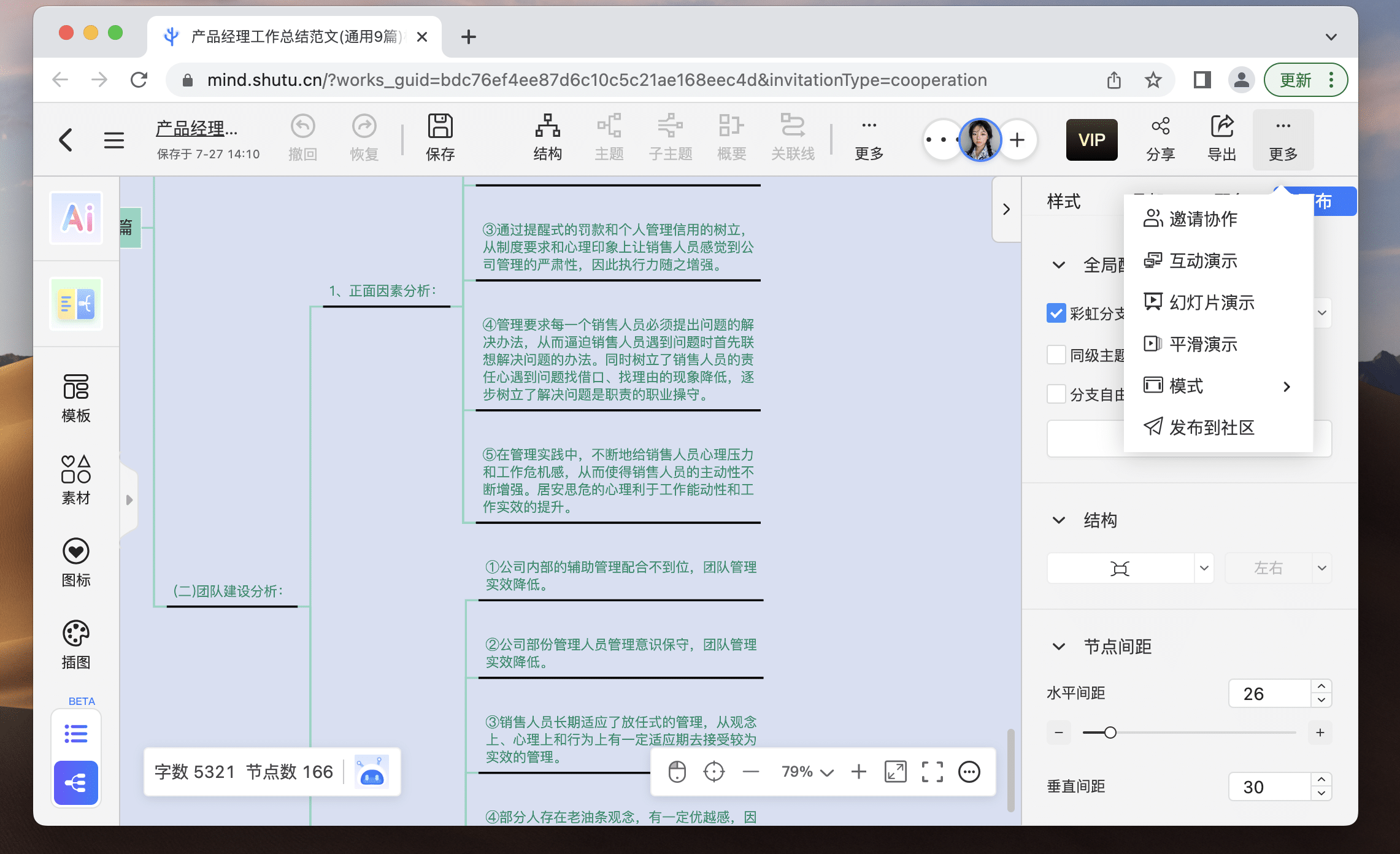
3、 百万模版免费用
将近150万+导图模板,每天都在上新!包含多达829个精选专辑、共计123个模板品类、覆盖12种行业类型,帮你释放创意无限潜力!无论你要做什么类型的思维导图,在TreeMind树图模版库99%能找到!直接在大佬的思维导图上进行修改,帮你开阔思路,成为思维导图高手。
4.分屏视图,一屏读写
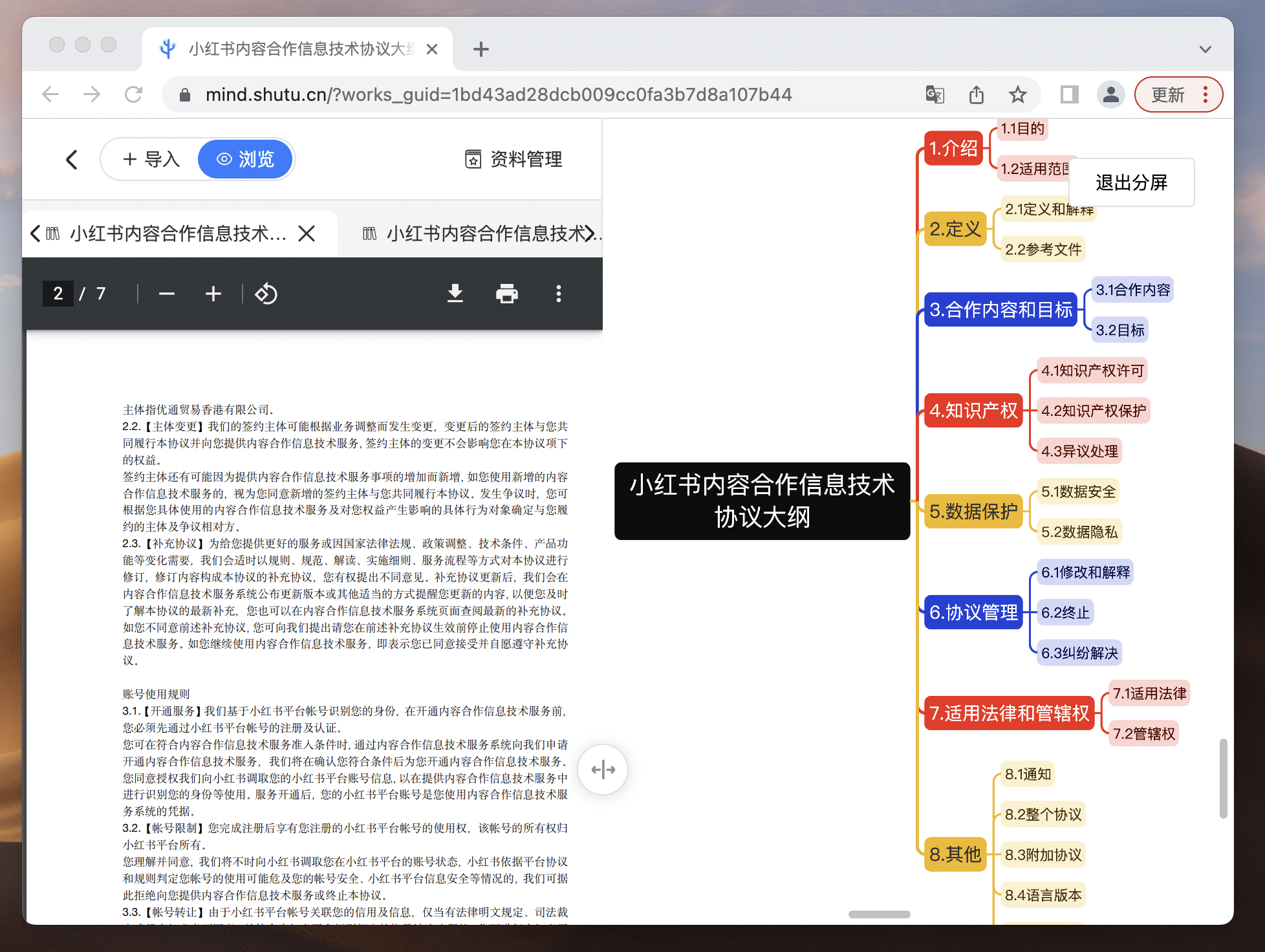
在绘制复杂思维导图时,参考大量资料是家常便饭,但频繁跳转窗口查看资料与编辑思维导图的传统方式实在低效。
一屏两用让你的读写模式so easy!一边阅读文件,一边制作思维导图,学习效果翻倍!资料上传支持3种导入方式:文件导入、粘贴导入、网址导入,支持PDF、Word、Txt三种文件格式,无需转换,直接参考!更棒的是,历史资料库自动备份,让你不再担心文件丢失!此外,我们还增加了窗口大小调节功能,随心调整界面,提供更舒适的学习环境!二者衔接,让你的导图绘制更加丝滑!
5、团队空间,多人协作
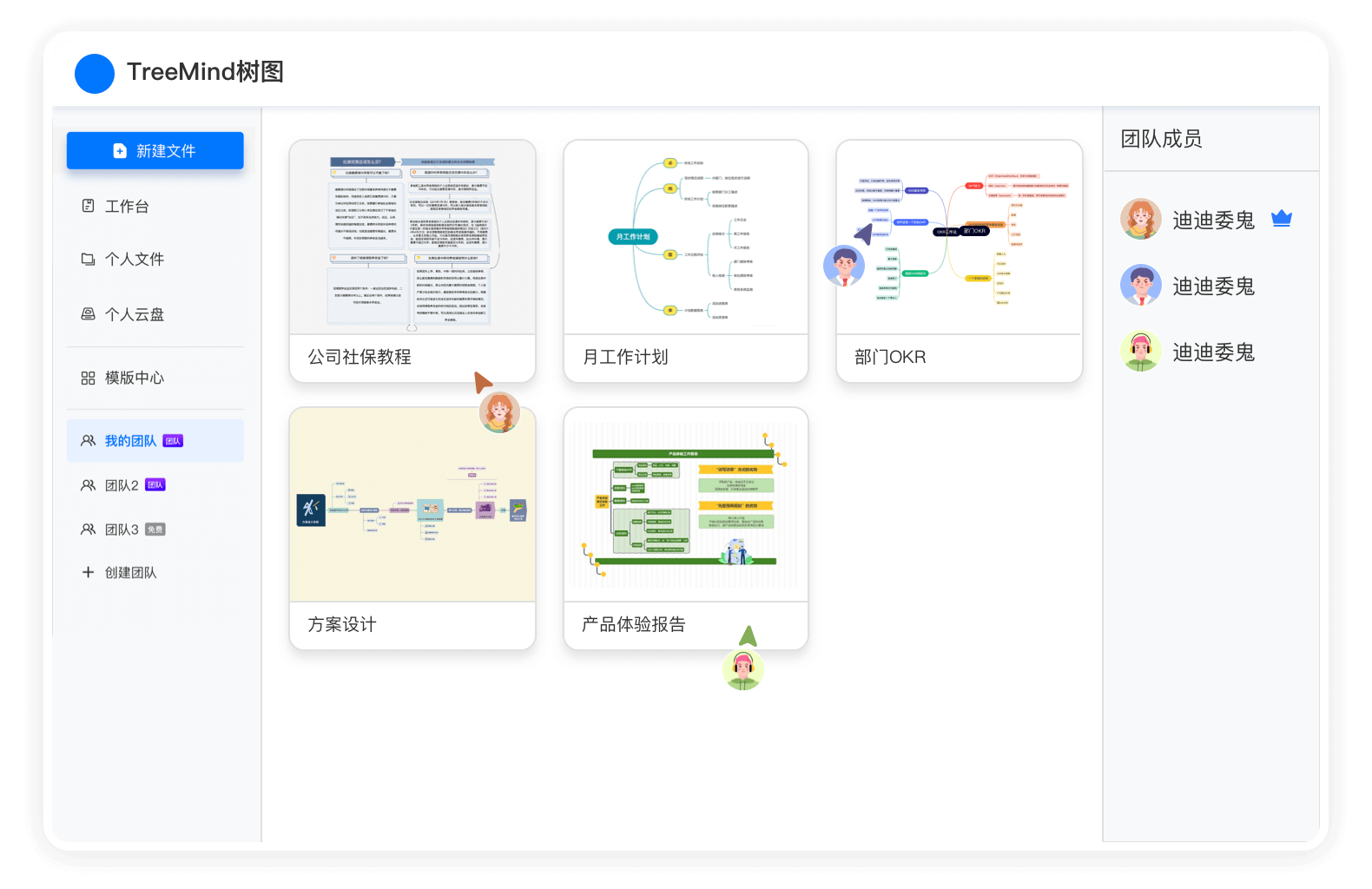
无论是特殊时期在家办公,还是多人协作完成一个方案/作业,都需要很方便地将自己的创作内容分享给同事,时不时也需要来一场多人头脑风暴,多人在线分工共同完成一个事情。传统的软件只能每人单独完成一份文件,最后将多人文件合并在一起,然后统一修改。
- 传统思维导图:导图文件或图片只能通过微信、钉钉、邮件等分享,内容更新后需再次分享;无法跟同学、同事,多人同时完成一个思维导图的制作;
- 新一代思维导图-TreeMind树图:多人同时编辑一个思维导图,可以在一张思维导图里头脑风暴、梳理思路。
6、云端跨平台化
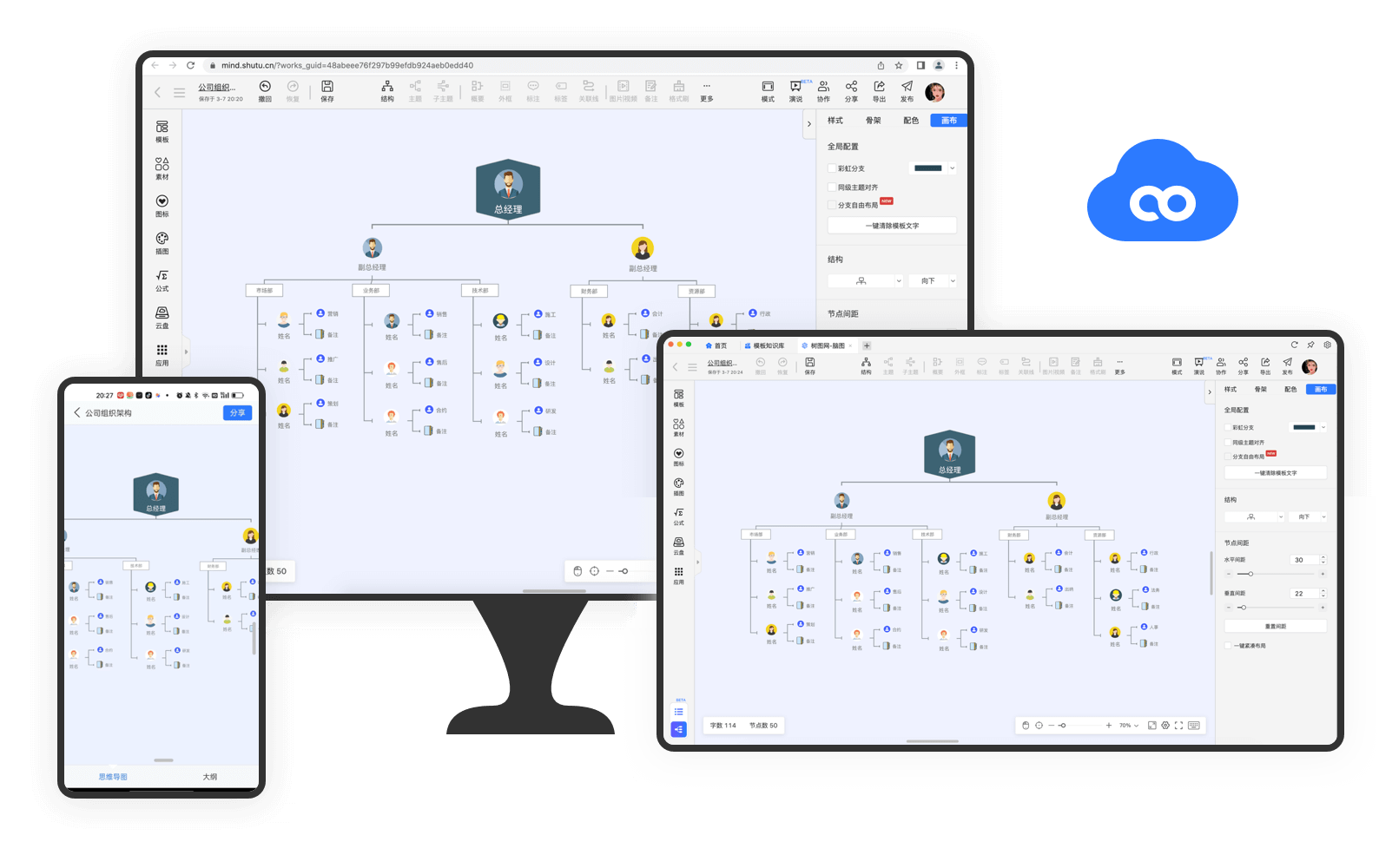
目前市面上的大多数思维导图软件,都需要下载安装客户端才能使用,要么占用电脑磁盘空间,要么就是浪费手机内存,最重要的是偶尔也会碰到盗版软件和流氓软件。TreeMind树图是一款在线思维导图工具,打开浏览器访问网站即可快速创建思维导图,让自己的灵感快速穿梭在思维导图的一个个节点上,学习力和生产力拉满。
同时TreeMind树图实现了「实时保存,内容可多平台文件同步」,再也不用担心忘记保存、软件崩溃导致内容丢失,让自己专注于内容创作和灵感爆发,不受其他干扰~在浏览器,客户端,手机端都可以修改和浏览文件。
7、免费够用,会员超值
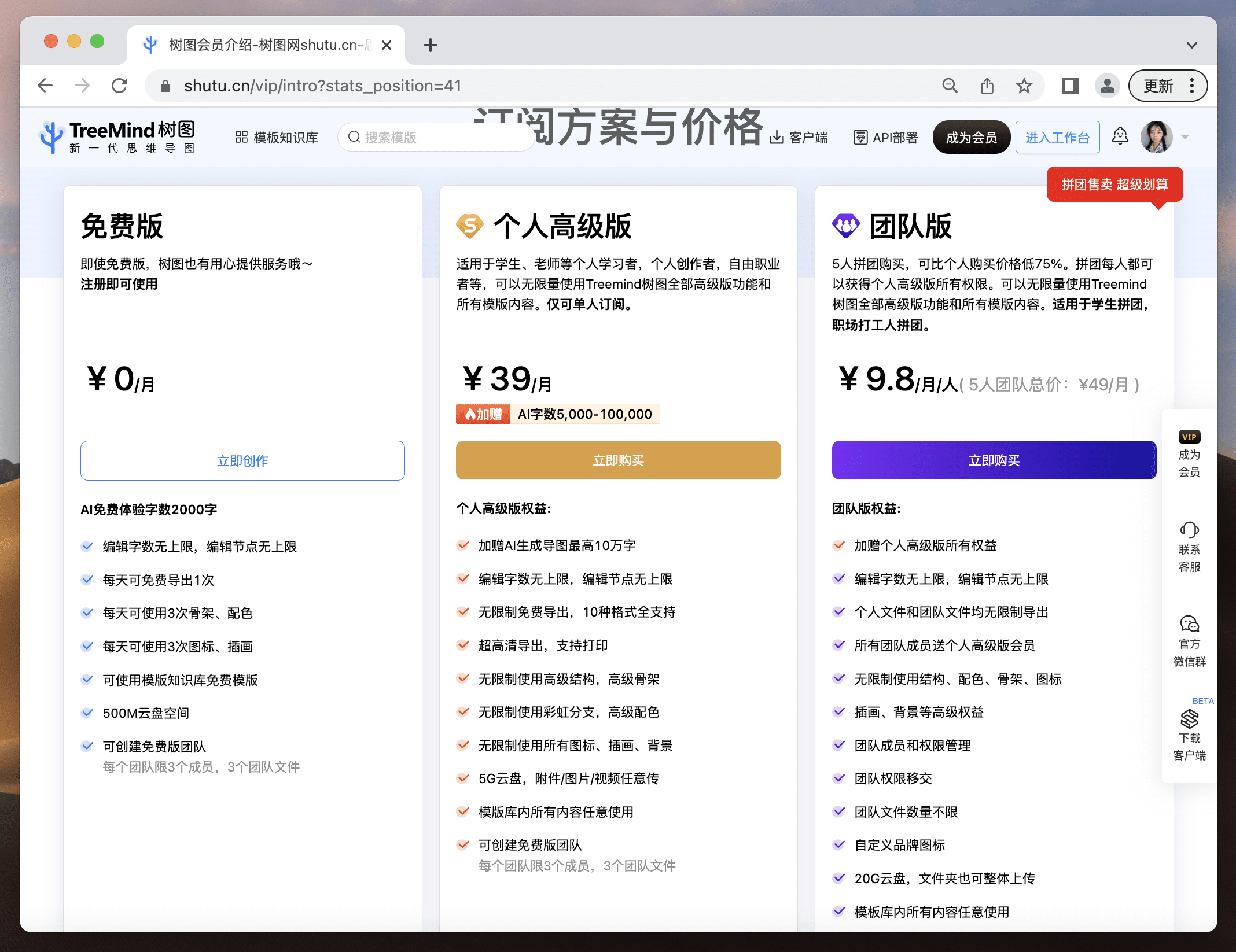
TreeMind树图的大部分权益都可以免费使用,对于刚接触思维导图的新手小白,TreeMind树图也提供了每日免费导出1次➕AI字数2000字的至尊体验;开通会员后更是可以解锁更多权益,成为思维导图届的大神!同事们一起拼团购买,还能享受到团队优惠价。
四、如何使用TreeMind树图?
1.想要AI一键生成:
打开网站在文字框内输入你的需求,AI就会自动生成一份相关的定制思维导图。
比如,我在这里输入:

让它以此帮我生成工作周报!只要输入主题,然后点击智能生成即可。结果如下图所示:
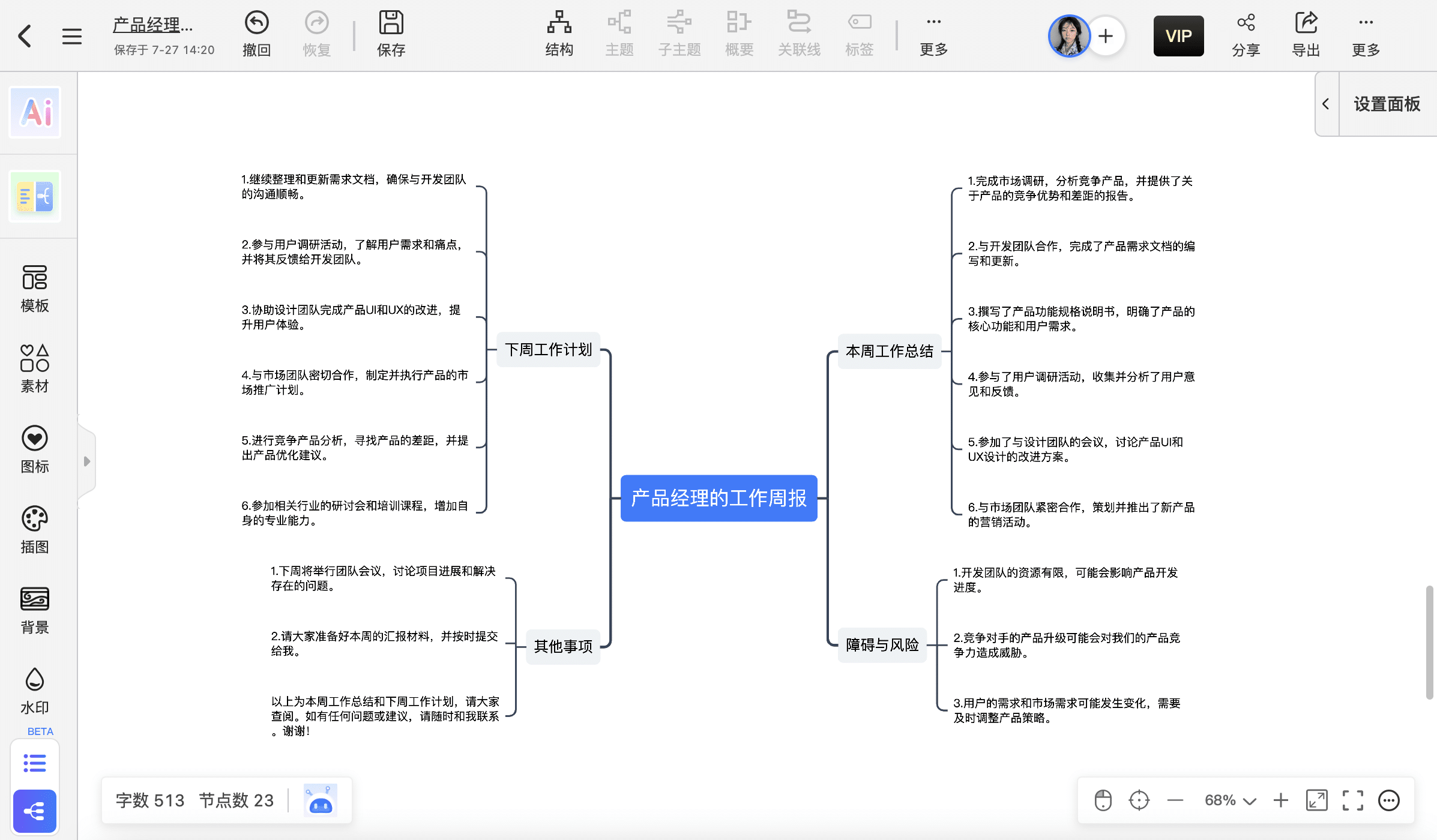
2.AI导图不满意,想要自己新建:
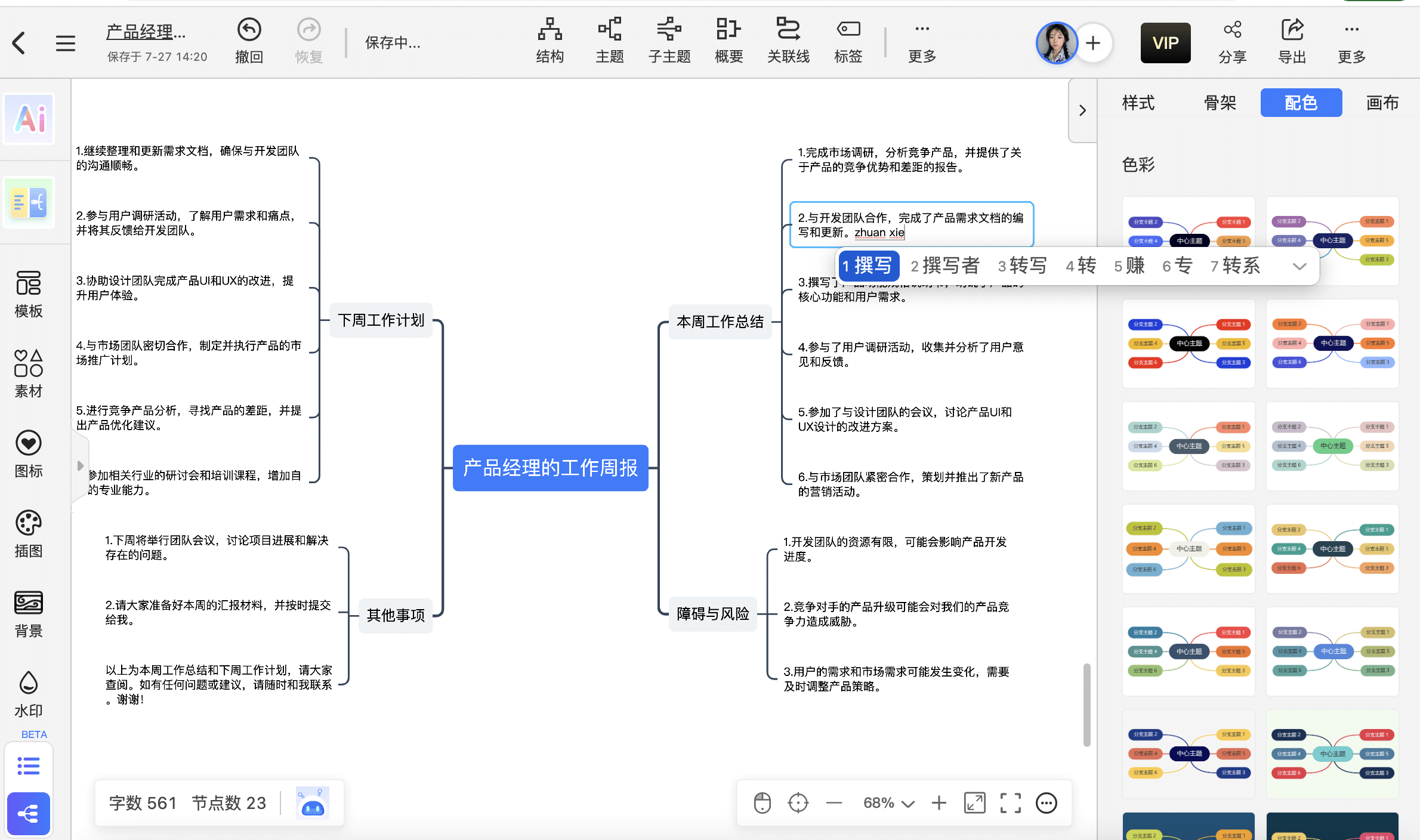
在工作台,选择你要创建的导图类型,就可以新建绘制你自己的导图啦!
比如:你想定制自己的工作周报,只要选择合适的导图框架就可以在节点上自由绘制,还可以在模版库现有的模版上免费修改。结果如下图所示:
五、限时优惠
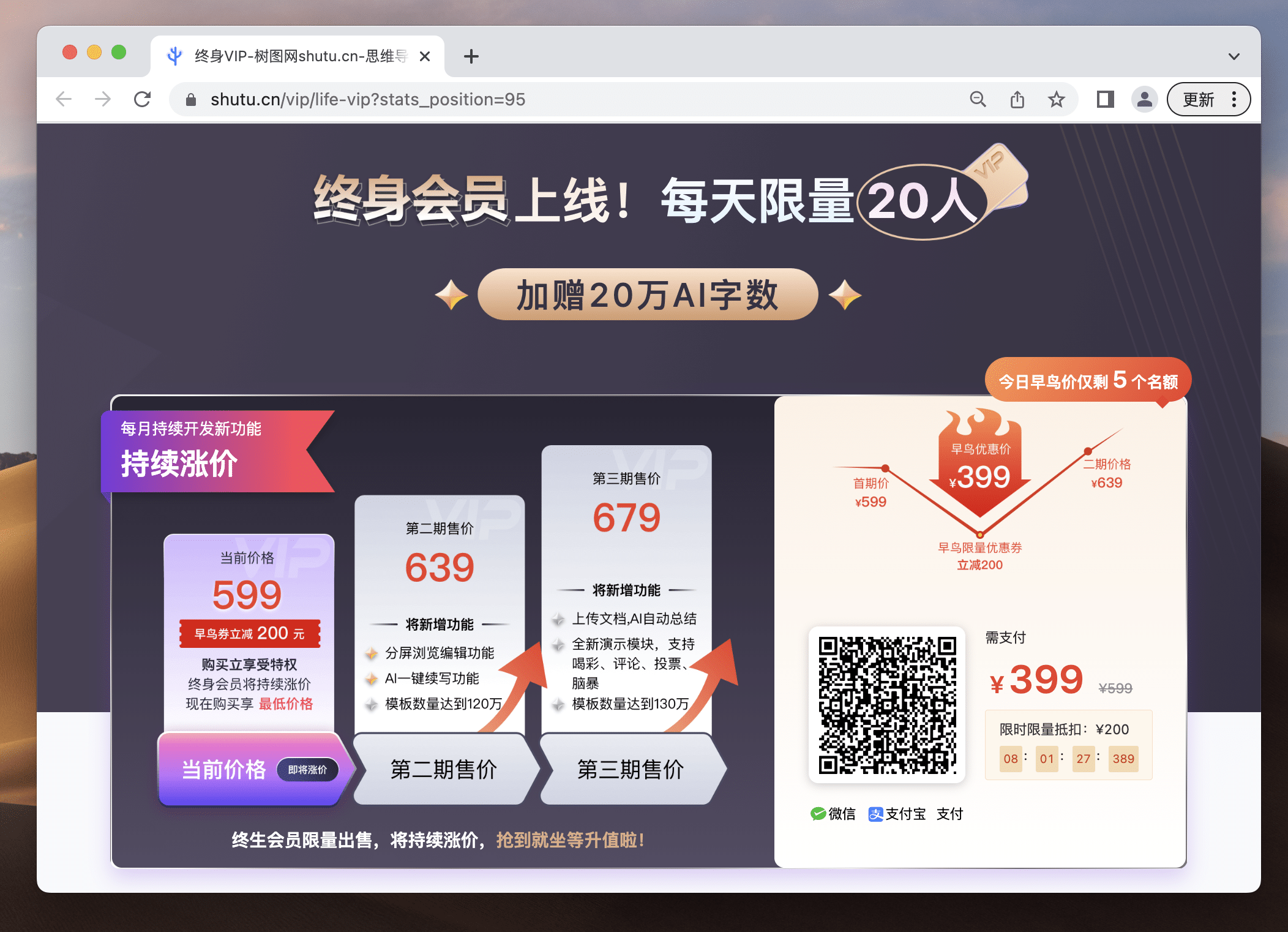
惊天好消息!TreeMind树图目前也上线了终身会员,每天前20名购买的粉丝可以享受立减200元,终身VIP仅需早鸟价399元!倒计时5天!欲购从速!
看完后是不是被TreeMind树图出色的功能和贴心的服务惊艳到了,想要提高工作效率的产品经理们可以去试试,它的会员价格可以说是白菜价了。一个会员可以多个平台通用,非常划算,强烈安利大家入手!
无需下载点击即用:https://shutu.cn/?from=cpjldrgznxxk