
微软研究院版本
目前神经网络在进行训练的时候基本都是基于后向传播(Back Propagation,BP)算法,通过对网络模型参数进行随机初始化,然后利用优化算法优化模型参数。但是在标注数据很少的情况下,通过神经网络训练出的模型往往精度有限,“预训练”则能够很好地解决这个问题,并且对一词多义进行建模。
预训练是通过大量无标注的语言文本进行语言模型的训练,得到一套模型参数,利用这套参数对模型进行初始化,再根据具体任务在现有语言模型的基础上进行精调。预训练的方法在自然语言处理的分类和标记任务中,都被证明拥有更好的效果。目前,热门的预训练方法主要有三个:ELMo,OpenAI GPT和BERT。
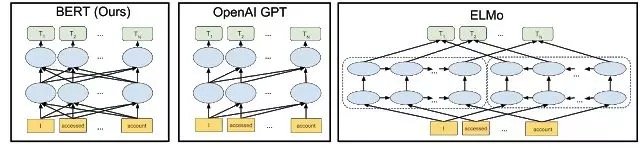
在2018年初,艾伦人工智能研究所和华盛顿大学的研究人员在题为《Deep contextualized word representations》一文中提出了ELMo。相较于传统的使用词嵌入(Word embedding)对词语进行表示,得到每个词唯一固定的词向量,ELMo 利用预训练好的双向语言模型,根据具体输入从该语言模型中可以得到在文本中该词语的表示。在进行有监督的 NLP 任务时,可以将 ELMo 直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。
在ELMo的基础之上,OpenAI的研究人员在《Improving Language Understanding by Generative Pre-Training》提出了OpenAI GPT。与ELMo为每一个词语提供一个显式的词向量不同,OpenAI GPT能够学习一个通用的表示,使其能够在大量任务上进行应用。在处理具体任务时,OpenAI GPT 不需要再重新对任务构建新的模型结构,而是直接在 Transformer 这个语言模型上的最后一层接上 softmax 作为任务输出层,再对这整个模型进行微调。
ELMo和OpenAI GPT这两种预训练语言表示方法都是使用单向的语言模型来学习语言表示,而Google在提出的BERT则实现了双向学习,并得到了更好的训练效果。具体而言,BERT使用Transformer的编码器作为语言模型,并在语言模型训练时提出了两个新的目标:MLM(Masked Language Model)和句子预测。MLM是指在输入的词序列中,随机的挡上 15% 的词,并遮挡部分的词语进行双向预测。为了让模型能够学习到句子间关系,研究人员提出了让模型对即将出现的句子进行预测:对连续句子的正误进行二元分类,再对其取和求似然。
上面内容转载自公众号 微软研究院AI头条,原文地址
百度百科版本
无监督预训练是用来训练的数据不包含输出目标,需要学习算法自动学习到一些有价值的信息。
Comments