

Word2vec 是 Word Embedding 方式之一,属于 NLP 领域。他是将词转化为「可计算」「结构化」的向量的过程。本文将讲解 Word2vec 的原理和优缺点。
这种方式在 2018 年之前比较主流,但是随着 BERT、GPT2.0 的出现,这种方式已经不算效果最好的方法了。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 Word2vec ?
什么是 Word Embedding ?
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
这一步解决的是”将现实问题转化为数学问题“,是人工智能非常关键的一步。
了解更多,可以看这篇文章:《一文看懂词嵌入 word embedding(与其他文本表示比较+2种主流算法)》

将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。因为在后续的任务中会直接用到这个词向量。
什么是 Word2vec ?
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec 在整个 NLP 里的位置可以用下图表示:
在 Word2vec 出现之前,已经有一些 Word Embedding 的方法,但是之前的方法并不成熟,也没有大规模的得到应用。
下面会详细介绍 Word2vec 的训练模型和用法。
Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
- Negative Sample(负采样)
- Hierarchical Softmax
具体加速方法就不详细讲解了,感兴趣的可以自己查找资料。
Word2vec 的优缺点
需要说明的是:Word2vec 是上一代的产物(18 年之前), 18 年之后想要得到最好的效果,已经不使用 Word Embedding 的方法了,所以也不会用到 Word2vec。
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中
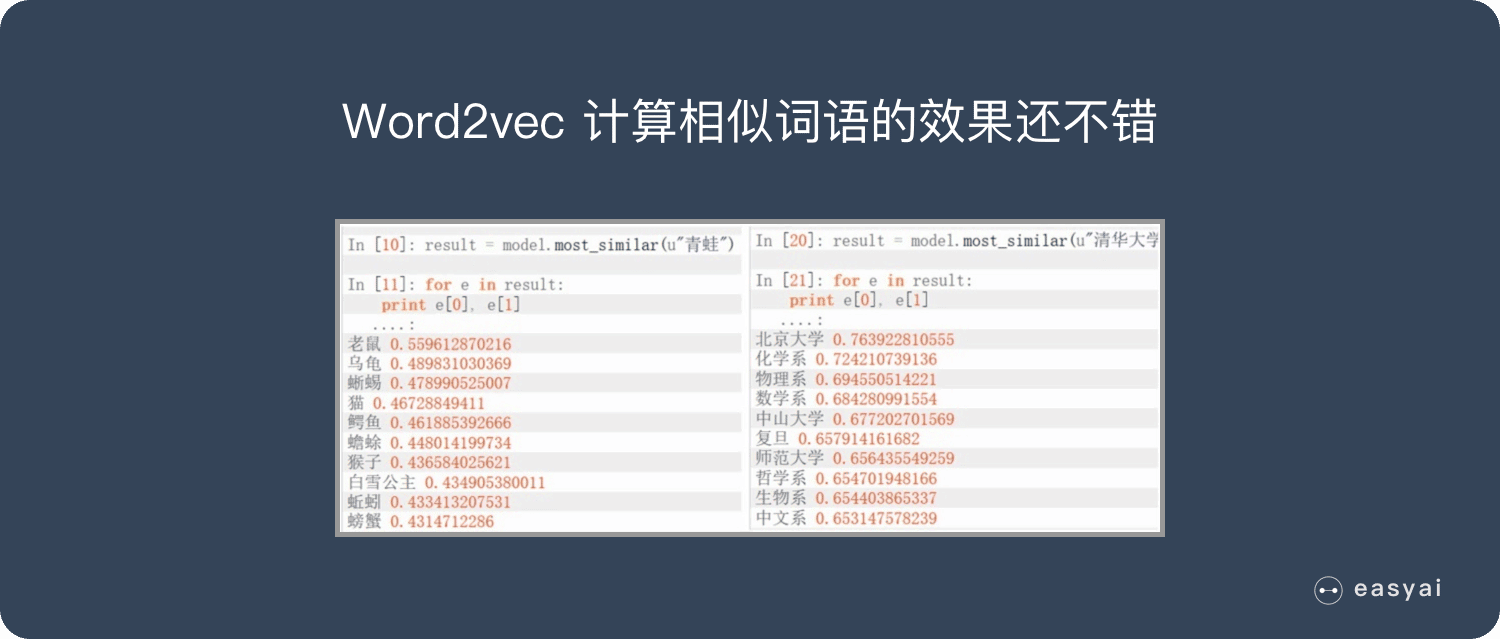
缺点:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化

百度百科
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
4 Comments
您好,请问18年以后用的什么词嵌入方法呢?
深度学习直接端到端,不需要用词嵌入了
19年NAACL Google团队提出的BERT里就摈弃预训练词向量的方法了,而是集成到BERT模型里的字嵌入词嵌入和位置嵌入。
感谢博主,写的太好了!