
Google最近發布了一些有關在深度神經網絡中對注意力機制進行建模的工作
Author Archive
我的業務要不要用人工智能?引入AI前你需要評估的(一)
這是一個系列文章,從各個角度來評估一個問題:“要不要用 AI ?AI 能否解決我的問題?”本期評估角度——特徵。
分類模型評估指標——準確率、精準率、召回率、F1、ROC曲線、AUC曲線

機器學習模型需要有量化的評估指標來評估哪些模型的效果更好。
本文將用通俗易懂的方式講解分類問題的混淆矩陣和各種評估指標的計算公式。將要給大家介紹的評估指標有:準確率、精準率、召回率、F1、ROC曲線、AUC曲線。
機器學習評估指標大全
所有事情都需要評估好壞,尤其是量化的評估指標。
- 高考成績用來評估學生的學習能力
- 杠鈴的重量用來評估肌肉的力量
- 跑分用來評估手機的綜合性能
機器學習有很多評估的指標。有了這些指標我們就橫向的比較哪些模型的表現更好。我們先從整體上來看看主流的評估指標都有哪些:

分類問題評估指標:
- 準確率 – Accuracy
- 精確率(差准率)- Precision
- 召回率(查全率)- Recall
- F1分數
- ROC曲線
- AUC曲線
回歸問題評估指標:
- MAE
- MSE
分類問題圖解
為了方便大家理解各項指標的計算方式,我們用具體的例子將分類問題進行圖解,幫助大家快速理解分類中出現的各種情況。
舉個例子:
我們有10張照片,5張男性、5張女性。如下圖:

有一個判斷性別的機器學習模型,當我們使用它來判斷「是否為男性」時,會出現4種情況。如下圖:

- 實際為男性,且判斷為男性(正確)
- 實際為男性,但判斷為女性(錯誤)
- 實際為女性,且判斷為女性(正確)
- 實際為女性,但判斷為男性(錯誤)
這4種情況構成了經典的混淆矩陣,如下圖:

TP – True Positive:實際為男性,且判斷為男性(正確)
FN – False Negative:實際為男性,但判斷為女性(錯誤)
TN – True Negative:實際為女性,且判斷為女性(正確)
FP – False Positive:實際為女性,但判斷為男性(錯誤)
這4個名詞初看起來比較暈(尤其是縮寫),但是當我們把英文拆分時就很容易理解了,如下圖:

所有的評估指標都是圍繞上面4種情況來計算的,所以理解上面4種情況是基礎!
分類評估指標詳解
下面詳細介紹一下分類分為種的各種評估指標詳情和計算公式:
準確率 – Accuracy
預測正確的結果佔總樣本的百分比,公式如下:
準確率 =(TP+TN)/(TP+TN+FP+FN)

雖然準確率可以判斷總的正確率,但是在樣本不平衡 的情況下,並不能作為很好的指標來衡量結果。舉個簡單的例子,比如在一個總樣本中,正樣本占 90%,負樣本占 10%,樣本是嚴重不平衡的。對於這種情況,我們只需要將全部樣本預測為正樣本即可得到 90% 的高準確率,但實際上我們並沒有很用心的分類,只是隨便無腦一分而已。這就說明了:由於樣本不平衡的問題,導致了得到的高準確率結果含有很大的水分。即如果樣本不平衡,準確率就會失效。
精確率(差准率)- Precision
所有被預測為正的樣本中實際為正的樣本的概率,公式如下:
精準率 =TP/(TP+FP)

精準率和準確率看上去有些類似,但是完全不同的兩個概念。精準率代表對正樣本結果中的預測準確程度,而準確率則代表整體的預測準確程度,既包括正樣本,也包括負樣本。
召回率(查全率)- Recall
實際為正的樣本中被預測為正樣本的概率,其公式如下:
召回率=TP/(TP+FN)

召回率的應用場景: 比如拿網貸違約率為例,相對好用戶,我們更關心壞用戶,不能錯放過任何一個壞用戶。因為如果我們過多的將壞用戶當成好用戶,這樣後續可能發生的違約金額會遠超過好用戶償還的借貸利息金額,造成嚴重償失。召回率越高,代表實際壞用戶被預測出來的概率越高,它的含義類似:寧可錯殺一千,絕不放過一個。
F1分數
如果我們把精確率(Precision)和召回率(Recall)之間的關係用圖來表達,就是下面的PR曲線:

可以發現他們倆的關係是「兩難全」的關係。為了綜合兩者的表現,在兩者之間找一個平衡點,就出現了一個 F1分數。
F1=(2×Precision×Recall)/(Precision+Recall)

ROC曲線、AUC曲線
ROC 和 AUC 是2個更加複雜的評估指標,下面這篇文章已經很詳細的解釋了,這裡直接引用這篇文章的部分內容。
上面的指標說明也是出自這篇文章:《一文讓你徹底理解準確率,精準率,召回率,真正率,假正率,ROC/AUC》
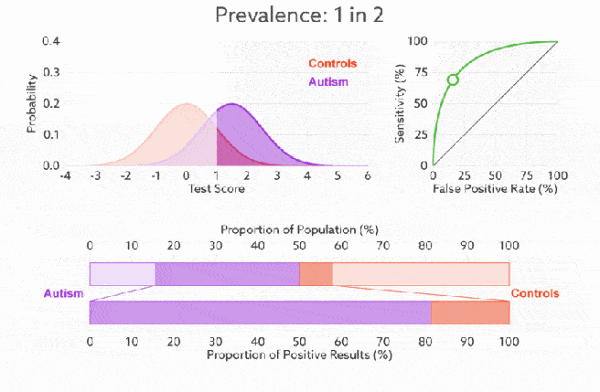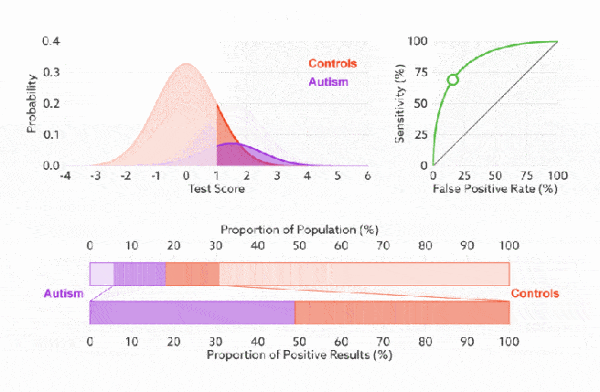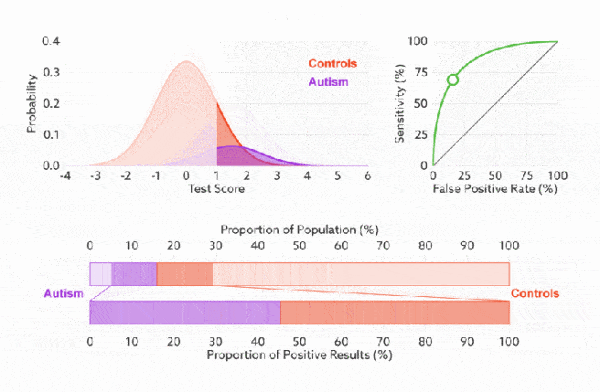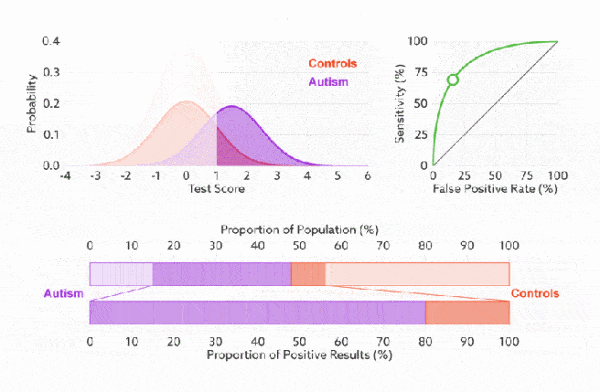
1. 靈敏度,特異度,真正率,假正率
在正式介紹 ROC/AUC 之前,我們還要再介紹兩個指標,這兩個指標的選擇也正是 ROC 和 AUC 可以無視樣本不平衡的原因。 這兩個指標分別是:靈敏度和(1- 特異度),也叫做真正率(TPR)和假正率(FPR)。
靈敏度(Sensitivity) = TP/(TP+FN)
特異度(Specificity) = TN/(FP+TN)
- 其實我們可以發現靈敏度和召回率是一模一樣的,只是名字換了而已。
- 由於我們比較關心正樣本,所以需要查看有多少負樣本被錯誤地預測為正樣本,所以使用(1- 特異度),而不是特異度。
真正率(TPR) = 靈敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特異度 = FP/(FP+TN)
下面是真正率和假正率的示意,我們發現TPR 和 FPR 分別是基於實際表現 1 和 0 出發的,也就是說它們分別在實際的正樣本和負樣本中來觀察相關概率問題。 正因為如此,所以無論樣本是否平衡,都不會被影響。還是拿之前的例子,總樣本中,90% 是正樣本,10% 是負樣本。我們知道用準確率是有水分的,但是用 TPR 和 FPR 不一樣。這裡,TPR 只關注 90% 正樣本中有多少是被真正覆蓋的,而與那 10% 毫無關係,同理,FPR 只關注 10% 負樣本中有多少是被錯誤覆蓋的,也與那 90% 毫無關係,所以可以看出:如果我們從實際表現的各個結果角度出發,就可以避免樣本不平衡的問題了,這也是為什麼選用 TPR 和 FPR 作為 ROC/AUC 的指標的原因。

或者我們也可以從另一個角度考慮:條件概率。 我們假設X為預測值,Y為真實值。那麼就可以將這些指標按條件概率表示:
精準率 = P(Y=1 | X=1)
召回率 = 靈敏度 = P(X=1 | Y=1)
特異度 = P(X=0 | Y=0)
從上面三個公式看到:如果我們先以實際結果為條件(召回率,特異度),那麼就只需考慮一種樣本,而先以預測值為條件(精準率),那麼我們需要同時考慮正樣本和負樣本。所以先以實際結果為條件的指標都不受樣本不平衡的影響,相反以預測結果為條件的就會受到影響。
2. ROC(接受者操作特徵曲線)
ROC(Receiver Operating Characteristic)曲線,又稱接受者操作特徵曲線。該曲線最早應用於雷達信號檢測領域,用於區分信號與噪聲。後來人們將其用於評價模型的預測能力,ROC 曲線是基於混淆矩陣得出的。
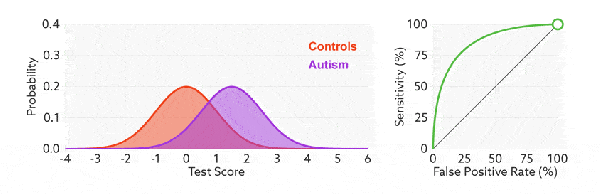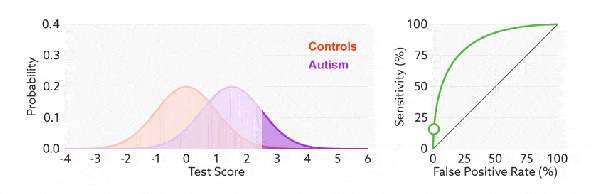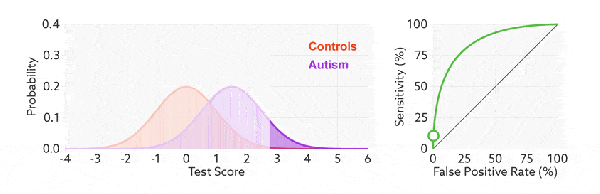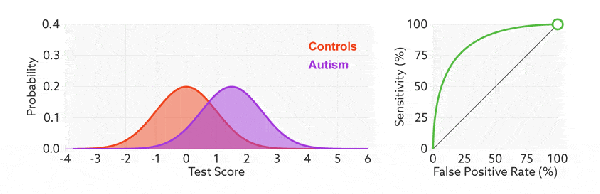
ROC 曲線中的主要兩個指標就是真正率和假正率, 上面也解釋了這麼選擇的好處所在。其中橫坐標為假正率(FPR),縱坐標為真正率(TPR),下面就是一個標準的 ROC 曲線圖。

ROC 曲線的閾值問題
與前面的 P-R 曲線類似,ROC 曲線也是通過遍歷所有閾值 來繪製整條曲線的。如果我們不斷的遍歷所有閾值,預測的正樣本和負樣本是在不斷變化的,相應的在 ROC 曲線圖中也會沿着曲線滑動。
如何判斷 ROC 曲線的好壞?
改變閾值只是不斷地改變預測的正負樣本數,即 TPR 和 FPR,但是曲線本身是不會變的。那麼如何判斷一個模型的 ROC 曲線是好的呢?這個還是要回歸到我們的目的:FPR 表示模型虛報的響應程度,而 TPR 表示模型預測響應的覆蓋程度。我們所希望的當然是:虛報的越少越好,覆蓋的越多越好。所以總結一下就是TPR 越高,同時 FPR 越低(即 ROC 曲線越陡),那麼模型的性能就越好。 參考如下:

ROC 曲線無視樣本不平衡
前面已經對 ROC 曲線為什麼可以無視樣本不平衡做了解釋,下面我們用動態圖的形式再次展示一下它是如何工作的。我們發現:無論紅藍色樣本比例如何改變,ROC 曲線都沒有影響。
3. AUC(曲線下的面積)
為了計算 ROC 曲線上的點,我們可以使用不同的分類閾值多次評估邏輯回歸模型,但這樣做效率非常低。幸運的是,有一種基於排序的高效算法可以為我們提供此類信息,這種算法稱為曲線下面積(Area Under Curve)。
比較有意思的是,如果我們連接對角線,它的面積正好是 0.5。對角線的實際含義是:隨機判斷響應與不響應,正負樣本覆蓋率應該都是 50%,表示隨機效果。 ROC 曲線越陡越好,所以理想值就是 1,一個正方形,而最差的隨機判斷都有 0.5,所以一般 AUC 的值是介於 0.5 到 1 之間的。
AUC 的一般判斷標準
0.5 – 0.7: 效果較低,但用於預測股票已經很不錯了
0.7 – 0.85: 效果一般
0.85 – 0.95: 效果很好
0.95 – 1: 效果非常好,但一般不太可能
AUC 的物理意義
曲線下面積對所有可能的分類閾值的效果進行綜合衡量。曲線下面積的一種解讀方式是看作模型將某個隨機正類別樣本排列在某個隨機負類別樣本之上的概率。以下面的樣本為例,邏輯回歸預測從左到右以升序排列:

通過以下5個簡單步驟將您的機器學習模型投入生產
這篇文章是關於一個成功的ML項目的過程要求的-一個投產的項目。
Attention 機制

Attention 正在被越來越廣泛的得到應用。尤其是 BERT 火爆了之後。
Attention 到底有什麼特別之處?他的原理和本質是什麼?Attention都有哪些類型?本文將詳細講解Attention的方方面面。
想要了解更多 NLP 相關的內容,請訪問 NLP專題 ,免費提供59頁的NLP文檔下載。
訪問 NLP 專題,下載 59 頁免費 PDF
Attention 的本質是什麼
Attention(注意力)機制如果淺層的理解,跟他的名字非常匹配。他的核心邏輯就是「從關注全部到關注重點」。

Attention 機制很像人類看圖片的邏輯,當我們看一張圖片的時候,我們並沒有看清圖片的全部內容,而是將注意力集中在了圖片的焦點上。大家看一下下面這張圖:

我們一定會看清「錦江飯店」4個字,如下圖:

但是我相信沒人會意識到「錦江飯店」上面還有一串「電話號碼」,也不會意識到「喜運來大酒家」,如下圖:

所以,當我們看一張圖片的時候,其實是這樣的:

上面所說的,我們的視覺系統就是一種 Attention機制,將有限的注意力集中在重點信息上,從而節省資源,快速獲得最有效的信息。
AI 領域的 Attention 機制
Attention 機制最早是在計算機視覺里應用的,隨後在 NLP 領域也開始應用了,真正發揚光大是在 NLP 領域,因為 2018 年 BERT 和 GPT 的效果出奇的好,進而走紅。而 Transformer 和 Attention 這些核心開始被大家重點關注。
如果用圖來表達 Attention 的位置大致是下面的樣子:

這裡先讓大家對 Attention 有一個宏觀的概念,下文會對 Attention 機製做更詳細的講解。在這之前,我們先說說為什麼要用 Attention。
Attention 的3大優點
之所以要引入 Attention 機制,主要是3個原因:
- 參數少
- 速度快
- 效果好

參數少
模型複雜度跟 CNN、RNN 相比,複雜度更小,參數也更少。所以對算力的要求也就更小。
速度快
Attention 解決了 RNN 不能並行計算的問題。Attention機制每一步計算不依賴於上一步的計算結果,因此可以和CNN一樣並行處理。
效果好
在 Attention 機制引入之前,有一個問題大家一直很苦惱:長距離的信息會被弱化,就好像記憶能力弱的人,記不住過去的事情是一樣的。
Attention 是挑重點,就算文本比較長,也能從中間抓住重點,不丟失重要的信息。下圖紅色的預期就是被挑出來的重點。

Attention 的原理
Attention 經常會和 Encoder–Decoder 一起說,之前的文章《一文看懂 NLP 里的模型框架 Encoder-Decoder 和 Seq2Seq》 也提到了 Attention。
下面的動圖演示了attention 引入 Encoder-Decoder 框架下,完成機器翻譯任務的大致流程。
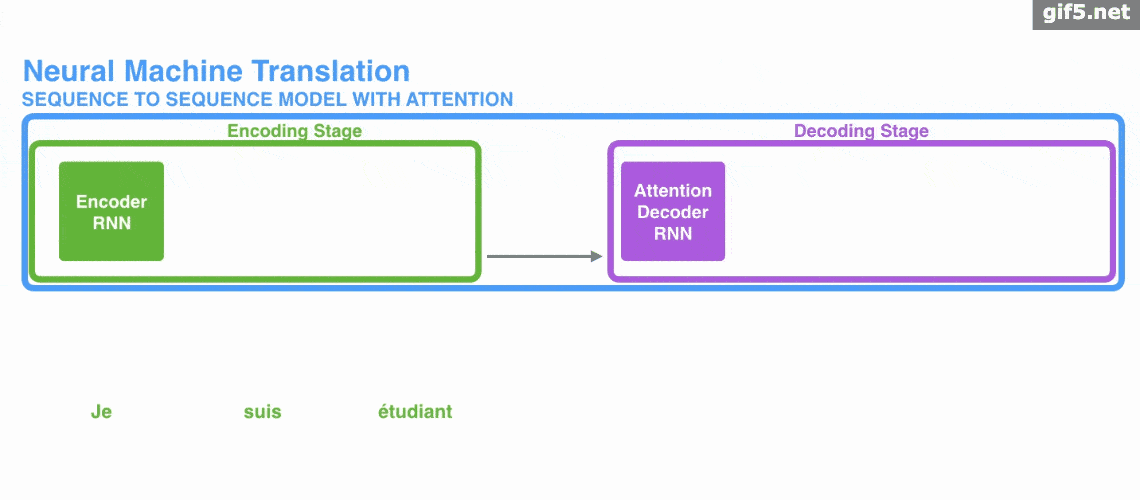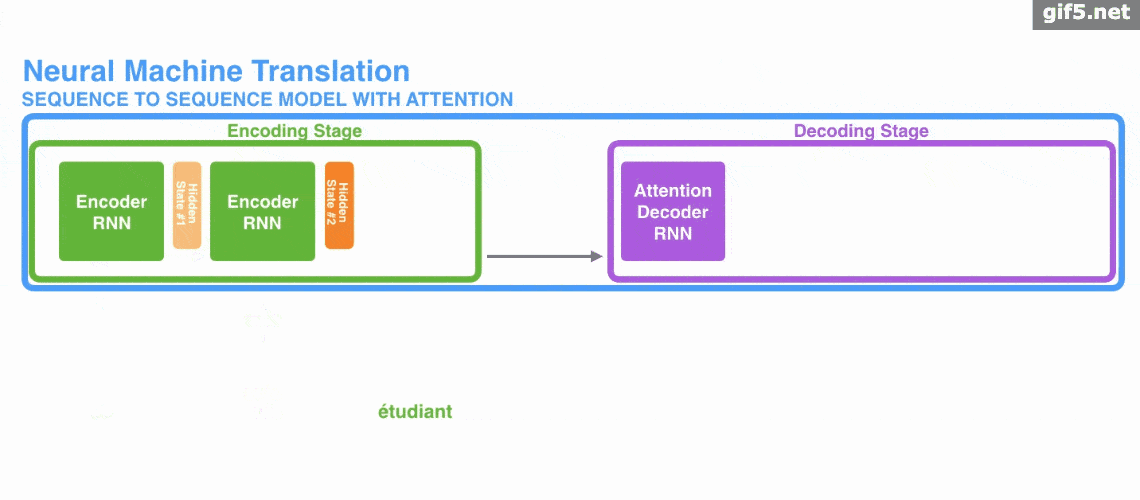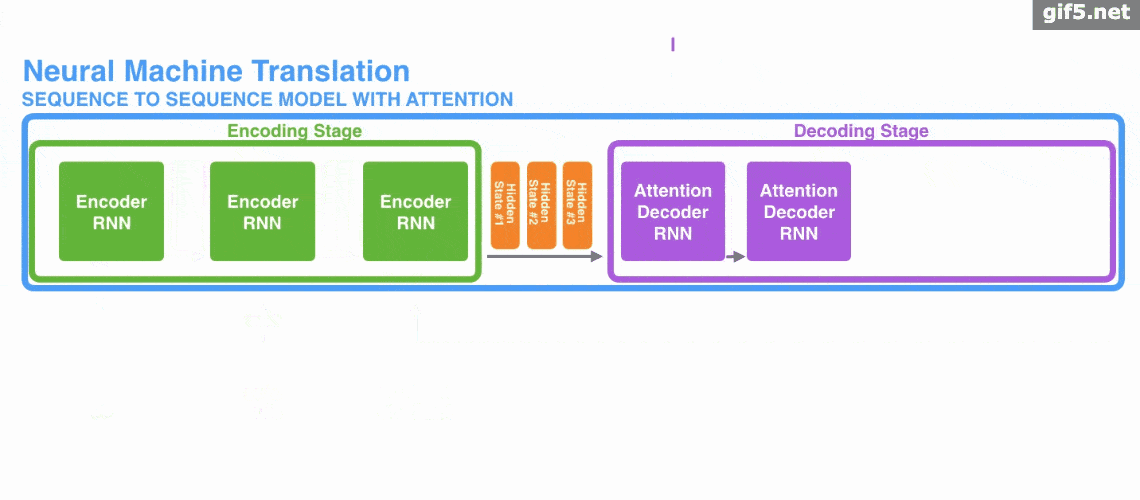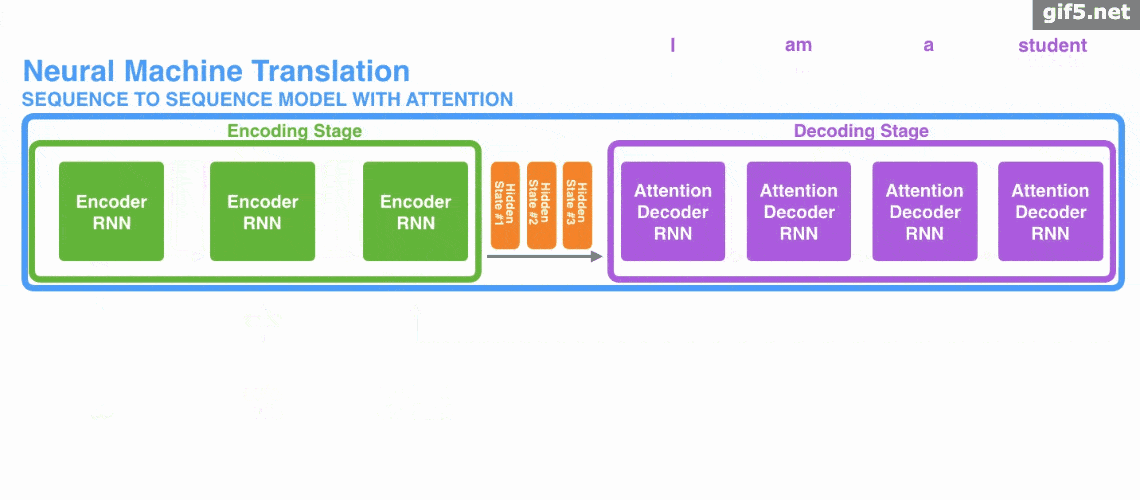
但是,Attention 並不一定要在 Encoder-Decoder 框架下使用的,他是可以脫離 Encoder-Decoder 框架的。
下面的圖片則是脫離 Encoder-Decoder 框架後的原理圖解。

小故事講解
上面的圖看起來比較抽象,下面用一個例子來解釋 attention 的原理:

圖書管(source)里有很多書(value),為了方便查找,我們給書做了編號(key)。當我們想要了解漫威(query)的時候,我們就可以看看那些動漫、電影、甚至二戰(美國隊長)相關的書籍。
為了提高效率,並不是所有的書都會仔細看,針對漫威來說,動漫,電影相關的會看的仔細一些(權重高),但是二戰的就只需要簡單掃一下即可(權重低)。
當我們全部看完後就對漫威有一個全面的了解了。
Attention 原理的3步分解:

第一步: query 和 key 進行相似度計算,得到權值
第二步:將權值進行歸一化,得到直接可用的權重
第三步:將權重和 value 進行加權求和
從上面的建模,我們可以大致感受到 Attention 的思路簡單,四個字“帶權求和”就可以高度概括,大道至簡。做個不太恰當的類比,人類學習一門新語言基本經歷四個階段:死記硬背(通過閱讀背誦學習語法練習語感)->提綱挈領(簡單對話靠聽懂句子中的關鍵詞彙準確理解核心意思)->融會貫通(複雜對話懂得上下文指代、語言背後的聯繫,具備了舉一反三的學習能力)->登峰造極(沉浸地大量練習)。
這也如同attention的發展脈絡,RNN 時代是死記硬背的時期,attention 的模型學會了提綱挈領,進化到 transformer,融匯貫通,具備優秀的表達學習能力,再到 GPT、BERT,通過多任務大規模學習積累實戰經驗,戰鬥力爆棚。
要回答為什麼 attention 這麼優秀?是因為它讓模型開竅了,懂得了提綱挈領,學會了融會貫通。
——阿里技術
想要了解更多技術細節,可以看看下面的文章或者視頻:
「文章」深度學習中的注意力機制
「文章」探索 NLP 中的 Attention 注意力機制及 Transformer 詳解
Attention 的 N 種類型
Attention 有很多種不同的類型:Soft Attention、Hard Attention、靜態Attention、動態Attention、Self Attention 等等。下面就跟大家解釋一下這些不同的 Attention 都有哪些差別。

由於這篇文章《Attention用於NLP的一些小結》已經總結的很好的,下面就直接引用了:
本節從計算區域、所用信息、結構層次和模型等方面對Attention的形式進行歸類。
1. 計算區域
根據Attention的計算區域,可以分成以下幾種:
1)Soft Attention,這是比較常見的Attention方式,對所有key求權重概率,每個key都有一個對應的權重,是一種全局的計算方式(也可以叫Global Attention)。這種方式比較理性,參考了所有key的內容,再進行加權。但是計算量可能會比較大一些。
2)Hard Attention,這種方式是直接精準定位到某個key,其餘key就都不管了,相當於這個key的概率是1,其餘key的概率全部是0。因此這種對齊方式要求很高,要求一步到位,如果沒有正確對齊,會帶來很大的影響。另一方面,因為不可導,一般需要用強化學習的方法進行訓練。(或者使用gumbel softmax之類的)
3)Local Attention,這種方式其實是以上兩種方式的一個折中,對一個窗口區域進行計算。先用Hard方式定位到某個地方,以這個點為中心可以得到一個窗口區域,在這個小區域內用Soft方式來算Attention。
2. 所用信息
假設我們要對一段原文計算Attention,這裡原文指的是我們要做attention的文本,那麼所用信息包括內部信息和外部信息,內部信息指的是原文本身的信息,而外部信息指的是除原文以外的額外信息。
1)General Attention,這種方式利用到了外部信息,常用於需要構建兩段文本關係的任務,query一般包含了額外信息,根據外部query對原文進行對齊。
比如在閱讀理解任務中,需要構建問題和文章的關聯,假設現在baseline是,對問題計算出一個問題向量q,把這個q和所有的文章詞向量拼接起來,輸入到LSTM中進行建模。那麼在這個模型中,文章所有詞向量共享同一個問題向量,現在我們想讓文章每一步的詞向量都有一個不同的問題向量,也就是,在每一步使用文章在該步下的詞向量對問題來算attention,這裡問題屬於原文,文章詞向量就屬於外部信息。
2)Local Attention,這種方式只使用內部信息,key和value以及query只和輸入原文有關,在self attention中,key=value=query。既然沒有外部信息,那麼在原文中的每個詞可以跟該句子中的所有詞進行Attention計算,相當於尋找原文內部的關係。
還是舉閱讀理解任務的例子,上面的baseline中提到,對問題計算出一個向量q,那麼這裡也可以用上attention,只用問題自身的信息去做attention,而不引入文章信息。
3. 結構層次
結構方面根據是否劃分層次關係,分為單層attention,多層attention和多頭attention:
1)單層Attention,這是比較普遍的做法,用一個query對一段原文進行一次attention。
2)多層Attention,一般用於文本具有層次關係的模型,假設我們把一個document劃分成多個句子,在第一層,我們分別對每個句子使用attention計算出一個句向量(也就是單層attention);在第二層,我們對所有句向量再做attention計算出一個文檔向量(也是一個單層attention),最後再用這個文檔向量去做任務。
3)多頭Attention,這是Attention is All You Need中提到的multi-head attention,用到了多個query對一段原文進行了多次attention,每個query都關注到原文的不同部分,相當於重複做多次單層attention:

最後再把這些結果拼接起來:

4. 模型方面
從模型上看,Attention一般用在CNN和LSTM上,也可以直接進行純Attention計算。
1)CNN+Attention
CNN的卷積操作可以提取重要特徵,我覺得這也算是Attention的思想,但是CNN的卷積感受視野是局部的,需要通過疊加多層卷積區去擴大視野。另外,Max Pooling直接提取數值最大的特徵,也像是hard attention的思想,直接選中某個特徵。
CNN上加Attention可以加在這幾方面:
a. 在卷積操作前做attention,比如Attention-Based BCNN-1,這個任務是文本蘊含任務需要處理兩段文本,同時對兩段輸入的序列向量進行attention,計算出特徵向量,再拼接到原始向量中,作為卷積層的輸入。
b. 在卷積操作後做attention,比如Attention-Based BCNN-2,對兩段文本的卷積層的輸出做attention,作為pooling層的輸入。
c. 在pooling層做attention,代替max pooling。比如Attention pooling,首先我們用LSTM學到一個比較好的句向量,作為query,然後用CNN先學習到一個特徵矩陣作為key,再用query對key產生權重,進行attention,得到最後的句向量。
2)LSTM+Attention
LSTM內部有Gate機制,其中input gate選擇哪些當前信息進行輸入,forget gate選擇遺忘哪些過去信息,我覺得這算是一定程度的Attention了,而且號稱可以解決長期依賴問題,實際上LSTM需要一步一步去捕捉序列信息,在長文本上的表現是會隨着step增加而慢慢衰減,難以保留全部的有用信息。
LSTM通常需要得到一個向量,再去做任務,常用方式有:
a. 直接使用最後的hidden state(可能會損失一定的前文信息,難以表達全文)
b. 對所有step下的hidden state進行等權平均(對所有step一視同仁)。
c. Attention機制,對所有step的hidden state進行加權,把注意力集中到整段文本中比較重要的hidden state信息。性能比前面兩種要好一點,而方便可視化觀察哪些step是重要的,但是要小心過擬合,而且也增加了計算量。
3)純Attention
Attention is all you need,沒有用到CNN/RNN,乍一聽也是一股清流了,但是仔細一看,本質上還是一堆向量去計算attention。
5. 相似度計算方式
在做attention的時候,我們需要計算query和某個key的分數(相似度),常用方法有:
1)點乘:最簡單的方法, 
2)矩陣相乘:
3)cos相似度: 
4)串聯方式:把q和k拼接起來, 
5)用多層感知機也可以: 
如何選擇機器學習模型
有沒有想過我們如何將機器學習算法應用於問題,以便分析,可視化,發現趨勢並找到數據中的相關性?在本文中,我將討論建立機器學習模型的常見步驟以及為數據選擇正確模型的方法。本文的靈感來自於常見的訪談問題,這些問題被問及如何處理數據科學問題以及為什麼選擇上述模型。
拆解 YouTube 下一個視頻的推薦機制
本文詳解 YouTube 的推薦機制,他們是如何給用戶推薦下一個視頻的。
特徵選擇:重要性及方法詳解
在本文中,我將與您分享我在Fiverr領導的上一個項目期間研究的一些方法。
您將獲得有關我嘗試的基本方法以及更複雜的方法的一些想法,該方法獲得了最佳效果-刪除了60%以上的功能,同時保持了準確性並為我們的模型實現了更高的穩定性。我還將分享我們對該算法的改進。
Encoder-Decoder 和 Seq2Seq

Encoder-Decoder 是 NLP 領域裡的一種模型框架。它被廣泛用於機器翻譯、語音識別等任務。
本文將詳細介紹 Encoder-Decoder、Seq2Seq 以及他們的升級方案Attention。
想要了解更多 NLP 相關的內容,請訪問 NLP專題 ,免費提供59頁的NLP文檔下載。
訪問 NLP 專題,下載 59 頁免費 PDF
什麼是 Encoder-Decoder ?
Encoder-Decoder 模型主要是 NLP 領域裡的概念。它並不特值某種具體的算法,而是一類算法的統稱。Encoder-Decoder 算是一個通用的框架,在這個框架下可以使用不同的算法來解決不同的任務。
Encoder-Decoder 這個框架很好的詮釋了機器學習的核心思路:
將現實問題轉化為數學問題,通過求解數學問題,從而解決現實問題。
Encoder 又稱作編碼器。它的作用就是「將現實問題轉化為數學問題」

Decoder 又稱作解碼器,他的作用是「求解數學問題,並轉化為現實世界的解決方案」

把 2 個環節連接起來,用通用的圖來表達則是下面的樣子:

關於 Encoder-Decoder,有2 點需要說明:
- 不論輸入和輸出的長度是什麼,中間的「向量 c」 長度都是固定的(這也是它的缺陷,下文會詳細說明)
- 根據不同的任務可以選擇不同的編碼器和解碼器(可以是一個 RNN ,但通常是其變種 LSTM 或者 GRU )
只要是符合上面的框架,都可以統稱為 Encoder-Decoder 模型。說到 Encoder-Decoder 模型就經常提到一個名詞—— Seq2Seq。
什麼是 Seq2Seq?
Seq2Seq(是 Sequence-to-sequence 的縮寫),就如字面意思,輸入一個序列,輸出另一個序列。這種結構最重要的地方在於輸入序列和輸出序列的長度是可變的。例如下圖:
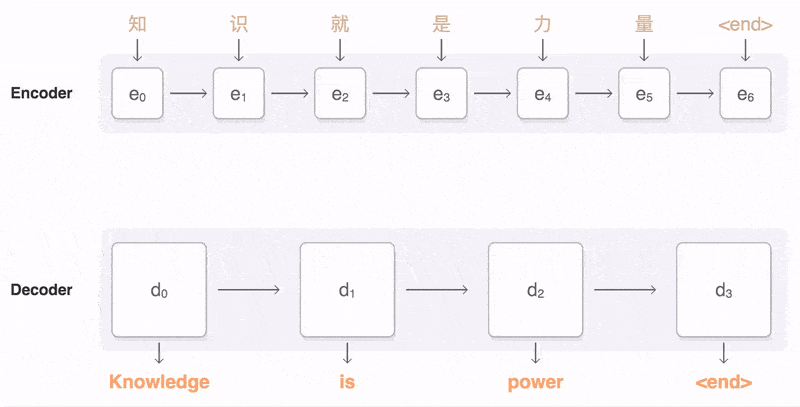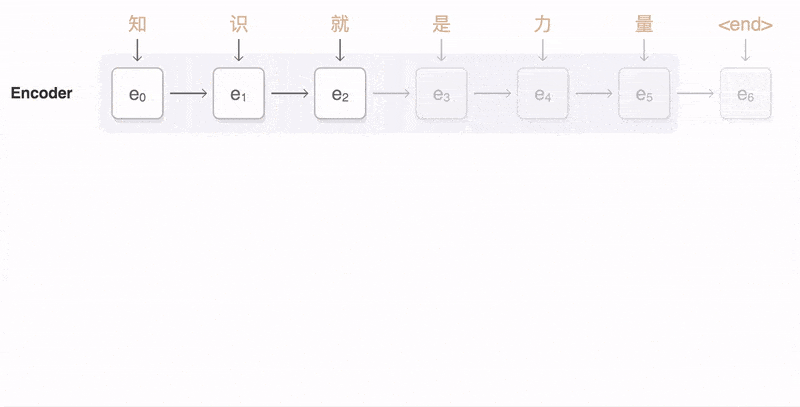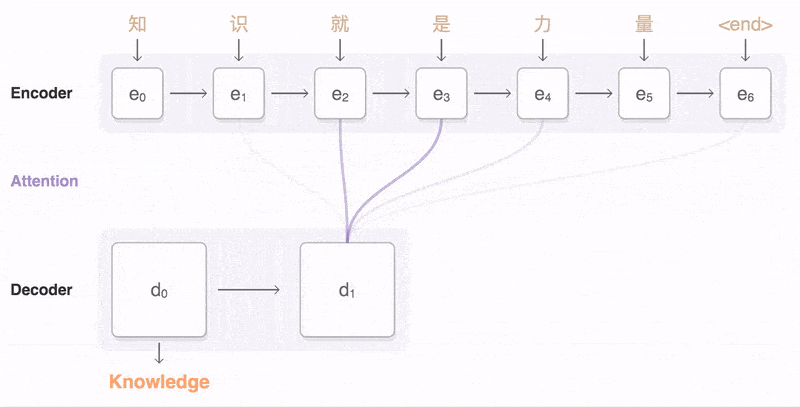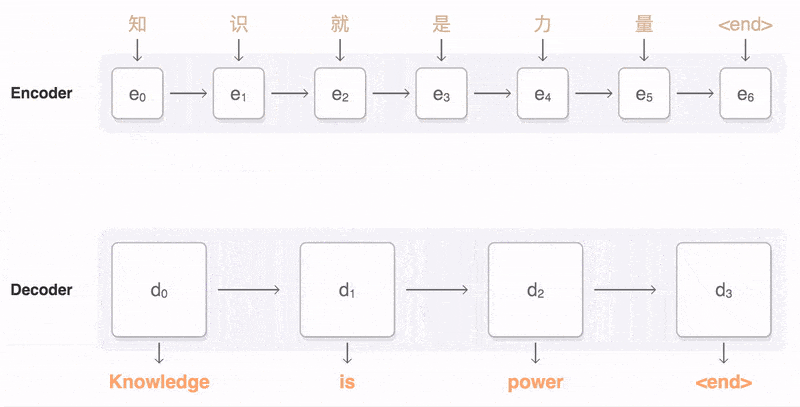
如上圖:輸入了 6 個漢字,輸出了 3 個英文單詞。輸入和輸出的長度不同。
Seq2Seq 的由來
在 Seq2Seq 框架提出之前,深度神經網絡在圖像分類等問題上取得了非常好的效果。在其擅長解決的問題中,輸入和輸出通常都可以表示為固定長度的向量,如果長度稍有變化,會使用補零等操作。
然而許多重要的問題,例如機器翻譯、語音識別、自動對話等,表示成序列後,其長度事先並不知道。因此如何突破先前深度神經網絡的局限,使其可以適應這些場景,成為了13年以來的研究熱點,Seq2Seq框架應運而生。
「Seq2Seq」和「Encoder-Decoder」的關係
Seq2Seq(強調目的)不特指具體方法,滿足「輸入序列、輸出序列」的目的,都可以統稱為 Seq2Seq 模型。
而 Seq2Seq 使用的具體方法基本都屬於Encoder-Decoder 模型(強調方法)的範疇。
總結一下的話:
- Seq2Seq 屬於 Encoder-Decoder 的大範疇
- Seq2Seq 更強調目的,Encoder-Decoder 更強調方法
Encoder-Decoder 有哪些應用?

機器翻譯、對話機器人、詩詞生成、代碼補全、文章摘要(文本 – 文本)
「文本 – 文本」 是最典型的應用,其輸入序列和輸出序列的長度可能會有較大的差異。
Google 發表的用Seq2Seq做機器翻譯的論文《Sequence to Sequence Learning with Neural Networks》
語音識別(音頻 – 文本)
語音識別也有很強的序列特徵,比較適合 Encoder-Decoder 模型。
Google 發表的使用Seq2Seq做語音識別的論文《A Comparison of Sequence-to-Sequence Models for Speech Recognition》

圖像描述生成(圖片 – 文本)
通俗的講就是「看圖說話」,機器提取圖片特徵,然後用文字表達出來。這個應用是計算機視覺和 NLP 的結合。
圖像描述生成的論文《Sequence to Sequence – Video to Text》
Encoder-Decoder 的缺陷
上文提到:Encoder(編碼器)和 Decoder(解碼器)之間只有一個「向量 c」來傳遞信息,且 c 的長度固定。
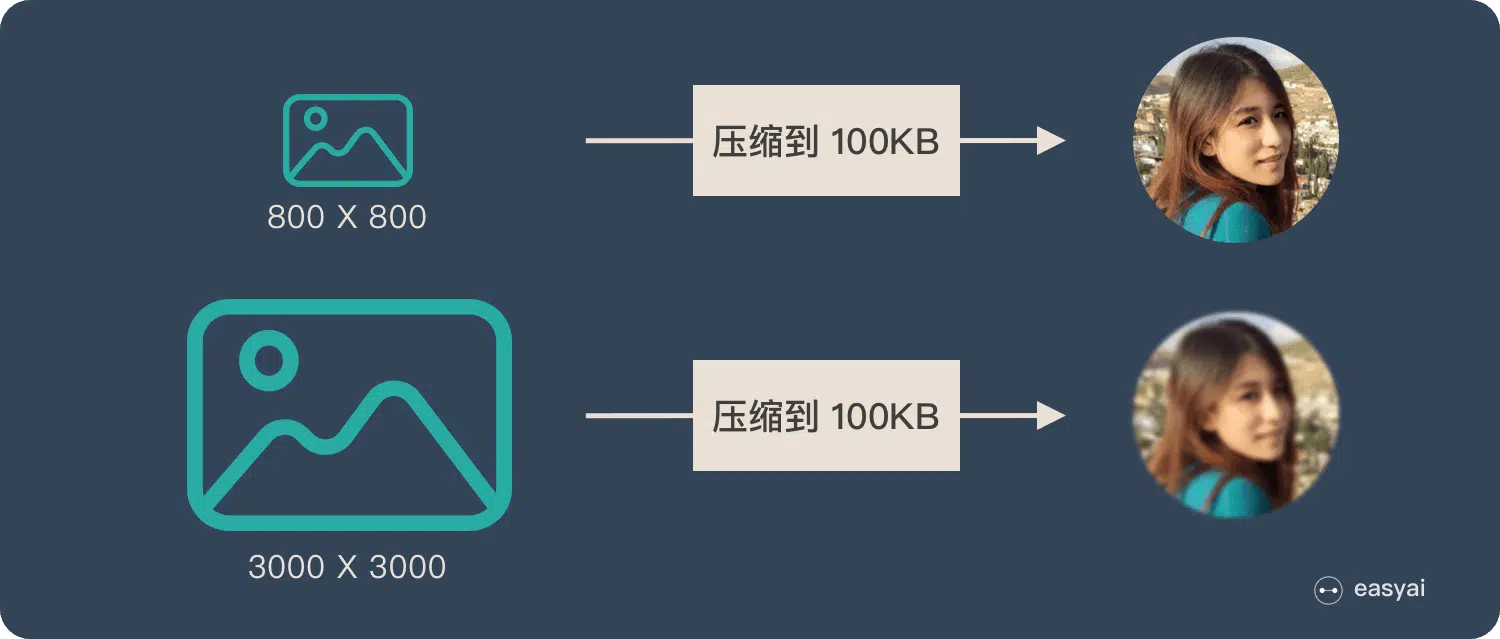
為了便於理解,我們類比為「壓縮-解壓」的過程:
將一張 800X800 像素的圖片壓縮成 100KB,看上去還比較清晰。再將一張 3000X3000 像素的圖片也壓縮到 100KB,看上去就模糊了。
Encoder-Decoder 就是類似的問題:當輸入信息太長時,會丟失掉一些信息。
Attention 解決信息丟失問題
Attention 機制就是為了解決「信息過長,信息丟失」的問題。
Attention 模型的特點是 Eecoder 不再將整個輸入序列編碼為固定長度的「中間向量 C」 ,而是編碼成一個向量的序列。引入了 Attention 的 Encoder-Decoder 模型如下圖:
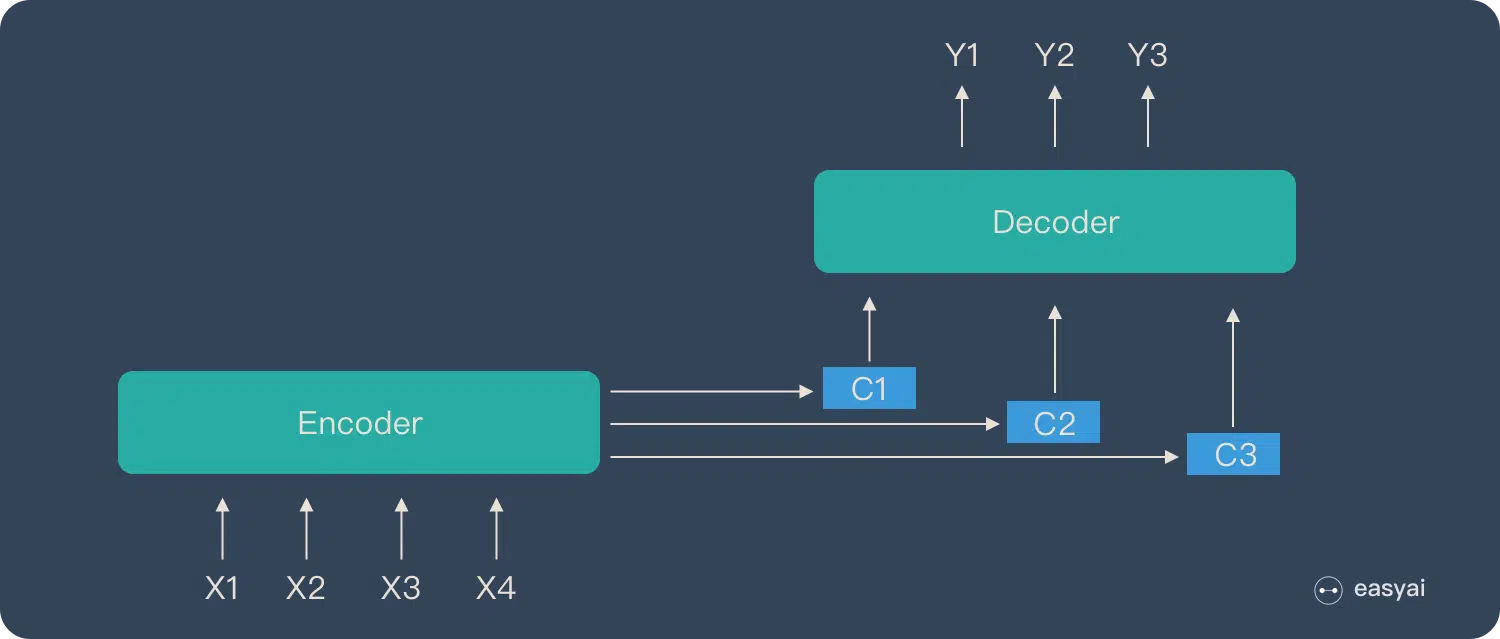
這樣,在產生每一個輸出的時候,都能夠做到充分利用輸入序列攜帶的信息。而且這種方法在翻譯任務中取得了非常不錯的成果。
Attention 是一個很重要的知識點,想要詳細了解 Attention,請查看《一文看懂 Attention(本質原理+3大優點+5大類型)》
NLP 領域裡的8 種文本表示方式及優缺點
文本表示( text representation)是NLP任務中非常基礎,同時也非常重要的一部分。本文將介紹文本表示的發展歷史及各方法的優缺點