

本文轉載自公眾號 讀芯術,原文地址
你聽說過「群策群力」嗎?不是電視劇,而是一個真實的術語。沒有?好吧,想像一下你在茫茫人海中問了一個複雜的問題。現在,來匯總下人們的答案。
你可能會發現,大多數人給出的答案比專家的回答要好。
「群策群力」是指一群人的集體意見,而非某個專家的意見。
——維基百科
回到機器學習領域,我們可以運用同樣的思路。例如,如果我們將一組預測器(如分類器和回歸器)的預測聚合在一起,所得結果可能會比使用單個最佳預測器更為準確。
一組預測器稱為一個集合。因此,這種機器學習技術被稱為集成學習。
在自然界中,一群樹組成一片森林。假設訓練一組樹形判定分類器,根據訓練數據集的不同子集進行個體預測。後來考慮到大多數人對相同情況的預測,你預測到了預期的觀察類。這意味著,你基本上是在使用樹形判定分類法的知識集合,它通常被稱為隨機森林。
本文將介紹最流行的集成方法,包括bagging、boosting、stacking等。在深入討論之前,請謹記:
當預測器儘可能相互獨立時,集成方法的效果最好。獲得不同分類器的方法之一是使用完全不同的演算法來訓練他們。這增加了其產生不同類型誤差的機會,從而提高了集成的準確性。
——摘自《使用Scikit-Learn&TensorFlow進行機器學習》第7章
簡單集成技術
Hard Voting 分類器
這是該技術最簡單的例子,你可能已經熟練掌握。投票分類器通常用於分類問題。假設你已訓練並將一些分類器(邏輯回歸分類器,SVM分類器,隨機森林分類器等)與訓練數據集進行了匹配。
創建一個更好的分類器的簡單方法是將每個分類器所做的預測集合起來,將選擇的多數作為最終預測。基本上,我們可以將其視為檢索所有預測器的模式。

平均
上述第一個例子主要用於分類問題。現在,我們來看一種用於回歸問題的技術——平均。與Hard Voting類似,我們採用不同的演算法進行多次預測,取其平均值進行最終預測。
加權平均
這種方法是指在求平均數時,根據模型對最終預測的重要性,給模型分配不同的權重。
高級集成技術
Stacking
這種技術也被稱為堆棧泛化,它基於訓練模型的思想,將執行我們之前看到的常規集合。

我們有N個預測器,每個都進行預測並返回一個最終值。之後,元學習者或 Blender 將這些預測作為輸入並做出最終預測。
讓我們看看它是如何工作的。

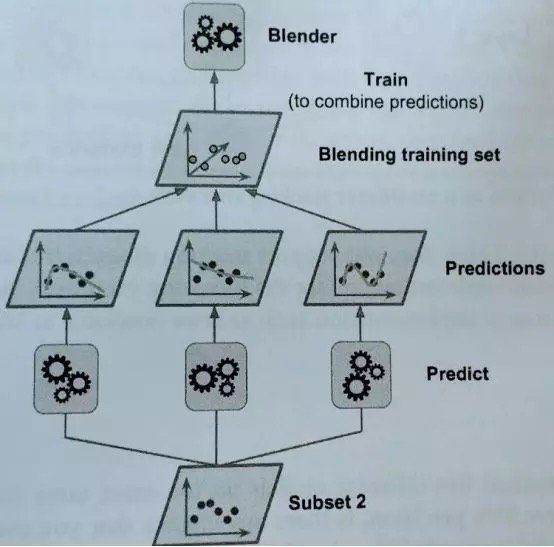
訓練元學習者的常用方法是留出集。首先,將訓練集分成兩個子集。第一個數據子集用來訓練預測器。
之後,用訓練第一個子集的預測器來對第二個子集(即留出集)進行預測。這樣可以確保預測的潔凈度,因為這些演算法從未進行過數據處理。
通過這些新的預測,我們可以生成一個新的訓練集,將其作為輸入特徵(使新的訓練集三維化)並保持目標值。
因此,最後在這個新的數據集上訓練元學習者,並在考慮到第一次預測給出的值的情況下預測目標值。
此外,你可以用這種方法訓練好幾個元學習者(例如,一個使用線性回歸,另一個使用隨機森林回歸,等等)。要使用多個元學習者,必須將訓練集分為三個或以上的子集:第一個子集用於訓練第一層預測器,第二個用於對未知數據進行預測並創建新的數據集,第三個用於訓練元學習者並對目標值進行預測。
Bagging 與 Pasting
另一種方法是對每個預測器(如樹形判定分類法)採用相同的演算法,然而,訓練集的不同隨機子集可以得到更全面的結果。
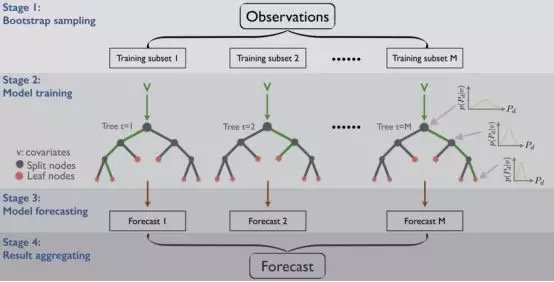
至於子集的創建,可以進行替換 ,也可以不替換。如果假設存在替換,那麼有些觀測結果可能出現在多個子集中,這就是我們為什麼將這個方法稱為bagging( bootstrap aggregating的縮寫)的原因。而在不進行替換的情況下進行抽樣時,我們確保每個子集中的所有觀察值都是唯一的,從而保證每個子集中不會出現重複的觀察值。
一旦所有的預測器訓練完畢,集合就可以通過聚合所有訓練過的預測器的預測值來對一個新實例進行預測,就像我們在hard voting分類器中看到的那樣。雖然每個個體預測器的偏差都高於在原始數據集上訓練的預測器,但是聚合可以減少偏差和方差。
使用pasting則可能使這些模型得到相同的結果,因為它們的輸入相同。與pasting相比,bootstraping的每個子集更具多樣性,因此用bagging所得到的偏差更大,這意味著預測器之間的相關性更小,從而降低了集成的方差。總之, bagging 模型通常能提供更好的結果,這就解釋了為什麼一般而言bagging比pasting更常見。
Boosting
如果第一個模型和下一個模型(可能是所有模型)對一個數據點的預測都不正確,那麼其結果的組合會提供更好的預測嗎?這就是Boosting的作用所在。
Boosting也被稱為Hypothesis Boosting,是指任何可以將學習能力弱者組合成學習能力強者的集成方法。這是一個連續的過程,每個模型都試圖修正上一個模型的錯誤。

每個模型不會在整個數據集上都表現良好。然而,在數據集的某些部分它們確實表現得很好。因此,通過Boosting,我們可以期待每個模型都能有助於實際提高整個集成的性能。
基於Bagging和Boosting的演算法
最常用的集成學習技術是Bagging和Boosting。下面是這些技術中一些最常見的演算法。
Bagging 演算法:
· 隨機森林(https://medium.com/diogo-menezes-borges/random-forests-8ae226855565)
Boosting 演算法:
· AdaBoost(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)
· Gradient Boosting Machine (GBM)(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)
· XGBoost(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)
· Light GBM(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)

Comments