

簡介
如果您還沒有聽過,請告訴您一個事實,作為一名數據科學家,您應該始終站在一個角落跟你說:“你的結果與你的數據一樣好。”
嘗試通過提高模型能力來彌補糟糕的數據是許多人會犯的錯誤。這相當於你因為原來的汽車使用了劣質汽油導致汽車表現不佳,而更換了一輛超級跑車。這種情況下應該做的是提煉汽油,而不是升級的車。在這篇文章中。我將向您解釋如何通過提高數據集質量的方法來輕鬆獲取更好的結果。
注意:我將以圖像分類的任務為例,但這些技巧可以應用於各種數據集。
問題1:數據量不夠。
如果你的數據集過小,你的模型將沒有足夠多的樣本,概括找到其中的特徵,在此基礎上擬合的數據,會導致雖然訓練結果沒太出錯但是測試錯誤會很高。
解決方案1:收集更多數據。
您可以嘗試找到更多的相同源做為您的原始數據集,或者從另一個相似度很高的源,再或者如果你絕對要來概括。
注意事項:這通常不是一件容易的事,需要投入時間和金錢。此外,你可能想要做一個分析,以確定你需要有多少額外的數據。將結果與不同的數據集大小進行比較,並嘗試進行推斷。
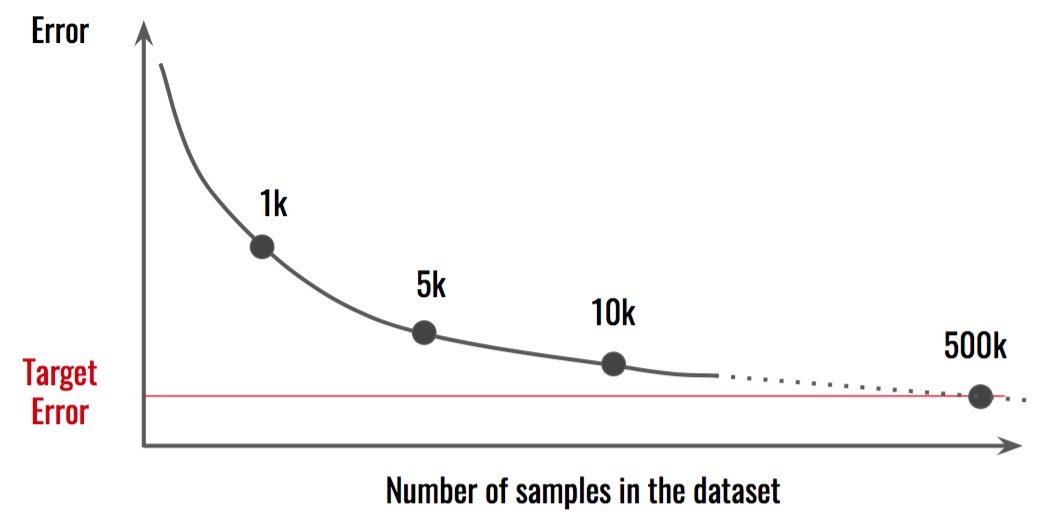
在這種情況下,似乎我們需要500k樣本才能達到目標 誤差。這意味着我們現在收集的數據量是目前的50倍。處理數據的其他方面或 模型可能更有效。
解決方案2:通過創建具有輕微變化的同一圖像的多個副本來增強數據。
這種技術可以創造奇蹟,並以極低的成本生成大量額外的圖像。您可以嘗試裁剪,旋轉,平移或縮放圖像。您可以添加 噪點,模糊,改變顏色或阻擋部分噪音。在所有情況下,您需要確保數據仍然代表同一個類。

這可能非常強大,因為堆疊這些效果會為您的數據集提供指數級的樣本。請注意,這通常不如收集更多 原始 數據。

注意事項:所有增強技術可能無法用於您的問題。例如,如果要歸類檸檬和酸橙,不與色相玩,因為這將是有意義顏色是對分類重要。

問題2:低質量的分類
這很簡單,但如果可能的話,花些時間瀏覽一下您的數據集,並驗證每個樣本的標籤。這可能需要一段時間,但在數據集中使用反例會對 學習過程產生不利影響。
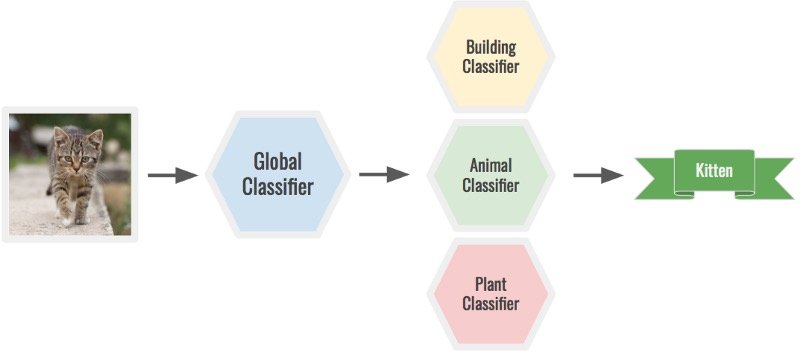
此外,為您的類選擇正確的粒度級別。根據問題,您可能需要更多或更少的類。例如,您可以使用全局分類器對小貓的圖像進行分類,以確定它是動物,然後通過動物分類器運行它以確定它是小貓。一個巨大的模型可以做到這兩點,但它會更難。
問題3:低質量的數據
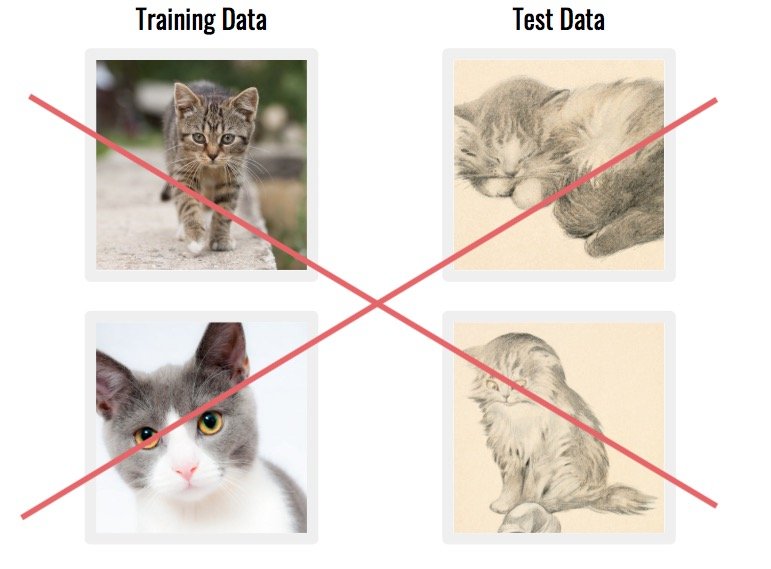
如引言中所述,低質量數據只會導致低質量的結果。
數據集中的數據集中的樣本可能與您要使用的數據集相差太遠。這些可能會更混亂的模式不是很有幫助。
解決方案:刪除最糟糕的圖像。
這是一個漫長的過程,但會改善您的結果。

另一個常見問題是當您的數據集由與真實世界應用程序不 匹配的數據組成時。例如,如果圖像來自完全不同的來源。
解決方案:考慮技術的長期應用,以及將用於獲取生產數據的方法。
如果可能,嘗試使用相同的工具查找/構建數據集。
問題4:不平衡的分類
如果數每類樣本的不是大致的相同的所有類,模型可能有利於統治階級的傾向,因為它會導致一個較低的 錯誤。我們說該模型存在偏差,因為類分布是偏態的。這是一個嚴重的問題,也是您需要查看精度,召回或混淆矩陣的原因。
解決方案1:收集代表性不足的分類的更多樣本。
然而,這在時間和金錢上通常 是昂貴的,或者根本不可行。
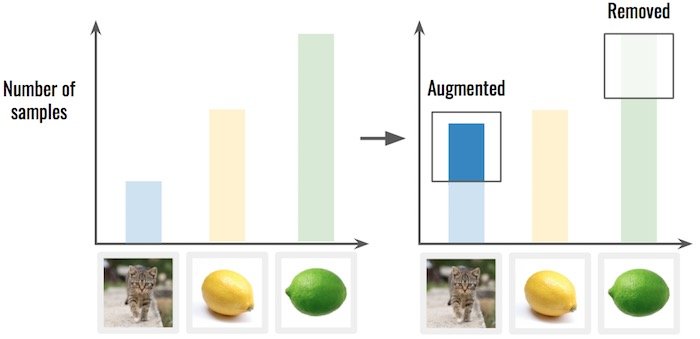
解決方案2:對數據進行過度/不足的採樣。
這意味着您從過度表示的類中刪除一些樣本,或從代表不足的類中複製樣本。比重複更好,使用數據增加,如前所述。
問題5:數據不平衡
如果您的數據沒有特定 格式,或者值不在特定 範圍內,則您的模型可能無法處理它。你將有形象,有更好的結果橫寬比和像素值。
解決方案1:裁剪或拉伸數據,使其具有與其他樣本相同的方面或格式。

解決方案2:規範化數據,使每個樣本的數據都在相同的值範圍內。

問題6:沒有驗證集和測試集
清理,擴充和正確標記數據集後,需要將其拆分。許多人通過以下方式將其拆分:80%用於訓練,20%用於測試,這 使您可以輕鬆發現過度裝配。但是,如果您在同一測試集上嘗試多個模型,則會發生其他情況。通過選擇具有最佳測試精度的模型,您實際上過度擬合了測試集。發生這種情況是因為您手動選擇的模型不是其內在模型 值,但其性能上的特定數據集。
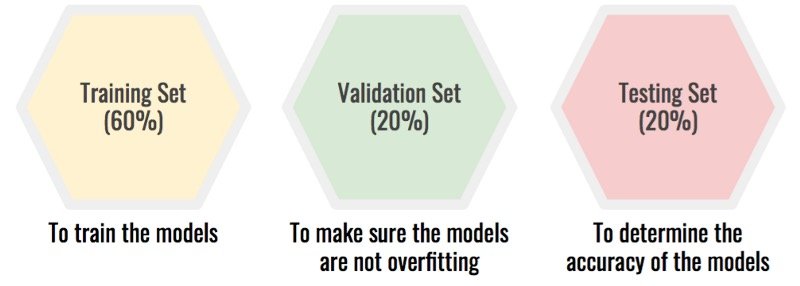
解決方案:將數據集拆分為三個:訓練集、驗證集、測試集。
該屏蔽你的測試被設置過度擬合由模型的選擇。選擇過程變為:
- 在訓練集上訓練你的模型。
- 在驗證集上測試它們以確保沒有過擬合。
- 選擇最有希望的模型。在測試集上測試它,這將為您提供模型的真實準確性。
結論
我希望到現在你確信在考慮你的模型之前你必須注意你的數據集。您現在知道處理數據的最大錯誤,如何避免陷阱,以及如何構建殺手數據集的提示和技巧!如有疑問,請記住:“獲勝者是不是一個最好的模式,這是一個最好的數據。”。
原文:Stop Feeding Garbage To Your Model! — The 6 biggest mistakes with datasets and how to avoid them.
翻譯:Google 翻譯
校對:打不死的小強、杜船

8 Comments
翻譯得有點人工智障了
哈哈,機器翻譯還有待提高。目前這種程度已經可以理解文章大意了,不要在意那些細節
原文在哪兒?
文末有原文的鏈接
人工校核下也不會很耗時間咯
博主比較懶。。。
博主辛苦了,謝謝你願意整理這些資源,並分享出來 😀
我會持續關注博主你的!!
感謝您的認可