

劉璟,百度NLP資深研發工程師、閱讀理解與問答技術負責人。本文根據作者2019年5月26日在「2019自然語言處理前沿論壇」自動問答主題的特邀報告整理而成。
本報告分為以下4個部分:
· 什麼是機器閱讀理解?
· 閱讀理解技術的進步
· 閱讀理解的更多挑戰
· 百度閱讀理解技術的研究工作
1、什麼是機器閱讀理解?
機器閱讀理解,大家對其並不陌生,在我們過去參加的各種語言考試當中都會有閱讀理解的題目,基本上題目都會要求答題者閱讀完一篇給定的文章之後回答相關的問題,這裡如果把答題者換成機器就可以認為是機器閱讀理解。
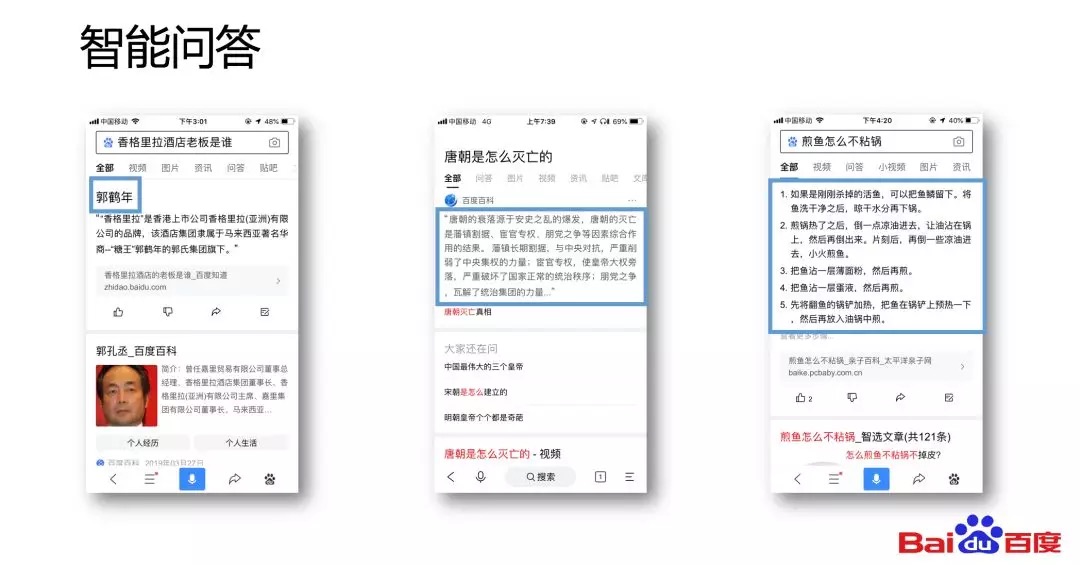
閱讀理解題目的形式是非常多樣的,包括選擇題、回答題等。但是從主流的學術研究和技術落地來看,我們更加關注抽取式數據理解。抽取式數據理解是指給定篇章P和問題Q,我們希望從P當中抽取出答案A,並且通常答案A是篇章P當中的連續片段。下圖提供了一篇文章中關於香格里拉酒店的段落,如果我們問香格里拉酒店的老闆是誰,我們希望機器能夠從篇章P當中抽取出答案。

我們研究機器閱讀理解的意義是什麼?從應用價值角度來看,機器閱讀理解能夠解決傳統的檢索式問答最後一公里的難題,也就是精準定位答案。傳統的檢索式問答通常是用戶在輸入一個問題之後,從海量的文檔集中檢索出若干候選文檔,並對這些若干候選文檔做段落切分和排序,最後以段落為單位作為答案直接反饋給用戶。但是通常這樣的段落還包含了較多的冗餘信息,在一些小屏設備,例如智能手機上會浪費很多空間;在一些無屏設備,例如智能音箱上就會播報很多的冗餘信息。因此我們希望使用閱讀理解的技術,能夠對答案進行精準的定位。

得益於近兩年閱讀理解技術的快速進步,百度已經將閱讀理解技術落地在了百度搜索問答當中。如果在百度APP中問剛才所提到的問題,香格里拉酒店的老闆是誰,它就能夠直接返回一個答案。當然除了這樣一些實體或者是數字類的答案,閱讀理解的技術還可以幫助更好地定位一些長答案,如圖例中的「唐朝是怎麼滅亡的」「煎魚怎麼不粘鍋」等這樣的問題。
2、閱讀理解技術的進步
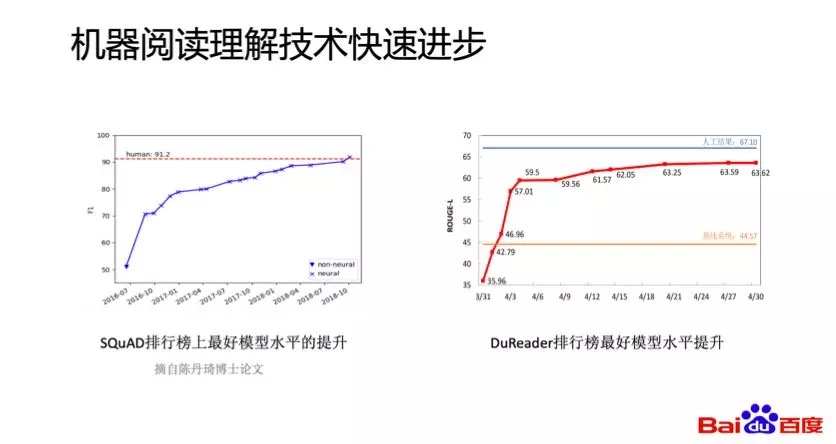
下圖左測是斯坦福發布SQuAD數據集後兩年左右的時間內,其排行榜上的最好模型F1提升了80%;下圖右側是百度發布的DuReader數據集,其排行榜上最好的系統ROUGE-L提升了75%。可以看到技術進步是非常快的,而這些技術進步主要的原因有兩個:一是數據規模的變大,二是深度學習技術的應用。
首先我們看下數據規模的變化,在2016年之前比較大的數據集,比如微軟發布的MCTest只包含了2600餘個問題,SQuAD數據集通過眾包的方式標註了10萬左右的問題,數據集規模直接提高兩了個數量級。之後微軟發布的MSMARCO還有百度的DuReader也分別包含了10萬和30萬個問題。

數據規模的增大也使得深度學習的方法在閱讀理解任務上得到了快速的進步。我們可以看到,在2016年之前,大家使用更多的是統計學習的方法,包含了大量的特徵工程,非常耗時耗力。在2016年之後,SQuAD數據集發布之後,出現了一些基於注意力機制的匹配模型,比如BiDAF、LSTM等等。這之後出現了各種網路結構比較複雜的模型,相關工作試圖通過複雜的網路結構去捕捉問題和篇章之間的匹配關係。雖然在這個階段跳過了一些複雜的特徵工程,但是似乎我們又陷入了更加複雜的網路結構工程。
在2018年之後,隨著各種預訓練語言模型的出現,閱讀理解模型效果得到了近一步大幅的提升,因為表示層的能力變的很強大,任務相關的網路結構開始變的簡單起來。

3、閱讀理解的更多挑戰
在預訓練語言模型出現了之後,一些比較簡單的閱讀理解數據集得到了比較好的解決,比如SQuAD1.1,而針對語言理解應對的不同挑戰,更多的數據集被提出。這裡面包括了SQuAD2.0,主要是引入了一些無答案的問題;還有面向搜索場景的多文檔的數據集,有微軟的MARCO,還有百度的DuReader;還有面向對話場景的CoQA、QuAC;以及跨篇章推理的數據集HotpotQA;此外還有近兩年比較火的,希望能夠通過引入外部知識來做閱讀理解的數據集,比如ReCoRD、CommonsenseQA等等。

4、百度閱讀理解技術的研究工作
我會重點介紹百度面向搜索的多文檔閱讀理解上的研究工作V-NET,以及在引入外部知識閱讀理解任務上的工作KT-NET,分別發表在去年和今年的ACL上。

首先我們介紹一下面向搜索場景的多文檔閱讀理解工作。面向搜索場景的多文檔閱讀理解任務和單文檔閱讀理解任務比較大的不同有兩點:
一、這裡面的問題都是來自搜索場景的真實問題;
二、每一個問題都包含了多個候選段落。

這樣的特點為語言理解帶來了一些挑戰,因為每一個問題包含了多個候選文檔,因此可能會包含較多的歧義和混淆的信息。從下圖的這個例子來看,這個問題是問細胞混合培養和純培養的區別,這裡面的關鍵詞Culture我們通常看到的意思是文化,實際上在這個問題裡面指的是細胞的培養。可以看到在若干個候選文檔當中,有些包含了文化的意思,有些包含了細胞培養的意思,這就為閱讀理解模型的預測帶來了一定的挑戰。

雖然存在這樣的挑戰,但是如果我們通過仔細的觀察會發現,事實上有一些候選文檔只包含了部分和正確答案相關的信息,如果我們從每一個文檔都抽取一個候選答案,讓這些答案之間互相驗證或者互相投票,也許能夠幫助我們更好的定位到正確答案。

基於剛才的idea,我們提出了面向多文檔閱讀理解的模型V-NET。V-NET主要的創新點在於,在BiDAF的基礎之上,引入基於注意力機制的答案校驗。從下圖可以看出,前三層是使用BiDAF對每一個文檔進行答案抽取。在抽取出答案之後,在第四層我們希望獲得每一個答案的表示,在最後一層我們希望在這個表示之下讓答案之間互相做驗證,進而更精準的定位到答案。同時我們還可以看到模型的最後三層,實際上都規定了各自的任務,我們還可以進一步引入聯合訓練。

下圖為實驗結果,我們在MSMARCO上做了實驗,V-Net的效果超過了R-Net和S-Net等,無論是多答案的校驗、聯合訓練還是答案的表示,都讓模型獲得了正向的收益。同時在去年該模型在MSMARCO數據集排行榜上三次獲得了第一。

第二個工作,引入外部知識的閱讀理解,這是我們今年被ACL錄取的一篇論文。所謂引入知識的閱讀理解是指我們希望在做閱讀理解的時候不僅依靠文檔的內容進行理解,同時也需要一些外部的知識作為支撐,這樣才能夠正確的回答問題或者更好的回答問題。
舉個例子,下圖左邊這個問題「《人在囧途》是誰的代表作」,基於文本表示的閱讀理解抽取出來的答案是「李衛」。這裡我們可以觀察到,模型能夠較好的捕捉到答案的類型。但是當一個片段中包含多個類型相同的侯選答案的時候模型就很容易犯錯,所以在這個例子中,模型沒有抽取出正確的答案「徐崢」,而是把「李衛」當做一個正確的答案。如果我們能夠從知識庫當中獲取到一些外部的知識,例如能告訴我們徐崢是一個演員,很有可能模型能夠通過演員和代表作相關的信息正確地判斷出答案。

基於這個idea,我們提出了文本表示和知識表示融合的模型,叫做KT-NET,這裡K是指Knowledge,T就是Text。KT-NET中,第一步我們使用預訓練的語言模型,對問題和文檔中的每一個詞進行編碼表示;第二步我們使用一些傳統的方式對知識庫中的關係或者實體進行預訓練編碼表示;第三步我們會從知識庫當中檢索到一些和文本相關的知識,同時獲取這些知識的預訓練表示。因為這些相關的候選知識是比較多的,所以我們還進一步希望通過注意力的機制,將最相關的知識和文本表示進行融合,在融合的基礎之上獲得了一個知識增強的文本表示,最後在這樣一個知識增強的文本表示基礎之上預測答案,這就是KT-NET主要結構。

我們也在兩個數據集——ReCoRD和SQuAD上做了實驗,最後發現KT-NET在這兩個數據集上都獲得了比BERT_large要好的效果。這個論文相關的工作也會以PaddleNLP的形式在GitHub上進行開源。

除了在技術上不斷投入,我們還希望能夠利用百度的數據優勢推動中文機器閱讀理解技術的一些進步。所以我們去年發布了面向搜索場景的中文閱讀理解數據集DuReader 2.0,相比於SQuAD數據集,DuReader主要有四個特點:首先,DuReader數據集中的問題都是來自於搜索的真實問題;其次,數據中的文檔是來自全網的真實文檔;第三,DuReader數據集目前是最大規模的中文數據集;第四,數據集當中包含了豐富的答案和問題類型標註。因為DuReader數據集當中包含豐富的問題類型標註,所以相比於SQuAD數據集,除了實體類、數據類、描述類和事實類問題,DuReader還包括觀點類和是否類的問題,目前這個數據集也可以通過百度大腦開放數據平台下載。

我們的初衷是使中文閱讀理解技術獲得進步。因此在過去的兩年內,我們和中國中文信息學會和中國計算機學會聯合舉辦了閱讀理解評測任務。在去年的評測中吸引到了1000多個隊伍來報名,也收到1500份結果提交。今年的比賽還在繼續,吸引到了2000多個隊伍來報名。今年我們還提供了基於PaddlePaddle的基線系統,所有的參賽選手都可以在AI Studio上面使用百度提供免費的GPU的計算資源,訓練自己的模型。

講完了百度在機器閱讀理解技術方面的研究和一些應用落地,最後我想從工業應用需求的角度看一下百度還會在哪些方面對閱讀理解技術展開研究。

(1)工業應用中對於模型魯棒性的要求
現在用到的深度學習模型存在著很多模型不穩定,魯棒性的問題,包括過穩定問題和過敏感問題。過穩定問題主要是指問題的語義改變了,但是我們發現模型預測的答案沒有變。過敏感問題是指問題的說法改變了,語義並沒有改變,但是模型預測的答案卻改變了,通常對問題加了一個簡單的問號,答案就改變了。不管是過穩定問題還是過敏感問題,其實都不是我們所期望的,尤其在應用當中,是非常影響用戶體驗的。近兩年學術界有一些研究通過對抗樣本的生成,還有問題複述生成的方式,嘗試解決模型魯棒性的問題。

(2)工業應用中對於模型泛化能力的要求
這兩年我們可以看到很多的新聞,就是某家機構在某個數據集上又超越了人類。但是實際上思考一下,我們會疑惑是不是真的把某一個任務解決好了?其實不是的,我們只能講我們比較好的解決了某一個數據集,而不是真正地解決了某一個任務。在工業應用當中,比如我在百科數據集上訓練了一個模型,當應用到知道數據集的時候,我們期望只需要引入很少量的標註數據就能夠獲得很好的效果,能夠很快很好地遷移到一個新的領域上。後面我們也會投入更多的資源在這方面展開研究,希望能夠真的提高模型的泛化能力,使得這些模型在工業應用當中取得更好的效果。

最後總結一下我們在百度閱讀理解的技術工作,V-NET是面向搜索場景的多文檔閱讀理解,KT-NET是知識表示和文本表示融合模型,以及大規模中文閱讀理解的DuReader數據集。

至此,「2019自然語言處理前沿論壇」自動問答主題《百度閱讀理解技術研究及應用》的分享結束,下一期將分享新的主題,敬請關注。
百度自然語言處理(Natural Language Processing,NLP)以『理解語言,擁有智能,改變世界』為使命,研發自然語言處理核心技術,打造領先的技術平台和創新產品,服務全球用戶,讓複雜的世界更簡單。
本文轉自公眾號 百度NLP,原文地址

Comments