

本文轉載自公眾號 鮮棗課堂,原文鏈接
1998年9月4日,Google公司在美國硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。

無獨有偶,一位名叫Doug Cutting的美國工程師,也迷上了搜索引擎。他做了一個用於文本搜索的函數庫(姑且理解為軟件的功能組件),命名為Lucene。

Lucene是用JAVA寫成的,目標是為各種中小型應用軟件加入全文檢索功能。因為好用而且開源(代碼公開),非常受程序員們的歡迎。
早期的時候,這個項目被發布在Doug Cutting的個人網站和SourceForge(一個開源軟件網站)。後來,2001年底,Lucene成為Apache軟件基金會jakarta項目的一個子項目。

2004年,Doug Cutting再接再勵,在Lucene的基礎上,和Apache開源夥伴Mike Cafarella合作,開發了一款可以代替當時的主流搜索的開源搜索引擎,命名為Nutch。

Nutch是一個建立在Lucene核心之上的網頁搜索應用程序,可以下載下來直接使用。它在Lucene的基礎上加了網絡爬蟲和一些網頁相關的功能,目的就是從一個簡單的站內檢索推廣到全球網絡的搜索上,就像Google一樣。
Nutch在業界的影響力比Lucene更大。
大批網站採用了Nutch平台,大大降低了技術門檻,使低成本的普通計算機取代高價的Web服務器成為可能。甚至有一段時間,在硅谷有了一股用Nutch低成本創業的潮流。
隨着時間的推移,無論是Google還是Nutch,都面臨搜索對象“體積”不斷增大的問題。
尤其是Google,作為互聯網搜索引擎,需要存儲大量的網頁,並不斷優化自己的搜索算法,提升搜索效率。

在這個過程中,Google確實找到了不少好辦法,並且無私地分享了出來。
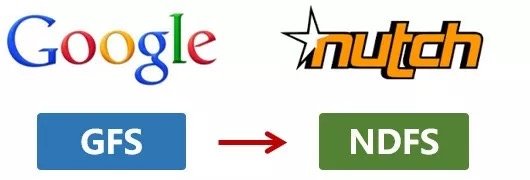
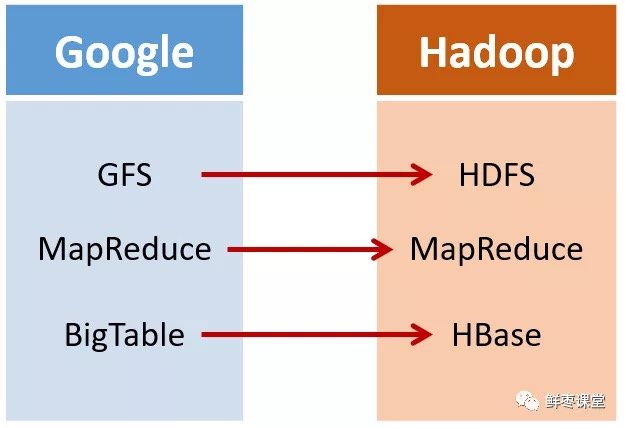
2003年,Google發表了一篇技術學術論文,公開介紹了自己的谷歌文件系統GFS(Google File System)。這是Google公司為了存儲海量搜索數據而設計的專用文件系統。
第二年,也就是2004年,Doug Cutting基於Google的GFS論文,實現了分布式文件存儲系統,並將它命名為NDFS(Nutch Distributed File System)。
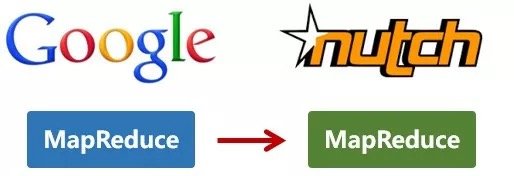
還是2004年,Google又發表了一篇技術學術論文,介紹自己的MapReduce編程模型。這個編程模型,用於大規模數據集(大於1TB)的並行分析運算。
第二年(2005年),Doug Cutting又基於MapReduce,在Nutch搜索引擎實現了該功能。
2006年,當時依然很厲害的Yahoo(雅虎)公司,招安了Doug Cutting。

這裡要補充說明一下雅虎招安Doug的背景:2004年之前,作為互聯網開拓者的雅虎,是使用Google搜索引擎作為自家搜索服務的。在2004年開始,雅虎放棄了Google,開始自己研發搜索引擎。所以。。。
加盟Yahoo之後,Doug Cutting將NDFS和MapReduce進行了升級改造,並重新命名為Hadoop(NDFS也改名為HDFS,Hadoop Distributed File System)。
這個,就是後來大名鼎鼎的大數據框架系統——Hadoop的由來。而Doug Cutting,則被人們稱為Hadoop之父。

Hadoop這個名字,實際上是Doug Cutting他兒子的黃色玩具大象的名字。所以,Hadoop的Logo,就是一隻奔跑的黃色大象。

我們繼續往下說。
還是2006年,Google又發論文了。
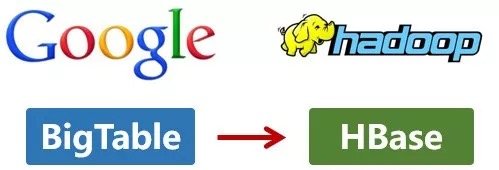
這次,它們介紹了自己的BigTable。這是一種分布式數據存儲系統,一種用來處理海量數據的非關係型數據庫。
Doug Cutting當然沒有放過,在自己的hadoop系統裡面,引入了BigTable,並命名為HBase。
好吧,反正就是緊跟Google時代步伐,你出什麼,我學什麼。
所以,Hadoop的核心部分,基本上都有Google的影子。
2008年1月,Hadoop成功上位,正式成為Apache基金會的頂級項目。
同年2月,Yahoo宣布建成了一個擁有1萬個內核的Hadoop集群,並將自己的搜索引擎產品部署在上面。
7月,Hadoop打破世界紀錄,成為最快排序1TB數據的系統,用時209秒。
此後,Hadoop便進入了高速發展期,直至現在。
Hadoop的核心架構
Hadoop的核心,說白了,就是HDFS和MapReduce。HDFS為海量數據提供了存儲,而MapReduce為海量數據提供了計算框架。

讓我們來仔細看看,它們分別是怎麼工作的。
首先看看HDFS。
整個HDFS有三個重要角色:NameNode(名稱節點)、DataNode(數據節點)和Client(客戶機)。
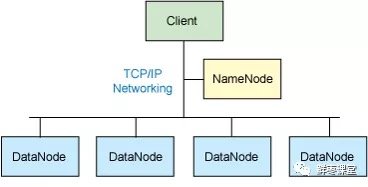
NameNode:是Master節點(主節點),可以看作是分布式文件系統中的管理者,主要負責管理文件系統的命名空間、集群配置信息和存儲塊的複製等。NameNode會將文件系統的Meta-data存儲在內存中,這些信息主要包括了文件信息、每一個文件對應的文件塊的信息和每一個文件塊在DataNode的信息等。
DataNode:是Slave節點(從節點),是文件存儲的基本單元,它將Block存儲在本地文件系統中,保存了Block的Meta-data,同時周期性地將所有存在的Block信息發送給NameNode。
Client:切分文件;訪問HDFS;與NameNode交互,獲得文件位置信息;與DataNode交互,讀取和寫入數據。
還有一個Block(塊)的概念:Block是HDFS中的基本讀寫單元;HDFS中的文件都是被切割為block(塊)進行存儲的;這些塊被複制到多個DataNode中;塊的大小(通常為64MB)和複製的塊數量在創建文件時由Client決定。
我們來簡單看看HDFS的讀寫流程。
首先是寫入流程:
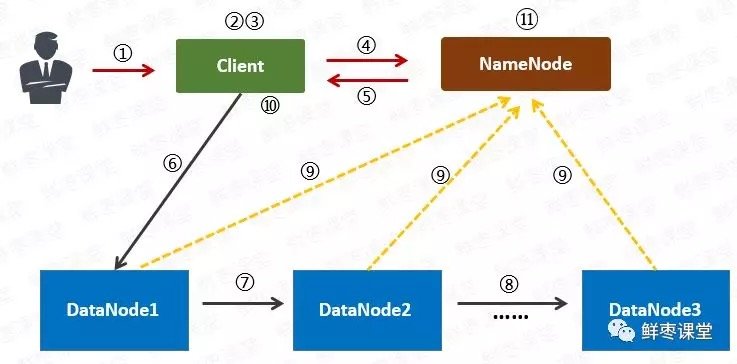
- 用戶向Client(客戶機)提出請求。例如,需要寫入200MB的數據。
- Client制定計劃:將數據按照64MB為塊,進行切割;所有的塊都保存三份。
- Client將大文件切分成塊(block)。
- 針對第一個塊,Client告訴NameNode(主控節點),請幫助我,將64MB的塊複製三份。
- NameNode告訴Client三個DataNode(數據節點)的地址,並且將它們根據到Client的距離,進行了排序。
- Client把數據和清單發給第一個DataNode
- 第一個DataNode將數據複製給第二個DataNode。
- 第二個DataNode將數據複製給第三個DataNode。
- 如果某一個塊的所有數據都已寫入,就會向NameNode反饋已完成。
- 對第二個Block,也進行相同的操作。
- 所有Block都完成後,關閉文件。NameNode會將數據持久化到磁盤上。
讀取流程:
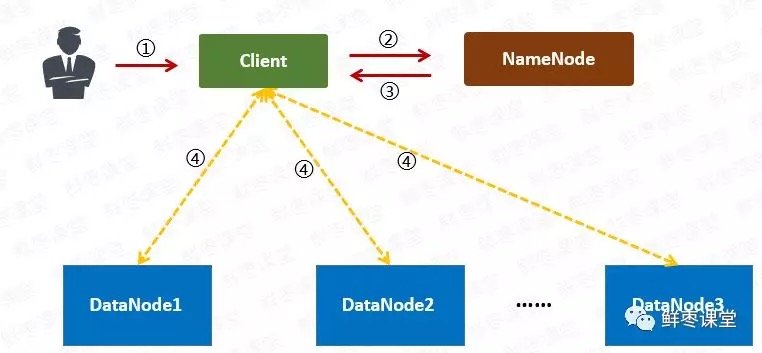
- 用戶向Client提出讀取請求。
- Client向NameNode請求這個文件的所有信息。
- NameNode將給Client這個文件的塊列表,以及存儲各個塊的數據節點清單(按照和客戶端的距離排序)。
- Client從距離最近的數據節點下載所需的塊。
(注意:以上只是簡化的描述,實際過程會更加複雜。)
再來看MapReduce。
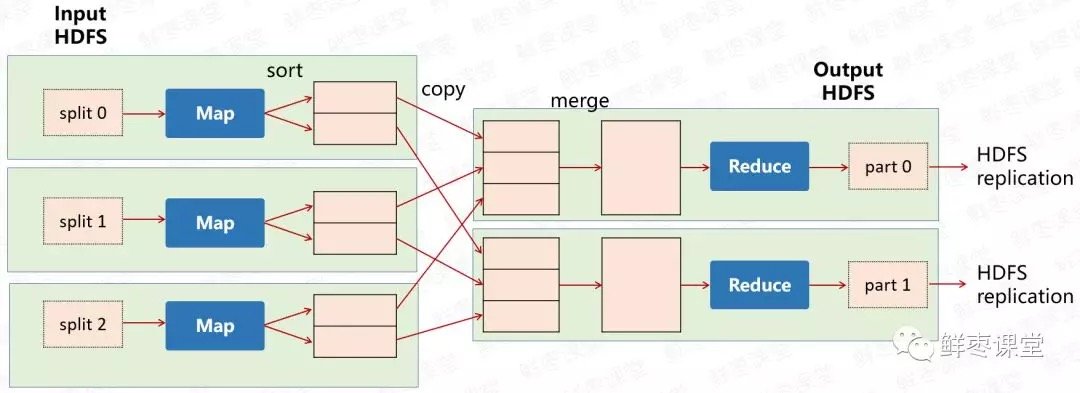
MapReduce其實是一種編程模型。這個模型的核心步驟主要分兩部分:Map(映射)和Reduce(歸約)。
當你向MapReduce框架提交一個計算作業時,它會首先把計算作業拆分成若干個Map任務,然後分配到不同的節點上去執行,每一個Map任務處理輸入數據中的一部分,當Map任務完成後,它會生成一些中間文件,這些中間文件將會作為Reduce任務的輸入數據。Reduce任務的主要目標就是把前面若干個Map的輸出匯總到一起並輸出。
是不是有點暈?我們來舉個例子。
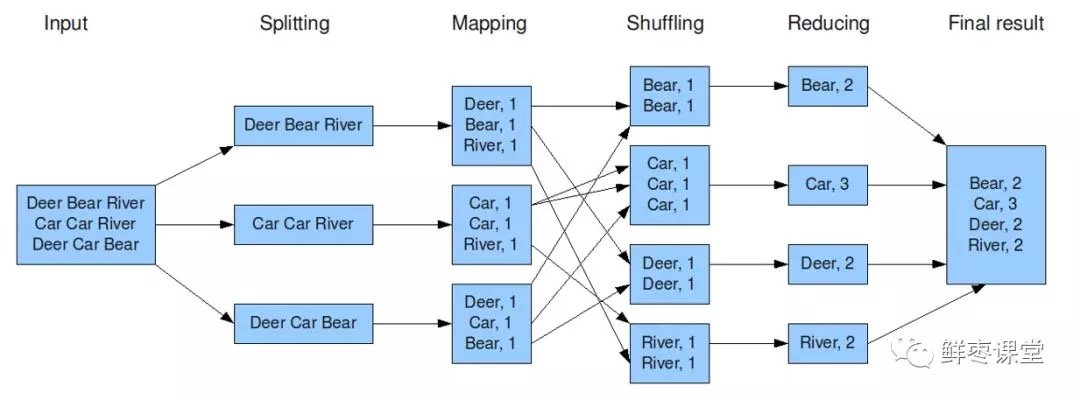
- Hadoop將輸入數據切成若干個分片,並將每個split(分割)交給一個map task(Map任務)處理。
- Mapping之後,相當於得出這個task裡面,每個詞以及它出現的次數。
- shuffle(拖移)將相同的詞放在一起,並對它們進行排序,分成若干個分片。
- 根據這些分片,進行reduce(歸約)。
- 統計出reduce task的結果,輸出到文件。
如果還是沒明白的吧,再舉一個例子。
一個老師有100份試卷要閱卷。他找來5個幫手,扔給每個幫手20份試卷。幫手各自閱卷。最後,幫手們將成績匯總給老師。很簡單了吧?
MapReduce這個框架模型,極大地方便了編程人員在不會分布式並行編程的情況下,將自己的程序運行在分布式系統上。
哦,差點忘了,在MapReduce里,為了完成上面這些過程,需要兩個角色:JobTracker和TaskTracker。
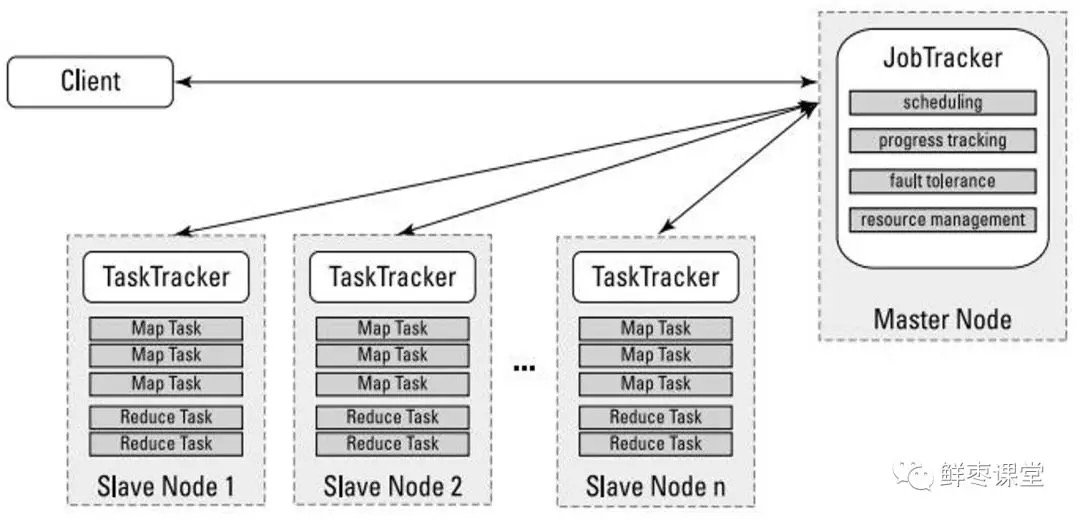
JobTracker用於調度和管理其它的TaskTracker。JobTracker可以運行於集群中任一台計算機上。TaskTracker 負責執行任務,必須運行於 DataNode 上。
1.0版本與2.0版本
2011年11月,Hadoop 1.0.0版本正式發布,意味着可以用於商業化。
但是,1.0版本中,存在一些問題:
1 擴展性差,JobTracker負載較重,成為性能瓶頸。
2 可靠性差,NameNode只有一個,萬一掛掉,整個系統就會崩潰。
3 僅適用MapReduce一種計算方式。
4 資源管理的效率比較低。
所以,2012年5月,Hadoop推出了 2.0版本 。
2.0版本中,在HDFS之上,增加了YARN(資源管理框架)層。它是一個資源管理模塊,為各類應用程序提供資源管理和調度。
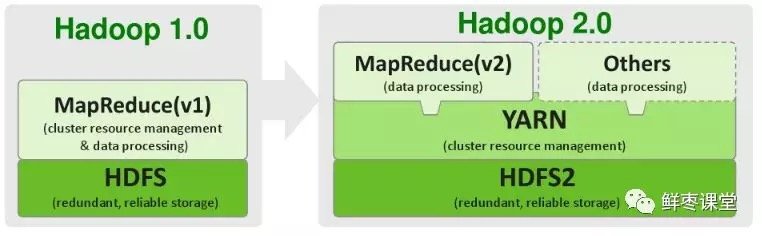
此外,2.0版本還提升了系統的安全穩定性。
所以,後來行業里基本上都是使用2.0版本。目前Hadoop又進一步發展到3.X版本。
Hadoop的生態圈
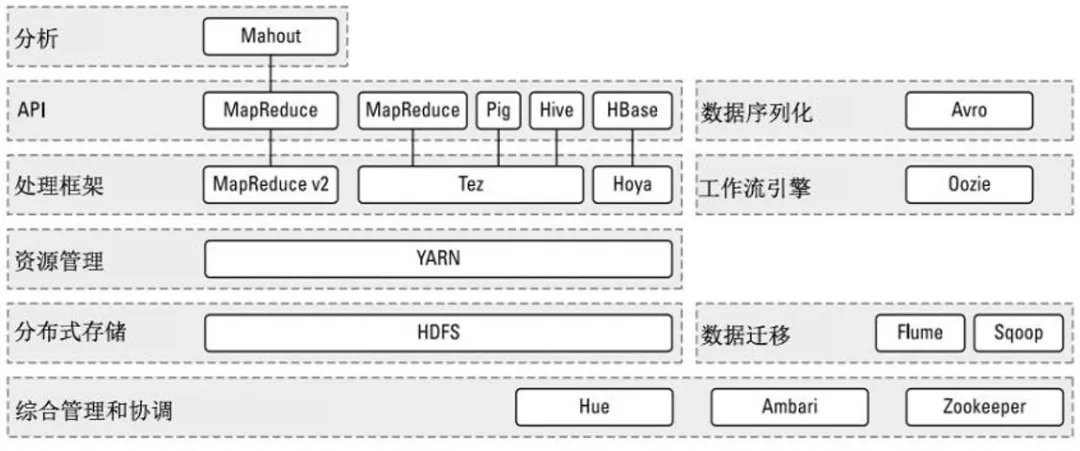
經過時間的累積,Hadoop已經從最開始的兩三個組件,發展成一個擁有20多個部件的生態系統。
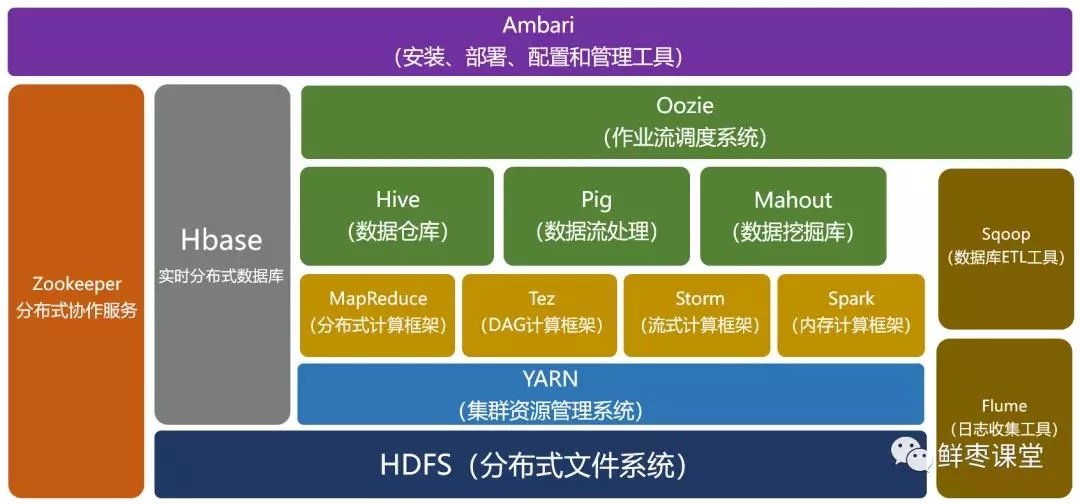
在整個Hadoop架構中,計算框架起到承上啟下的作用,一方面可以操作HDFS中的數據,另一方面可以被封裝,提供Hive、Pig這樣的上層組件的調用。
我們簡單介紹一下其中幾個比較重要的組件。
HBase:來源於Google的BigTable;是一個高可靠性、高性能、面向列、可伸縮的分布式數據庫。
Hive:是一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。
Pig:是一個基於Hadoop的大規模數據分析工具,它提供的SQL-LIKE語言叫Pig Latin,該語言的編譯器會把類SQL的數據分析請求轉換為一系列經過優化處理的MapReduce運算。
ZooKeeper:來源於Google的Chubby;它主要是用來解決分布式應用中經常遇到的一些數據管理問題,簡化分布式應用協調及其管理的難度。
Ambari:Hadoop管理工具,可以快捷地監控、部署、管理集群。
Sqoop:用於在Hadoop與傳統的數據庫間進行數據的傳遞。
Mahout:一個可擴展的機器學習和數據挖掘庫。
再上一張圖,可能看得更直觀一點:
Hadoop的優點和應用
總的來看,Hadoop有以下優點:
高可靠性:這個是由它的基因決定的。它的基因來自Google。Google最擅長的事情,就是“垃圾利用”。Google起家的時候就是窮,買不起高端服務器,所以,特別喜歡在普通電腦上部署這種大型系統。雖然硬件不可靠,但是系統非常可靠。
高擴展性:Hadoop是在可用的計算機集群間分配數據並完成計算任務的,這些集群可以方便地進行擴展。說白了,想變大很容易。
高效性:Hadoop能夠在節點之間動態地移動數據,並保證各個節點的動態平衡,因此處理速度非常快。
高容錯性:Hadoop能夠自動保存數據的多個副本,並且能夠自動將失敗的任務重新分配。這個其實也算是高可靠性。
低成本:Hadoop是開源的,依賴於社區服務,使用成本比較低。
基於這些優點,Hadoop適合應用於大數據存儲和大數據分析的應用,適合於服務器幾千台到幾萬台的集群運行,支持PB級的存儲容量。
Hadoop的應用非常廣泛,包括:搜索、日誌處理、推薦系統、數據分析、視頻圖像分析、數據保存等,都可以使用它進行部署。

目前,包括Yahoo、IBM、Facebook、亞馬遜、阿里巴巴、華為、百度、騰訊等公司,都採用Hadoop構建自己的大數據系統。
除了上述大型企業將Hadoop技術運用在自身的服務中外,一些提供Hadoop解決方案的商業型公司也紛紛跟進,利用自身技術對Hadoop進行優化、改進、二次開發等,然後對外提供商業服務。
比較知名的,是Cloudera公司。

它創辦於2008年,專業從事基於Hadoop的數據管理軟件銷售和服務,還提供Hadoop相關的支持、諮詢、培訓等服務,有點類似於RedHat在Linux世界中的角色。前面我們提到的Hadoop之父,Doug Cutting,都被這家公司聘請為首席架構師。
Hadoop和Spark
最後,我再介紹一下大家關心的Spark。

Spark同樣是Apache軟件基金會的頂級項目。它可以理解為在Hadoop基礎上的一種改進。
它是加州大學伯克利分校AMP實驗室所開源的類Hadoop MapReduce的通用並行框架。相對比Hadoop,它可以說是青出於藍而勝於藍。

前面我們說了,MapReduce是面向磁盤的。因此,受限於磁盤讀寫性能的約束,MapReduce在處理迭代計算、實時計算、交互式數據查詢等方面並不高效。但是,這些計算卻在圖計算、數據挖掘和機器學習等相關應用領域中非常常見。
而Spark是面向內存的。這使得Spark能夠為多個不同數據源的數據提供近乎實時的處理性能,適用於需要多次操作特定數據集的應用場景。
在相同的實驗環境下處理相同的數據,若在內存中運行,那麼Spark要比MapReduce快100倍。其它方面,例如處理迭代運算、計算數據分析類報表、排序等,Spark都比MapReduce快很多。
此外,Spark在易用性、通用性等方面,也比Hadoop更強。
所以,Spark的風頭,已經蓋過了Hadoop。

Comments