

本文轉載自公眾號 微軟研究院AI頭條,原文地址
編者按:知識圖譜作為一種特殊的圖數據,不僅人類可以識別且對機器友好。信息檢索、問答系統、推薦系統、電子商務、金融風控,這些生活中常見的應用場景都離不開知識圖譜的支持。如何構建一個「多快好省」的知識服務系統?微軟亞洲研究院機器學習組的研究員們基於自己的經驗,給出了他們的建議。
近年來,隨著人工智慧技術在科研和實踐中的廣泛發展和應用,知識圖譜作為人工智慧的重要課題也得到迅速發展。包含上億條事實的公開知識圖譜已經非常常見,並且不同的數據源又互相聯結相通,形成了數以百億計的超大規模知識圖譜。與此同時,隨著自然語言處理、深度學習等技術的發展,知識圖譜的抽取技術也在不斷進步,增量的知識圖譜數據不斷匯入。
一方面,知識的普遍性和關聯性等特點決定了知識圖譜只有在到達一定的數量級和覆蓋率時才能真正發揮其能量;另一方面,常用知識表示方法(比如三元組)的靈活性和碎片化等特點,也讓知識圖譜數據的管理變得困難。在知識圖譜數據已經成為一個不斷快速生長的龐然大物的背景下,如何讓海量知識變得可用且好用已經成為當前知識型應用的緊迫需求。
同一套知識圖譜數據可以在不同應用中通用,同時對於用戶而言,構建一套全新的數據系統是一項冗餘和繁雜的工作。因此,為知識型應用提供在線可用或下載即可用的數據服務成為一種知識圖譜的高效應用方式。本文中,我們將這種在線或離線提供知識圖譜數據服務的方式稱為「知識圖譜即服務」。
本文將從數據、應用及挑戰等角度詳細闡述如何高效地管理和服務超大規模知識圖譜數據,並分享作者所在團隊在設計和實現百億量級知識圖譜實時服務中的一些案例經驗。
知識圖譜:圖視角下的知識
英國哲學家弗朗西斯·培根有句名言:「知識就是力量」。Stuart J.Russell 和 Peter Norvig 在《人工智慧:一種現代方法》一書中指出,人工智慧包括自然語言處理、知識表示、自動推理、機器學習、計算機視覺以及機器人技術。知識表示對於人工智慧的重要性不言而喻。實際上,機器學習得到的模型也是一種用計算結構和數值表示的知識。
在眾多知識表示方式中,知識圖譜作為一種語義網路擁有極強的表達能力和建模靈活性:首先,知識圖譜是一種語義表示,可以對現實世界中的實體、概念、屬性以及它們之間的關係進行建模;其次,知識圖譜是其衍生技術的數據交換標準,其本身是一種數據建模的「協議」,相關技術涵蓋知識抽取、知識集成、知識管理和知識應用等各個環節。
知識圖譜是一種特殊的圖數據,它是語義的和可復用的:知識圖譜數據一經獲取即可被多領域應用重複使用,這也是知識圖譜服務的構建動機。那麼,知識圖譜具體來說是什麼呢?
首先,知識圖譜是一種特殊的圖數據。具體來說,知識圖譜是一種帶標記的有向屬性圖。知識圖譜中每個結點都有若干個屬性和屬性值,實體與實體之間的邊表示的是結點之間的關係,邊的指向方向表示了關係的方向,而邊上的標記表示了關係的類型。例如,「湯姆·克魯斯」和「碟中諜」是兩個實體,「出演」則是這兩者之間的關係。兩個實體分別對應著現實世界中的人和電影,而邊則對應了他們所表示的人和電影之間的現實關聯。前者是關係的起始結點,後者是關係的目標結點。實體「湯姆·克魯斯」具有「出生日期」等屬性,其屬性值為「1962年7月3日」等。
其次,知識圖譜是一種人類可識別且對機器友好的知識表示。知識圖譜採用了人類容易識別的字元串來標識各元素;同時,圖數據表示作為一種通用的數據結構,可以很容易地被計算機識別和處理。
再次,知識圖譜自帶語義,蘊涵邏輯含義和規則。知識圖譜中的結點對應現實世界中的實體或者概念,每條邊或屬性也對應現實中的一條知識。在此之上,我們可以根據人類定義的規則,推導出知識圖譜數據中沒有明確給出的知識。比如,已知「張三是個人」,我們就可以根據「人都有父母,都有大腦,需要呼吸」等規則得到很多新知識,而無需在知識圖譜中逐條給出。再比如,「外公」的「兒子」是「舅舅」,據此可以推導出很多實體之間的親屬等關係。
下面介紹一下廣泛使用的知識圖譜表示框架和查詢語言:資源描述框架 (ResourceDescription Framework, RDF) 和 SPARQL 查詢語言 (SPARQL Protocol and QueryLanguage, SPARQL) 。
資源描述框架中的基本元素格式為: <主, 謂, 賓> 或 <s, p, o>。它採用主語、謂詞和賓語的方式來表示和陳述一條知識,這種表示方式簡單且靈活。由於資源描述框架的英文縮寫為 RDF,知識圖譜數據集也經常被稱為RDF數據集,而其管理工具通常被稱為RDF Store或Triple Store。在RDF中,我們可以用<Tom_Cruise, Acting, Mission:Impossible>和<Tom_Cruise, Date_Of_Birth, 」July 3, 1962」>等來表示實體「湯姆·克魯斯」的關係和屬性。一個 RDF 數據可以分為兩個部分:
一:顯式三元組。這部分由數據集直接給定。例如:
<Sky, Color, blue>
<Alice, Friend, Bob>
二:隱含三元組。這部分由推理規則隱含表示。規則可作用於顯式三元組,其推導出的三元組數量可能巨大,甚至超過原始數據數倍。例如:
- 如果?x 是一種?y, 而?y是?z的子類型,那麼?x 也是一種?z: (?x, IsA, ?y) & (?y, SubclassOf, ?z) => (?x, IsA, ?z)
- 如果?y是?x的朋友,那麼?x 是?y的朋友: (?x, Friend, ?y) => (?y, Friend, ?x)
代表性的 RDF 數據集包括 Freebase、DBpedia、WikiData、Yago2、Cyc、PubChemRDF以及UniProt等。已有知識圖譜數據中的數據量已達到空前規模,例如 Freebase 包含大約19億的三元組,DBpedia 包含大約30億三元組,而 Bio2RDF 擁有約100億三元組。這些數據集因為鏈接開放數據倡議 (Linked Open Data initiative, LOD) 而互相連通,形成了一個超過1490 億三元組的超大知識圖譜。如果算上它們遵循標準規則集 (如ρdf, RDFSPlus, RDFSFull, OWL DL 等) 可得的隱含三元組,實際的數據量將更為龐大。
SPARQL是一種廣泛使用的知識圖譜查詢語言。它的主要功能是做聲明式的子圖匹配,即只描述最終需要的結果模式,而具體執行的過程由底層數據管理系統決定。一個 SPARQL 查詢的主要組成部分是基本圖模式,比如 (?s, p, ?o),三個元素分別對應主、謂、賓,其中需要匹配的元素用帶問號的變數表示。通過集合交、並、差等操作符號實現組合邏輯。此外,其它的圖查詢語言比如 GraphQL 和Cypher 也可以用於查詢知識圖譜。
知識圖譜應用
國內外各大公司、高校以及研究機構都對知識圖譜進行了探索和構建,比如谷歌的 Google Knowledge Graph、微軟的 Bing Knowledge Graph、搜狗的知立方、 百度知心、阿里巴巴的商品知識圖譜、復旦大學的 CN-DBpedia、東南大學的 Zhishi.me、清華大學的 Xlore 以及開放中文知識圖譜社區 OpenKG 的 cnSchema.org 等。知識圖譜的發展同時也得到了政府的關注和支持,例如中國國務院在《新一代人工智慧發展規劃》 (國發〔2017〕35號) 一文中就明確提出了知識圖譜相關的發展規劃。
作為一種應用型技術,知識圖譜支撐了很多行業中的具體應用。例如:
- 信息檢索:搜索引擎中對實體信息的精準聚合和匹配、對關鍵詞的理解以及對搜索意圖的語義分析等;
- 自然語言理解:知識圖譜中的知識作為理解自然語言中實體和關係的背景信息;
- 問答系統:匹配問答模式和知識圖譜中知識子圖之間的映射;
- 推薦系統:將知識圖譜作為一種輔助信息集成到推薦系統中以提供更加精準的推薦選項;
- 電子商務:構建商品知識圖譜來精準地匹配用戶的購買意願和商品候選集合;
- 金融風控:利用實體之間的關係來分析金融活動的風險以提供在風險觸發後的補救措施(如聯繫人等);
- 公安刑偵:分析實體和實體之間的關係以獲得線索等;
- 司法輔助:法律條文的結構化表示和查詢來輔助案件的判決等;
- 教育醫療:提供可視化的知識表示,用於藥物分析、疾病診斷等;
- ……
那麼知識圖譜在這些應用中是如何被訪問的呢?知識圖譜的服務場景按照其對響應時間的要求可以大體分為在線查詢和離線分析兩類。
在線查詢任務包括:1) 針對實體的查詢,如「作者為蘇軾的詩」;2) 針對屬性的查詢,如「辛棄疾的生卒年」;3) 針對關係的查詢,通過多跳關係搜索實現知識圖譜中的關係發現,如「湯姆·克魯斯和布拉德·皮特一起演的電影所獲獎項」;4) 針對子圖結構的查詢,用於查詢具有某種特定關係的一系列實體,如「參與演出過同一部電影並且具有夫妻關係的演員」;5) 針對查詢的聚合,如「世界十大最高峰所在的國家列表」。這類查詢的特點是:響應延遲敏感,但數據吞吐量低。
離線分析任務包括:1) 基於圖結構的計算,如:知識圖譜向量化表示、知識圖譜數據補全和實體排序等;2) 基於規則的推理;3) 基於整體信息的統計分析等。這類任務對響應時間要求低,但要求高數據吞吐量。
知識圖譜服務的挑戰
那麼,構建知識圖譜服務有什麼難點呢?主要包括以下三點:
一:並行圖處理。作為一類特殊的圖數據,知識圖譜的存儲、查詢以及計算都需要處理和圖結構相關的如下三方面挑戰:
- 圖數據的複雜性。從數據訪問的角度看,無論圖數據如何表示,對一個圖結點鄰居結點的訪問都會涉及到在連續存儲空間中的「跳轉」,即大量的隨機數據訪問。大量程序優化技術依賴於數據的局部性和重用。大量隨機數據訪問會導致中央處理器的緩存在大部分時間裡失效,進而導致系統性能急劇下降。從程序結構的角度看,圖的非結構化特性使得並行處理十分困難。值得一提的是,切分圖數據本身是一個 NP 難問題,這讓分而治之方案的系統設計變得困難。
- 圖結構和計算的多樣性。圖數據類型很多,圖演算法的性能會因為圖特徵不同而大相徑庭。圖計算的類型也有很多種,有針對性的系統優化適用面比較受限。
- 圖數據規模越來越大。大規模的圖數據讓很多經典圖演算法因為低效而不可用。
二:隱含語義信息處理。例如,處理 (?x, Parent, ?y) => (?x, Father, ?y) UNION (?x, Mother, ?y) 和 (?x, Niece, ?y) => (?x, Niece, ?y) UNION (?x, Spouse, ?z) AND (?z, Niece, ?y) 這類基於規則的推理將放大存儲、查詢代價。處理方法一般分為兩類:一類是在查詢之前就將所有隱含的三元組推導出來並作為正常三元組存儲,這類方法會大量增加存儲代價;另一類是在查詢時,按照推理規則將一個查詢重寫成多個查詢,最後匯總查詢結果,這類方法會大大增加查詢代價。而將兩種方法融合的折中方法則會同時放大存儲和查詢代價。
三:複雜的數據模式。知識圖譜的數據模式 (Schema)很複雜,如 『A dog can be also an actor』 (DEFINE 『Actor SubClass Person』?);實體可以多角色,如 『A director who is also an actor, a singer, and a writer』;屬性可以有多值或預設,如 『An actor with many awards』 和 『A person entity without birthday data』 等。數據模式的複雜使得知識的物理存儲和優化變得十分困難。
結合以上對數據特點、查詢特點以及數據模式的分析,我們把一個知識服務系統所面臨的挑戰總結為以下四點:
- 系統架構:實現數據可擴展;
- 存儲設計:處理隨機數據訪問;
- 數據訪問:友好的訪問介面;
- 高效查詢:低延遲和/或高吞吐數據查詢。
這四點彙集起來就是:多、快、好、省。
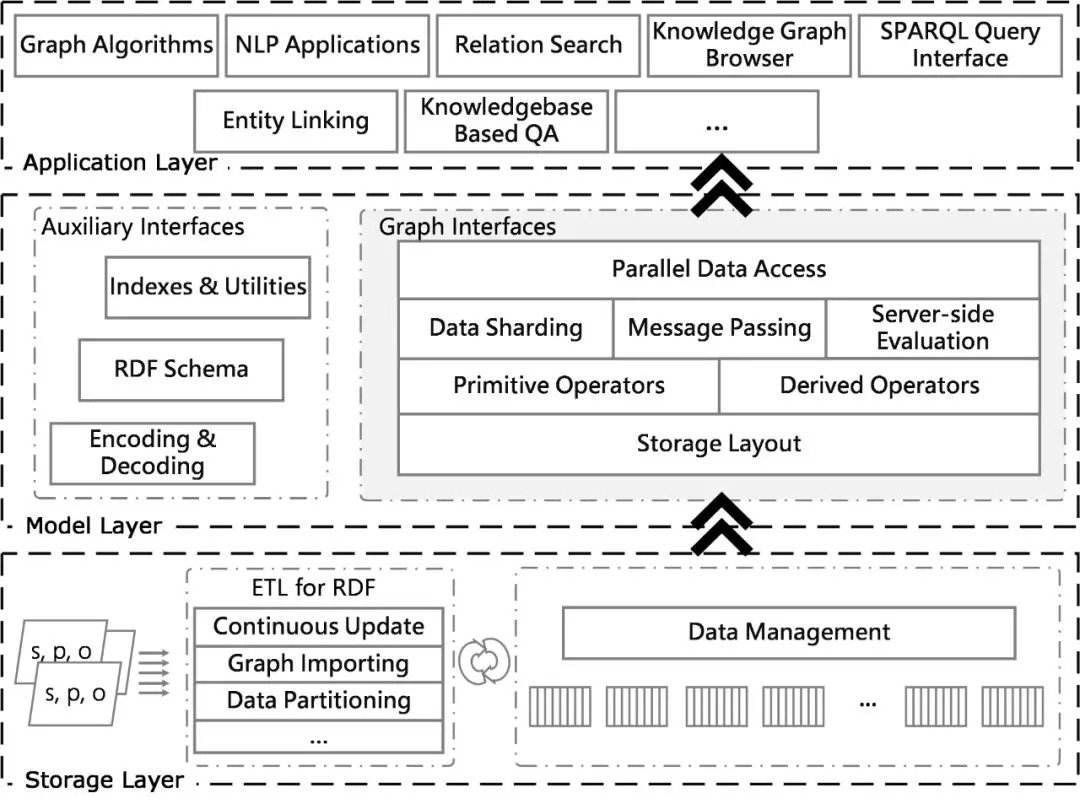
知識圖譜服務的實現
我們先分析底層數據存儲介質。常見的內存 (RAM) 和硬碟 (HDD)的響應速度級別分別為10的負7次方秒和10的負2次方秒,而數據吞吐量分別為3GB/s 左右和100MB/s 左右。傳統硬碟由於其機械尋道機制的限制,數據的隨機化和並行化讀寫性能差。為了滿足高並行和隨機化數據訪問的需求,對延遲敏感的知識圖譜應用一般都選擇內存作為主要的存儲介質。另一方面,由於單機內存容量的限制,向上擴展代價昂貴,我們更傾向於可擴展的內存雲架構。
從存儲架構角度看,單機存儲系統主要為兩類:一類是基於傳統關係資料庫構建的系統,如SW-Store、Triple Tables 等;另一類是針對知識圖譜數據定製的專用存儲查詢系統,如 RDF-3X、TripleBit等。分散式系統大致可以分為分散式文件系統、鍵值存儲系統、中心化的存儲以及混合存儲這四種。
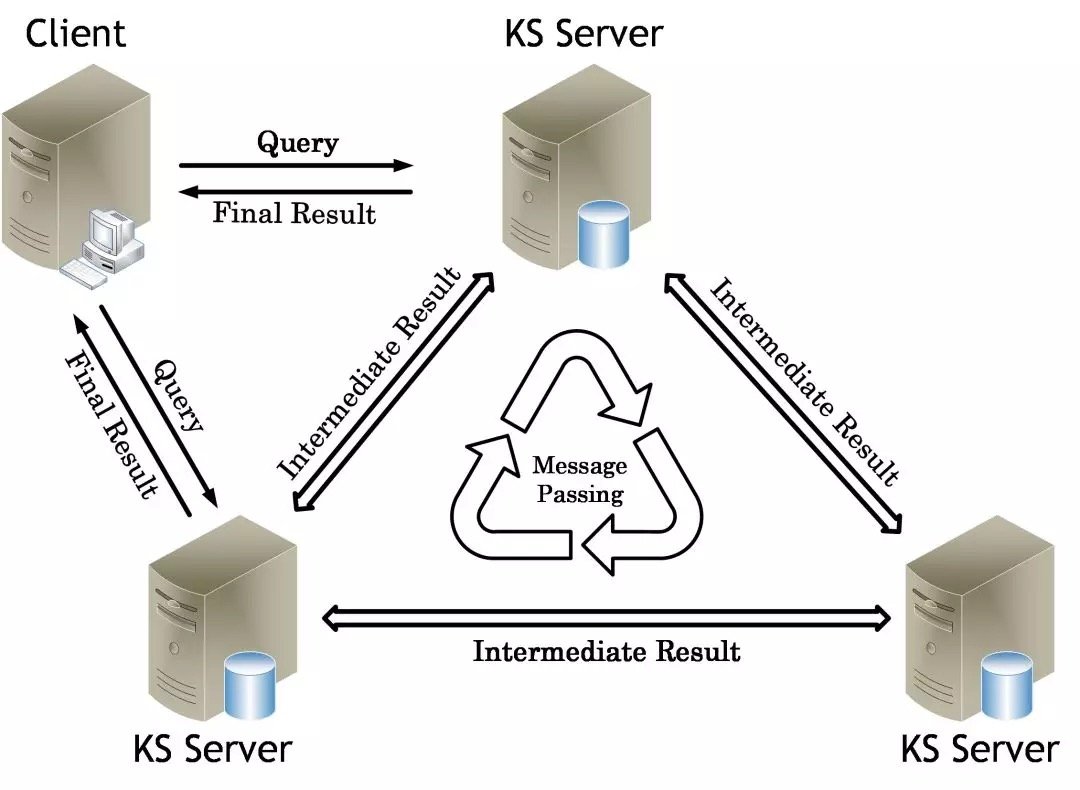
對於上層應用,系統需要提供細粒度的訪問介面。原因如下:首先這些介面可以作為在線查詢的輕量級工具,同時可以作為離線分析的並行化組件,真正實現將N 轉換為1 + 1 + … + 1,其中 N 表示批量的操作,而1表示細粒度的操作。這樣我們將這些1並行執行,就可以獲得與批量處理相當的高吞吐量效果。反之,如果我們只支持批量處理,當系統響應多個細粒度操作時就會變成 N + N + … + N,從而導致資源的浪費和響應速度的下降。
數據存儲和處理模塊作為中間層,向下它基於底層存儲架構(比如內存雲),需要考慮存儲代價敏感和隨機訪問友好兩個特點;同時向上它需要提供細粒度且高效的訪問介面。
數據存儲和處理模塊最核心的部分是知識圖譜數據的物理表示。它負責實現存儲、查詢和更新在內的數據管理,需要解決的核心問題是管理一個可更新的超大規模稀疏三階張量:如果將知識圖譜數據的主語、謂詞和賓語三個部分分別看作三個維度,每一個維度上的取值範圍即知識圖譜中對應位置出現的所有值,那麼整個數據集就可以被一個稀疏的三階張量表示,而知識圖譜的存儲問題也可以轉換為對這個三階張量的壓縮和索引。這個三階張量非常稀疏且分布不均勻,其中主語和賓語這兩維的數量大,可以達到十億量級,而謂詞通常在幾千到上萬的量級。我們需要在存儲和查詢兩個方面同時做到高效,並且支持對各個維度的自由更新。
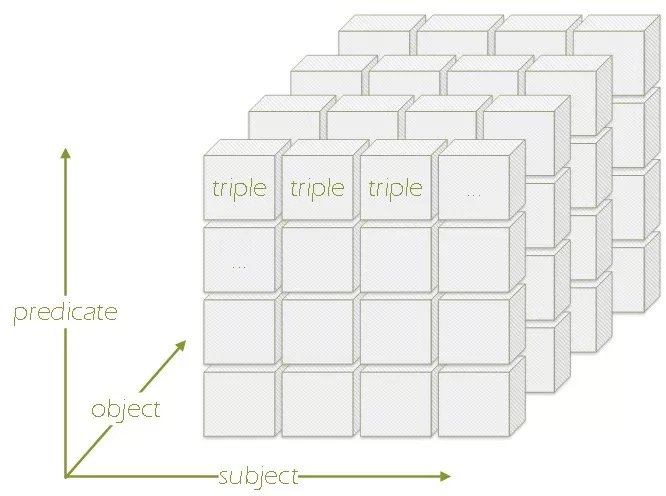
具體的優化目標包括:首先是能夠盡量縮小數據存儲文件的大小;其次是能夠快速地處理各類數據訪問請求;最後是支持增量更新。鑒於物理存儲模型的複雜性和靈活性,常見的一類方法是直接將這個三階張量中的元素(即三元組)作為最小存儲單元進行壓縮表示並建立索引。這種方法對三個元素按位置進行排列組合進行多次存儲,已達到空間換時間的目的。這種方法我們不妨稱為零階展平。另一類方法則將三階張量按某一階展平,如主語(圖數據結構)或謂詞(垂直劃分、比特矩陣等)。最後一類同時按兩階來展平,如主語和謂詞,這一類我們稱為強類型的存儲方案。前面提到的常見數據存儲方案大多屬於弱類型系統,如三元表(簡單直接)或「謂詞-賓語」鍵值列表等。相比於弱類型系統,強類型系統具有更小的數據存儲和訪問代價和更少的聯結操作 (JOIN) 代價。

Comments