

近幾年,深度學習已經徹底改變了計算機視覺。由於各類學習資源隨處可見,任何人都可以在數天(甚至數小時)內掌握最新技術,並將它應用到自己的領域內。隨着深度學習變得越來越普遍,一個重要的問題就是如何將它創造性地應用在不同的領域裡。
今天,計算機視覺領域的深度學習已經解決了大量關於圖像識別、目標檢測和圖像分割等方面的問題。在這些領域中,深度神經網絡表現出了極其優異的性能。
即使你的數據並不是可視化的,同樣可以利用這些視覺領域深度學習模型(特別是 CNN 模型)的強大功能——你所需要做的僅僅是:將你的數據從非視覺領域變換成圖像,然後就可以將由圖像訓練出來的模型應用到你的數據上。理論上而言,任何有局部相關性的數據都能使用卷積網絡處理,因此你會驚奇地發現,這種方法竟然出奇得好。
在這篇文章中,我將簡單介紹 3 個案例,看一下企業如何將視覺深度學習模型創造性地應用到非視覺領域。在這三個案例中,基本方法都是將非視覺問題轉換成適合做圖像分割的問題,然後利用深度學習模型來解決。
案例一:石油工業
梁泵(beam pumps)通常在石油工業中被用來從地下抽取石油或天然氣。它們由連接在步進梁(walking beam)的發動機提供動力。步進梁將發動機的旋轉運動傳遞到抽油桿的垂直往複運動,從而將石油抽取到地面。

作為一個複雜系統,梁泵很容易出現故障。為了輔助診斷,在洗盤上安裝了一個測量梁桿負載的測功機(dynamometer)。測功機會繪製出一個測功機泵卡(dynamometer pump card),如下圖所示,顯示出引擎旋轉周期內的負載。
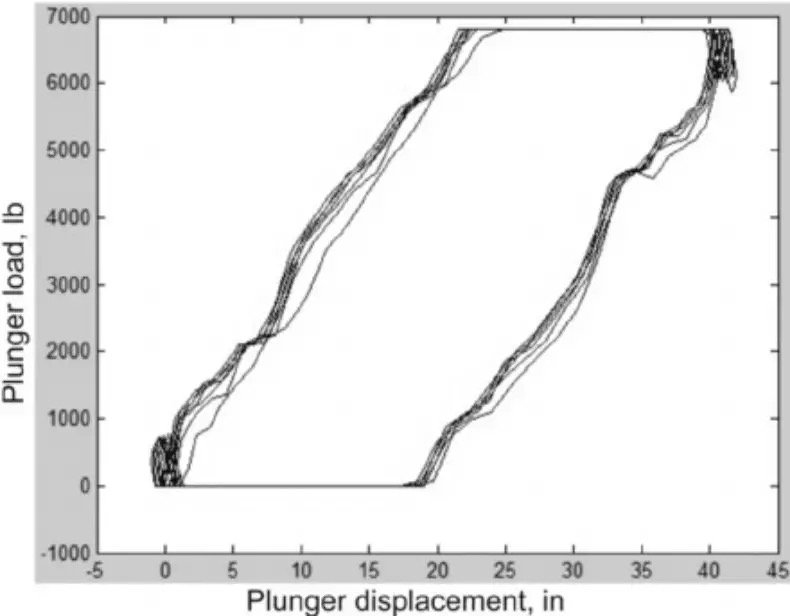
當梁泵出現故障時,測功機卡的形狀就會發生變化。通常情況下會邀請專業技術人員來檢測測功機卡,並判斷哪裡出現問題,並提出解決方案。這個過程非常耗時,且只有極為專業的人士才能有效地解決問題。
另一方面,這個過程看起來完全可以自動化。之前也曾嘗試用過許多經典的機器學習系統來解決這個問題,但結果並不是很好,正確率只有 60% 左右。
貝克休斯(Baker Hughes)作為眾多油田服務公司之一,則採用了一種創新性的方法將深度學習應用到了這個問題上。他們首先將測功機卡轉換成圖像,並將之作為預訓練 ImageNet 模型的輸入。結果非常令人振奮,只使用圖像分類預訓練模型並根據新數據做了些微調,正確率瞬間從 60% 提升到了 93%;對模型進一步的優化後,他們甚至將正確率提高到 97%。
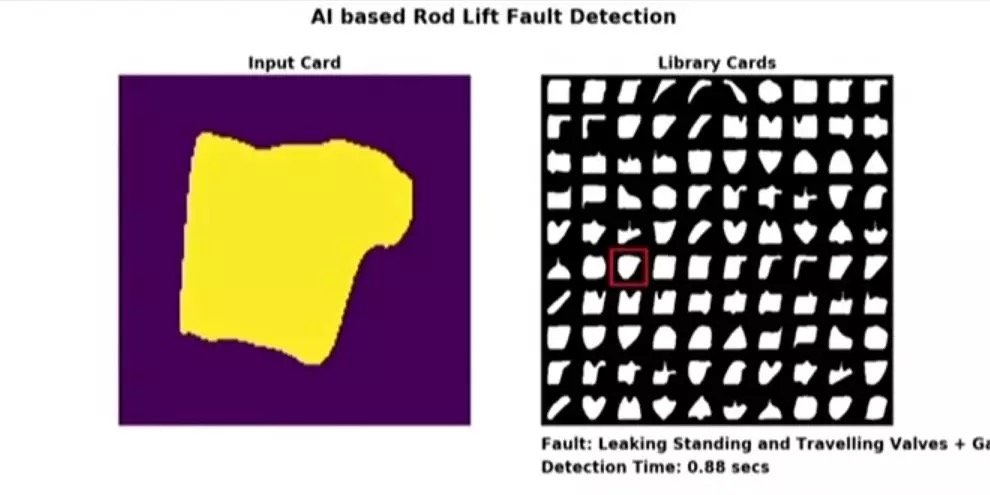
貝克休斯使用系統的一個樣例。左圖是一張輸入圖片,右圖是缺陷模式的實時分類。整個系統只需要在便攜設備上就可以運行,右下角顯示了推斷時間。
貝克休斯採用這種方法不僅獲得了比之前經典機器學習方法更高的精度,甚至他們現在都不再需要梁泵技術專家來花費大量時間診斷問題了。一旦出現機器故障,他們能夠立刻進行修復。
想了解更多關於這個案例的內容,你可以:
- 讀一些類似工作的文章: https://www.knepublishing.com/index.php/KnE-Engineering/article/download/3083/6587
- 或觀看視頻:https://v.qq.com/x/page/h08318aglac.html
案例二:在線欺詐檢測
計算機用戶在使用計算機時具有獨特的模式和習慣,你瀏覽網頁時使用鼠標的方式或你撰寫電子郵件時敲擊鍵盤的方式,都是獨一無二的。
在這種特殊情況下,Splunk 解決了根據用戶使用計算機鼠標的方式對用戶進行分類的問題。如果你的系統可以根據鼠標使用模式唯一識別用戶,則可以將其用於欺詐檢測。想象一下這種情況:欺詐者竊取某人的登錄名和密碼,然後使用它們登錄並在網上商店購物。由於每個人使用計算機鼠標的方式都是獨一無二的,系統可以輕鬆檢測到這種異常並防止發生欺詐性交易,並通知真實賬戶所有者。
使用專門的 JavaScript 代碼就可以收集所有鼠標活動,該程序可以每 5 – 10 毫秒記錄一次鼠標活動。結果,每個用戶的數據將包含每頁每個用戶大約 5000 – 10000 個數據點。這裡有兩個挑戰:第一,每個用戶都有大量的數據;第二,不同用戶的數據集所包含的數據點數量不同。這很不方便,如果序列長度不同,通常需要更為複雜的深度學習框架。
解決方案是將每個用戶在每個網頁上的鼠標活動轉換為單個圖像。在每個圖像中,鼠標移動由一條線表示,其顏色編碼鼠標速度,左右點擊由綠色和紅色圓圈表示。這種處理初始數據的方法解決了這兩個問題:首先,所有圖像具有相同的大小;其次,現在基於圖像的深度學習模型可以與該數據一起使用。

Splunk 使用 TensorFlow + Keras 構建了一個深度學習系統來進行用戶分類,他們進行了兩個實驗:
金融服務網站用戶群體的分類——訪問類似頁面時的常客組和非客戶組。他們使用了一個相對較小的僅包含 2000 張圖像的訓練數據集。在基於 VGG16 的修改架構上訓練僅 2 分鐘後,系統便能夠識別這兩個類別,準確度超過 80%。
用戶的個人分類。任務是針對給定用戶進行預測,來判斷使用者是該用戶還是其他模仿者。同樣是一個非常小的訓練數據集,只有 360 張圖像;同樣是基於 VGG16 的框架,但考慮到數據集較小防止過擬合做了些許調整。經過 3 分鐘的訓練便可以達到約 78% 的準確率,考慮到這種任務本身是挑戰性的,因此這樣的結果還是蠻令人振奮的。
更多信息,可以閱讀關於這個系統和實驗的完整文章:https://www.splunk.com/blog/2017/04/18/deep-learning-with-splunk-and-tensorflow-for-security-catching-the-fraudster-in-neural-networks-with-behavioral-biometrics.html
案例三:鯨魚的聲學檢測
在這個例子中,谷歌使用卷積神經網絡分析了聲音記錄並從中檢測出了座頭鯨。這對於座頭鯨的研究是有非常有用的,例如跟蹤個體鯨魚的運動、歌曲的屬性、鯨魚的數量等。在這裡,有意思的並不是他們研究的目的,而是如何預處理數據以方便使用卷積神經網絡。
將音頻數據轉換為圖像的方法是使用頻譜圖。頻譜圖是音頻數據基於頻率特徵的視覺表示。
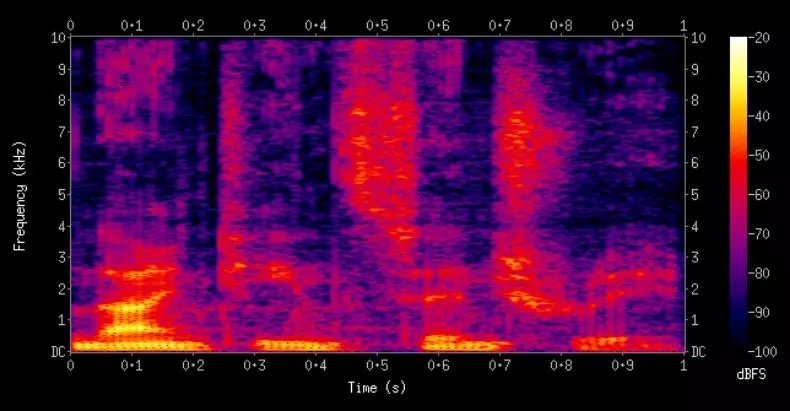
將聲學數據轉換為頻譜圖後,谷歌研究人員使用 ResNet-50 框架來訓練模型。他們訓練出的模型性能達到:
- 90% 精度:分類為鯨魚聲音的音頻片段中的 90% 是正確的;
- 90% 召回率:給定鯨魚聲音的錄音,有 90%的可能性被標記為鯨魚。
這個結果令人印象深刻,將很大程度上有助於鯨魚的研究。
讓我們將焦點從鯨魚切換到你處理音頻數據時可以做的事情。創建頻譜圖時,你可以選擇要使用的頻率,這取決於你的音頻數據類型。對於人類語音、座頭鯨歌曲、工業設備錄音等,你可能需要不同的頻率,因為不同的情況下重要信息往往包含在不同的頻段中,這時候就必須依靠你的領域知識來選擇參數了。例如如果你正在處理的是人類語音數據,那麼你首選的就應該是梅爾頻率倒譜係數了。
目前有一些很好的軟件來處理音頻。Librosa(https://librosa.github.io/librosa/)是一個免費的音頻分析 Python 庫,可以使用 CPU 來生成頻譜圖。如果你正在使用 TensorFlow 進行開發並希望在 GPU 上進行頻譜圖計算,那麼這也是可以的(https://www.tensorflow.org/api_guides/python/contrib.signal#Computing_spectrograms)。
想了解 Google 如何使用座頭鯨數據的詳細內容,可以參考 Google AI 的博客文章: https://ai.googleblog.com/2018/10/acoustic-detection-of-humpback-whales.html。
總而言之,本文中概述的一般方法遵循兩個步驟。首先找到一種將數據轉換為圖像的方法,然後使用一個預訓練的卷積網絡或自己從頭開始訓練一個卷積網絡。第一步比第二步更難,這需要你去創造性思考如何將你的數據轉換成圖像,希望我提供的示例對解決你的問題有所幫助。

Comments