

DeepMind聯合谷歌大腦、MIT等機構27位作者發表重磅論文,提出「圖網路」(Graph network),將端到端學習與歸納推理相結合,有望解決深度學習無法進行關係推理的問題。
作為行業的標杆,DeepMind的動向一直是AI業界關注的熱點。最近,這家世界最頂級的AI實驗室似乎是把他們的重點放在了探索「關係」上面,6月份以來,接連發布了好幾篇「帶關係」的論文,比如:
- 關係歸納偏置(Relational inductive bias for physical construction in humans and machines)
- 關係深度強化學習(Relational Deep Reinforcement Learning)
- 關係RNN(Relational Recurrent Neural Networks)
論文比較多,但如果說有哪篇論文最值得看,那麼一定選這篇——《關係歸納偏置、深度學習和圖網路》。

這篇文章聯合了DeepMind、谷歌大腦、MIT和愛丁堡大學的27名作者(其中22人來自DeepMind),用37頁的篇幅,對關係歸納偏置和圖網路(Graph network)進行了全面闡述。
DeepMind的研究科學家、大牛Oriol Vinyals頗為罕見的在Twitter上宣傳了這項工作(他自己也是其中一位作者),並表示這份綜述「pretty comprehensive」。

有很不少知名的AI學者也對這篇文章做了點評。
曾經在谷歌大腦實習,從事深度強化學習研究的Denny Britz說,他很高興看到有人將圖(Graph)的一階邏輯和概率推理結合到一起,這個領域或許會迎來複興。

晶元公司Graphcore的創始人Chris Gray評論說,如果這個方向繼續下去並真的取得成果,那麼將為AI開創一個比現如今的深度學習更加富有前景的基礎。

康納爾大學數學博士/MIT博士後Seth Stafford則認為,圖神經網路(Graph NNs)可能解決圖靈獎得主Judea Pearl指出的深度學習無法做因果推理的核心問題。
開闢一個比單獨的深度學習更富有前景的方向
那麼,這篇論文是關於什麼的呢?DeepMind的觀點和要點在這一段話里說得非常清楚:
這既是一篇意見書,也是一篇綜述,還是一種統一。我們認為,如果AI要實現人類一樣的能力,必須將組合泛化(combinatorial generalization)作為重中之重,而結構化的表示和計算是實現這一目標的關鍵。
正如生物學裡先天因素和後天因素是共同發揮作用的,我們認為「人工構造」(hand-engineering)和「端到端」學習也不是只能從中選擇其一,我們主張結合兩者的優點,從它們的互補優勢中受益。
在論文里,作者探討了如何在深度學習結構(比如全連接層、卷積層和遞歸層)中,使用關係歸納偏置(relational inductive biases),促進對實體、對關係,以及對組成它們的規則進行學習。
他們提出了一個新的AI模塊——圖網路(graph network),是對以前各種對圖進行操作的神經網路方法的推廣和擴展。圖網路具有強大的關係歸納偏置,為操縱結構化知識和生成結構化行為提供了一個直接的界面。
作者還討論了圖網路如何支持關係推理和組合泛化,為更複雜、可解釋和靈活的推理模式打下基礎。圖靈獎得主Judea Pearl:深度學習的因果推理之殤
2018年初,承接NIPS 2017有關「深度學習鍊金術」的辯論,深度學習又迎來了一位重要的批評者。
圖靈獎得主、貝葉斯網路之父Judea Pearl,在ArXiv發布了他的論文《機器學習理論障礙與因果革命七大火花》,論述當前機器學習理論局限,並給出來自因果推理的7大啟發。Pearl指出,當前的機器學習系統幾乎完全以統計學或盲模型的方式運行,不能作為強AI的基礎。他認為突破口在於「因果革命」,借鑒結構性的因果推理模型,能對自動化推理做出獨特貢獻。

在最近的一篇訪談中,Pearl更是直言,當前的深度學習不過只是「曲線擬合」(curve fitting)。「這聽起來像是褻瀆……但從數學的角度,無論你操縱數據的手段有多高明,從中讀出來多少信息,你做的仍舊只是擬合一條曲線罷了。」 DeepMind的提議:把傳統的貝葉斯因果網路和知識圖譜,與深度強化學習融合
如何解決這個問題?DeepMind認為,要從「圖網路」入手。
大數醫達創始人、CMU博士鄧侃為我們解釋了DeepMind這篇論文的研究背景。
鄧侃博士介紹,機器學習界有三個主要學派,符號主義(Symbolicism)、連接主義(Connectionism)、行為主義(Actionism)。
符號主義的起源,注重研究知識表達和邏輯推理。經過幾十年的研究,目前這一學派的主要成果,一個是貝葉斯因果網路,另一個是知識圖譜。
貝葉斯因果網路的旗手是 Judea Pearl 教授,2011年的圖靈獎獲得者。但是據說 2017年 NIPS 學術會議上,老爺子演講時,聽眾寥寥。2018年,老爺子出版了一本新書,「The Book of Why」,為因果網路辯護,同時批判深度學習缺乏嚴謹的邏輯推理過程。而知識圖譜主要由搜索引擎公司,包括谷歌、微軟、百度推動,目標是把搜索引擎,由關鍵詞匹配,推進到語義匹配。
連接主義的起源是仿生學,用數學模型來模仿神經元。Marvin Minsky 教授因為對神經元研究的推動,獲得了1969年圖靈獎。把大量神經元拼裝在一起,就形成了深度學習模型,深度學習的旗手是 Geoffrey Hinton 教授。深度學習模型最遭人詬病的缺陷,是不可解釋。
行為主義把控制論引入機器學習,最著名的成果是強化學習。強化學習的旗手是 Richard Sutton 教授。近年來Google DeepMind 研究員,把傳統強化學習,與深度學習融合,實現了 AlphaGo,戰勝當今世界所有人類圍棋高手。
DeepMind 前天發表的這篇論文,提議把傳統的貝葉斯因果網路和知識圖譜,與深度強化學習融合,並梳理了與這個主題相關的研究進展。DeepMind提出的「圖網路」究竟是什麼
在這裡,有必要對說了這麼多的「圖網路」做一個比較詳細的介紹。當然,你也可以跳過這一節,直接看後面的解讀。
在《關係歸納偏置、深度學習和圖網路》這篇論文里,作者詳細解釋了他們的「圖網路」。圖網路(GN)的框架定義了一類用於圖形結構表示的關係推理的函數。GN 框架概括並擴展了各種的圖神經網路、MPNN、以及 NLNN 方法,並支持從簡單的構建塊(building blocks)來構建複雜的結構。
GN 框架的主要計算單元是 GN block,即 「graph-to-graph」 模塊,它將 graph 作為輸入,對結構執行計算,並返回 graph 作為輸出。如下面的 Box 3 所描述的,entity 由 graph 的節點(nodes),邊的關係(relations)以及全局屬性(global attributes)表示。
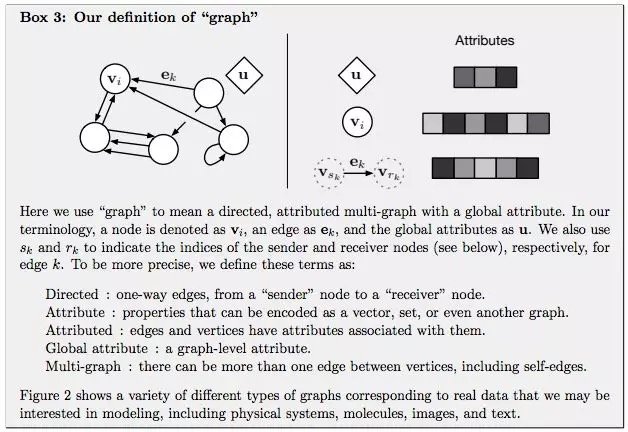
論文作者用 「graph」 表示具有全局屬性的有向(directed)、有屬性(attributed)的 multi-graph。一個節點(node)表示為Vi,一條邊(edge)表示為ek,全局屬性(global attributes)表示為u。sk和rk表示發送方(sender)和接收方(receiver)節點的指標(indices)。具體如下:
- Directed:單向,從 「sender」 節點指向 「receiver」 節點。
- Attribute:屬性,可以編碼為矢量(vector),集合(set),甚至另一個圖(graph)
- Attributed:邊和頂點具有與它們相關的屬性
- Global attribute:graph-level 的屬性
- Multi-graph:頂點之間有多個邊
GN 框架的 block 的組織強調可定製性,並綜合表示所需關係歸納偏置(inductive biases)的新架構。
用一個例子來更具體地解釋 GN。考慮在任意引力場中預測一組橡膠球的運動,它們不是相互碰撞,而是有一個或多個彈簧將它們與其他球(或全部球)連接起來。我們將在下文的定義中引用這個運行示例,以說明圖形表示和對其進行的計算。
「graph」 的定義
在我們的 GN 框架中,一個 graph 被定義為一個 3 元組的G=(u,V,E)。
u 表示一個全局屬性;例如,u 可能代表重力場。
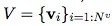
是節點集合(基數是Nv),其中每個Vi表示節點的屬性。例如,V 可能表示每個球,帶有位置、速度和質量這些屬性。
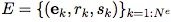
是邊(基數是Ne)的集合,其中每個ek表示邊的屬性,rk是接收節點的 index,sk是發送節點的 index。例如,E 可以表示不同球之間存在的彈簧,以及它們對應的彈簧常數。
演算法 1:一個完整的 GN block 的計算步驟

GN block 的內部結構
一個 GN block 包含三個 「update」 函數,以及三個 「aggregation」 函數:
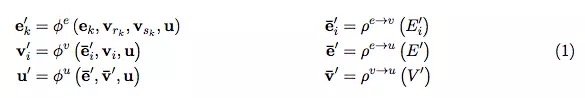
其中:
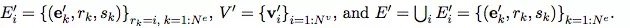

要把知識圖譜和深度學習相結合,鄧侃博士認為有幾大難點。
1. 點向量:
知識圖譜由點和邊構成,點(node)用來表徵實體(entity),實體又包含屬性(attribute)和屬性的值(value)。傳統知識圖譜中的實體,通常由概念符號構成,譬如自然語言的辭彙。
傳統知識圖譜中的邊,連接兩個單點,也就是兩個實體,邊表達的是關係,關係的強弱,由權重表達,傳統知識圖譜的邊的權重,通常是常數。
如果想把傳統知識圖譜與深度學習相融合,首先要做的是實現點的可微分化。用數值化的詞向量來替代自然語言的辭彙,是實現點的可微分化的有效方法,通常的做法是用語言模型來分析大量的文本,給每個辭彙找到最貼合上下文語義的詞向量。但在圖譜中,傳統的詞向量的生成演算法,不十分奏效,需要改造。
2. 超點:
前文說到,傳統知識圖譜中的邊,連接兩個單點,表達兩個單點之間的關係。這個假定製約了圖譜的表達能力,因為在很多場景下,多個單點組合在一起,才與其它單點或者單點組合,存在關係。我們把單點組合,稱之為超點(hyper-node)。
問題是哪些單點組合在一起構成超點?人為的先驗指定,當然是一個辦法。從大量訓練數據中,通過 dropout 或者 regulation 演算法,自動學習出超點的構成,也是一個思路。
3. 超邊:
傳統的知識圖譜中的邊,表達了點與點之間的關係,關係的強弱由權重表達,通常權重是個常數。但在很多場景下,權重並非是常數。隨著點的取值不同,邊的權重也發生變化,而且很可能是非線性變化。
用非線性函數來表達圖譜的邊,稱為超邊(hyper-edge)。
深度學習模型可以用於模擬非線性函數。所以,知識圖譜中每條邊都是一個深度學習模型。模型的輸入是若干個單點組成的超點,模型的輸出是另一個超點。如果把每個深度學習模型,視為一棵樹,根是輸入,葉子是輸出。那麼鳥瞰整個知識圖譜,實際上是深度學習模型的森林。
4. 路徑:
訓練知識圖譜,包括訓練點向量,超點、和超邊的時候,一條訓練數據往往是在圖譜中行走的一條路徑,通過擬合海量的路徑,獲得最貼切的點向量、超點和超邊。
用擬合路徑來訓練圖譜,存在的一個問題是,訓練過程與過程結束後的評價,兩者的脫節。打個比方,給你若干篇文章的提綱,以及相應的範文,讓你學習如何寫作文。擬合的過程,強調逐字逐句的模仿。但是評價文章的好壞,重點並不在於字句的亦步亦趨,而在於通篇文章的順暢。
如何解決訓練過程與最終評價的脫節?很有潛力的辦法,是用強化學習。強化學習的精髓,在於把最終的評價,通過回溯和折現的方法,給路徑過程中每一個中間狀態,評估它的潛力。
但是強化學習面臨的困難,在於中間狀態的數量不可太多。當狀態數量太多時,強化學習的訓練過程,無法收斂。解決收斂問題的辦法,是用一個深度學習模型,來估算所有狀態的潛力值。換句話說,不需要估算所有狀態的潛力值,而只需要訓練一個模型的有限參數。
DeepMind 前天發表的這篇文章,提議把深度強化學習與知識圖譜等相融合,並梳理了大量的相關研究。但是,論文並沒有明確說明 DeepMind 偏向於哪一種具體方案。
或許,針對不同應用場景會有不同方案,並沒有通用的最佳方案。圖譜深度學習是下一個AI演算法的熱點?
許多重要的現實世界數據集都是以圖或網路的形式出現,比如社交網路、知識圖譜,萬維網等等。 目前,已有越來越多的研究者開始關注神經網路模型對這種結構化數據集的處理。
結合DeepMind、谷歌大腦等發表的一系列的關於圖深度學習的論文,是否預示「圖深度學習」是下一個AI演算法熱點?
總之,先從這篇論文看起吧。
地址:https://arxiv.org/pdf/1806.01261.pdf
參考資料
本文轉自公眾號 新智元,原文地址

Comments