

生成性對抗網絡(GANs)已經接管了公眾的想象力 – 通過AI產生的名人來吸引流行文化,並創造出在高級藝術品拍賣中以數千美元銷售的藝術品。
在這篇文章中,我們將探討:
- 關於GAN的簡要介紹
- 理解和評估GAN
- 運行自己的GAN
有足夠的資源來追趕GAN,因此我們對本文的重點是了解如何評估GAN。我們還將引導您運行自己的GAN以生成MNIST等手寫數字。
關於GAN的簡要介紹
自2014年Ian Goodfellow的“ Generative Adversarial Networks ”論文成立以來,GAN的進展已經爆發並導致產出越來越現實。

就在三年前,你可以找到Ian Goodfellow對這個Reddit主題的回復給用戶詢問你是否可以使用GAN作為文本:
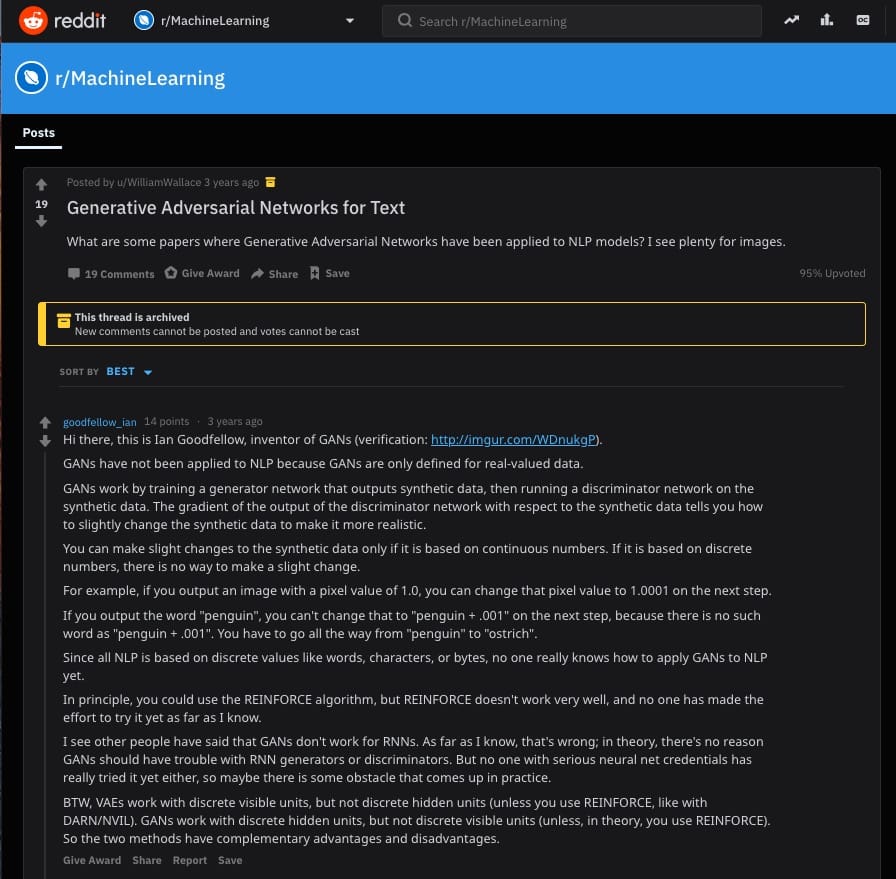
“GAN尚未應用於NLP,因為GAN僅針對實值數據進行了定義。GAN通過訓練輸出合成數據的發電機網絡,然後在合成數據上運行鑒別器網絡來工作。鑒別器網絡的輸出相對於合成數據的梯度告訴您如何稍微改變合成數據以使其更加真實。僅當合成數據基於連續數字時,才能對其進行細微更改。如果它基於離散數字,則無法進行輕微更改。例如,如果輸出像素值為1.0的圖像,則可以在下一步將該像素值更改為1.0001。如果輸出單詞“penguin”,則不能在下一步將其更改為“penguin + .001”,因為沒有“penguin + .001”這樣的單詞。你必須從“企鵝”到“鴕鳥”一路走。由於所有NLP都基於離散值,如單詞,字符或字節,因此沒有人真正知道如何將GAN應用於NLP。“
現在GAN用於創建各種內容,包括圖像,視頻,音頻和(是)文本。這些輸出可用作訓練其他模型的合成數據,或僅用於產生有趣的側面項目,例如thispersondoesnotexist.com,thisairbnbdoesnotexist.com/,並且此機器學習媒體帖子不存在。😎
GAN背後
GAN由兩個神經網絡組成 – 一個從頭開始合成新樣本的生成器,以及一個將訓練樣本與來自生成器的這些生成樣本進行比較的鑒別器。鑒別器的目標是區分“真實”和“假”輸入(即,如果樣本來自模型分布或真實分布,則進行分類)。如我們所述,這些樣本可以是圖像,視頻,音頻片段和文本。
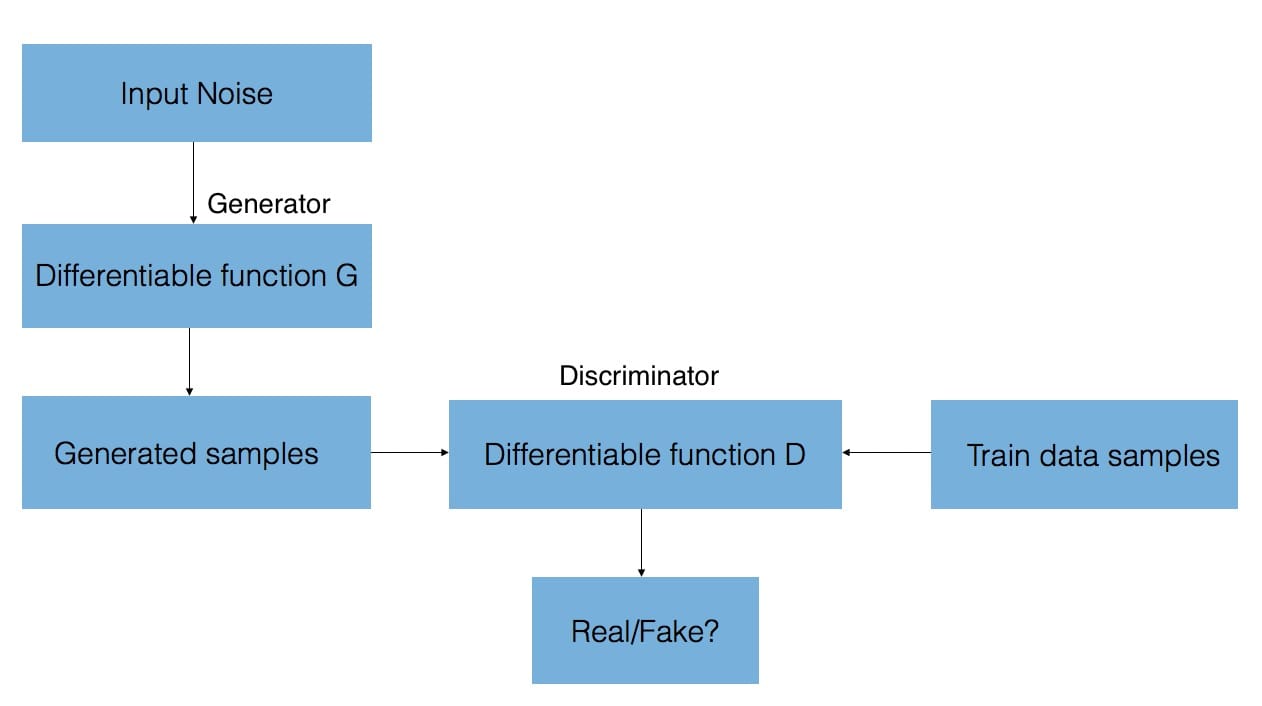
為了合成這些新樣本,給予發生器隨機噪聲並嘗試從所學習的訓練數據分布生成逼真的圖像。
鑒別器網絡(卷積神經網絡)的輸出相對於合成數據的梯度通知如何稍微改變合成數據以使其更加真實。最終,生成器收斂於再現實際數據分布的參數,並且鑒別器無法檢測到差異。
您可以通過GAN Lab查看和使用這些融合數據分布:GAN Lab:在您的瀏覽器中使用生成式對抗網絡!
GAN Lab由Minsuk Kahng,Nikhil Thorat,Polo Chau,FernandaViégas和Martin Wattenberg創建,這是…poloclub.github.io
以下是關於GAN的最佳指南:
- 斯坦福CS231第13講 – 生成模型
- 基於風格的GAN
- 了解生成性對抗網絡
- 生成對抗網絡簡介
- Lillian Weng:從Gan到WGAN
- 首先潛入先進的GAN:探索自我關注和頻譜規範
- Guim Perarnau:神奇的GAN以及在哪裡找到它們(第一和第二部分)
理解和評估GAN
量化GAN的進度可以感覺非常主觀 – “這個生成的面部是否看起來足夠逼真?”,“這些生成的圖像是否足夠多樣化?” - 並且GAN可能感覺像黑盒子,其中不清楚模型的哪些組件影響學習或結果質量。
為此,麻省理工學院計算機科學與人工智能(CSAIL)實驗室的一個小組最近發表了一篇論文“ GAN解剖:可視化和理解生成性對抗網絡 ”,該論文介紹了一種可視化GAN以及GAN單元如何與對象相關的方法在圖像以及對象之間的關係。

使用基於分割的網絡剖析方法,本文的框架允許我們剖析和可視化生成器神經網絡的內部工作。這通過尋找一組GAN單元(稱為神經元)與輸出圖像中的概念(例如樹,天空,雲等)之間的協議來實現。因此,我們能夠識別出對某些物體(如建築物或雲)負責的神經元。
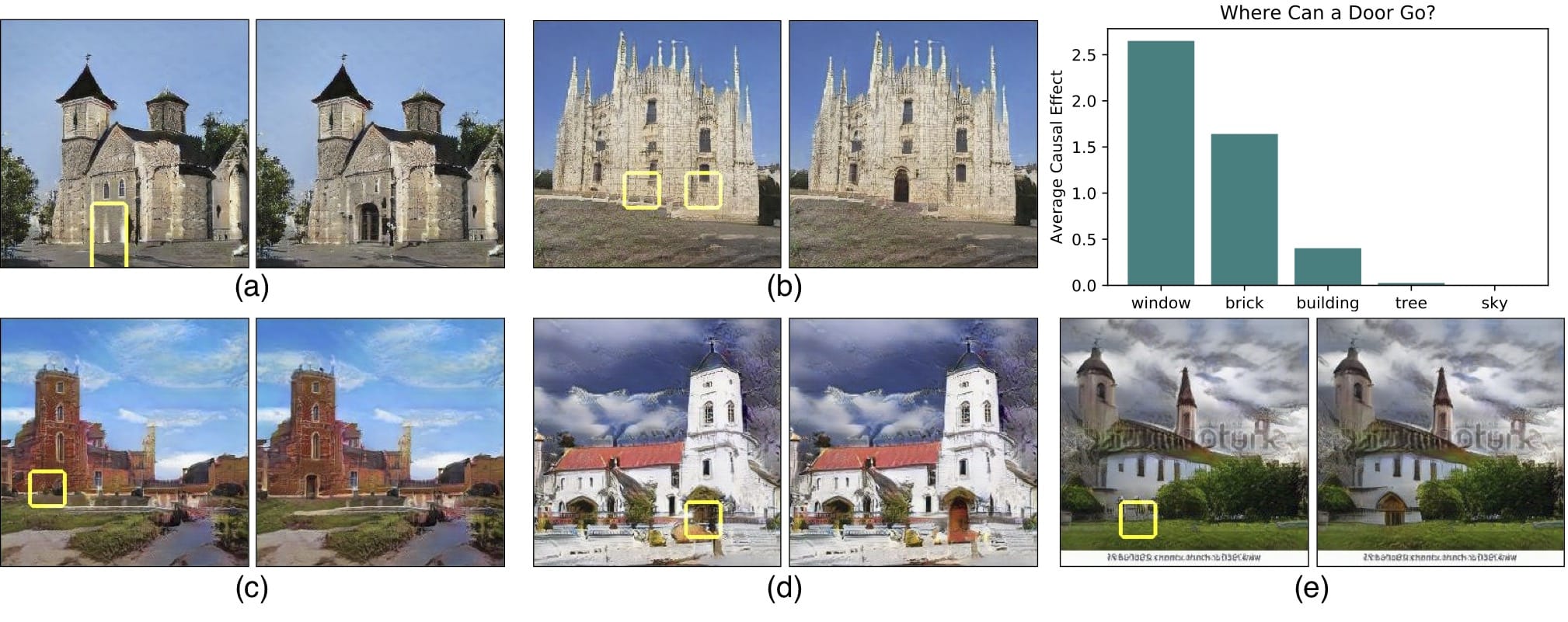
將這種粒度級別放入神經元中允許通過強制激活和去激活(消融)這些對象的相應單元來編輯現有圖像(例如,添加或移除圖像中所示的樹)。
但是,目前尚不清楚網絡是否能夠推斷場景中的對象,或者它是否只是記住這些對象。接近這個問題的答案的一種方法是試圖以不切實際的方式扭曲圖像。也許MIT CSAIL的GAN Paint互動網絡演示中最令人印象深刻的部分是該模型似乎能夠將這些編輯限制為“真實感”的變化。如果你試圖將草坪放在天空上,這就是發生的事情:
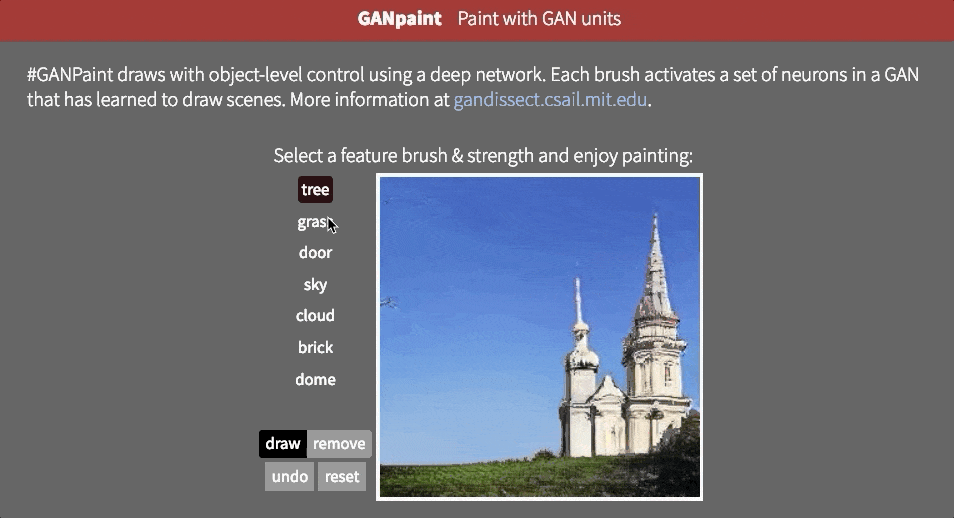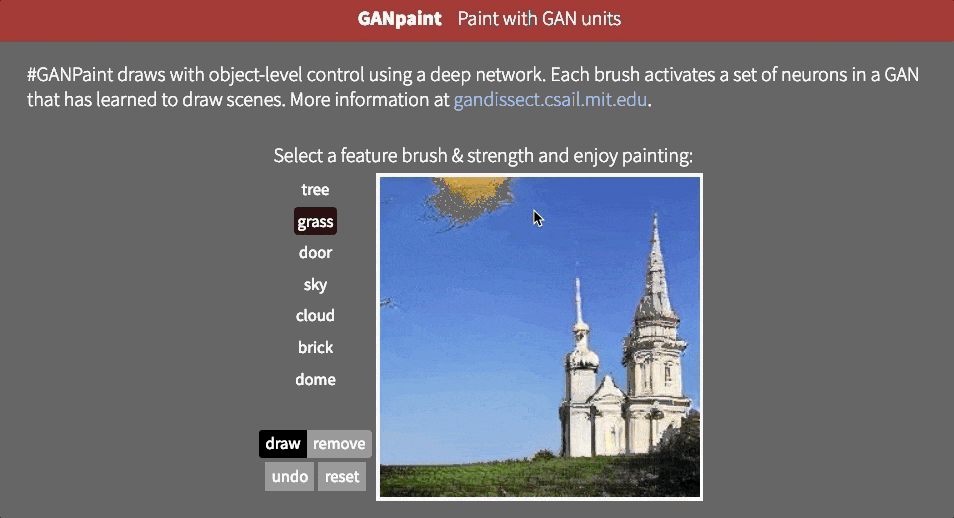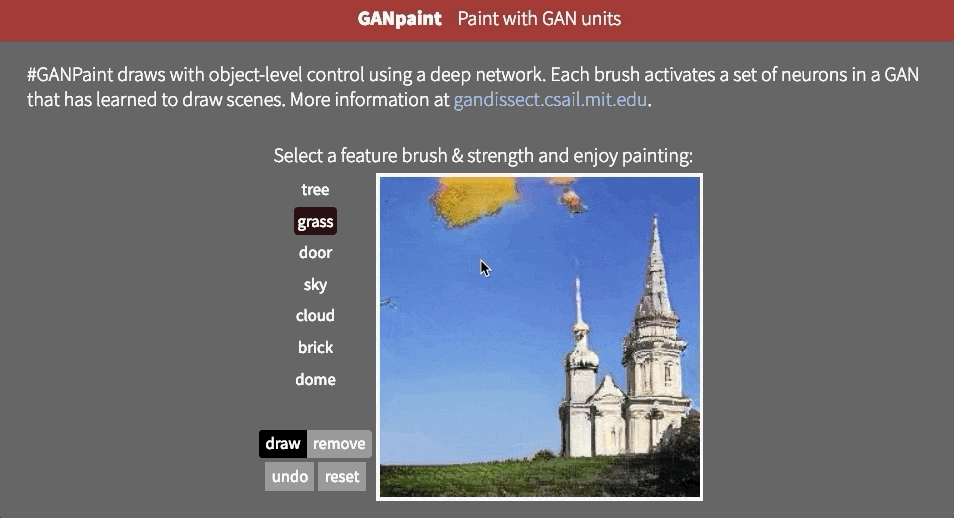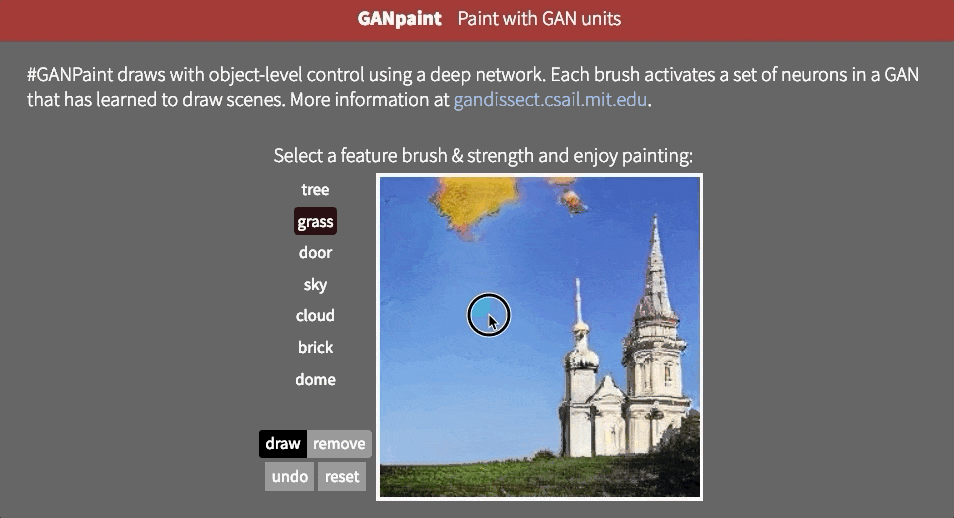
即使我們激活相應的神經元,看起來GAN已經抑制了後續層中的信號。
可視化GAN的另一種有趣方式是進行潛在空間插值(記住,GAN通過從學習的潛在空間中採樣來生成新實例)。這可以是查看生成的樣本之間的過渡平滑程度的有用方法。

這些可視化可以幫助我們理解GAN的內部表示,但是找到可量化的方法來理解GAN進度和輸出質量仍然是一個活躍的研究領域。
圖像質量和多樣性的兩個常用評估指標是:初始分數和Fréchet初始距離(FID)。Shane Barratt和Rishi Sharma 在前者的主要缺點上發表了他們的論文“ 關於初始分數的注釋”,大多數從業者已從初始分數轉為FID 。
初始分數
在Salimans等人發明。2016年“ 用於訓練GAN的改進技術 ”中,初始分數基於一種啟發式方法,即當通過預先訓練的網絡(例如ImageNet上的Inception)傳遞時,現實樣本應該能夠被分類。從技術上講,這意味着樣本應具有低熵softmax預測向量。
除了高可預測性(低熵)之外,初始分數還基於所生成的樣本的多樣性來評估GAN(例如,生成的樣本的分布的高方差或熵)。這意味着不應該有任何支配階級。
如果這兩個特徵都得到滿足,那麼應該有一個很大的初始分數。結合這兩個標準的方法是評估樣本的條件標籤分布與所有樣本的邊際分布之間的Kullback-Leibler(KL)差異。
Fréchet起始距離
由Heusel等人介紹。2017年,FID通過測量生成的圖像分布與真實分布之間的距離來估計真實感。FID將一組生成的樣本嵌入由特定初始網絡層給出的特徵空間中。該嵌入層被視為連續的多元高斯,然後估計生成的數據和實際數據的均值和協方差。然後使用這兩個高斯之間的Fréchet距離(aka Wasserstein-2距離)來量化生成的樣本的質量。較低的FID對應於更相似的實際和生成的樣本。
一個重要的注意事項是,FID需要一個合適的樣本量才能產生良好的結果(建議的大小= 50k樣本)。如果您使用的樣本太少,最終會高估您的實際FID,並且估算值會有很大差異。對於成立之初成績和分數FID如何跨越不同的文件進行比較,看尼爾吉恩的帖子
在這裡。
想看更多?
Aji Borji的論文“ GAN評估措施的優點和缺點 ”包括一個優秀的表格,更全面地涵蓋了GAN評估指標:
有趣的是,其他研究人員通過使用特定領域的評估指標採取不同的方法。對於文本GAN,Guy Tevet和他的團隊提出使用傳統的基於概率的語言模型度量來評估GAN在他們的論文“ 評估文本GAN作為語言模型 ”中生成的文本的分布。
在’ 我的GAN有多好?‘,Konstantin Shmelkov及其團隊使用基於圖像分類,GAN-train和GAN-test的兩種方法,分別近似於GAN的召回(多樣性)和精確度(圖像質量)。您可以在Google Brain研究論文“ GANS創建相同 ”中看到這些評估指標,他們使用三角形數據集來衡量不同GAN模型的精確度和召回率。

運行自己的GAN
為了說明GAN,我們將調整Wouter Bulten的這個優秀教程,該教程使用Keras和MNIST數據集來生成書寫數字。
在這裡查看完整的教程筆記本。
該GAN模型將MNIST訓練數據和隨機噪聲作為輸入(具體地,噪聲的隨機向量)來生成:
- 圖像(在這種情況下,手寫數字的圖像)。最終,這些生成的圖像將類似於MNIST數據集的數據分布。
- 鑒別器對生成的圖像的預測
所述發電機和鑒別模型一起形成對抗模型-在這個例子中,以及如果對抗模型用作輸出所生成的圖像分類為實際用於所有輸入的發電機將執行。
跟蹤模型的進度
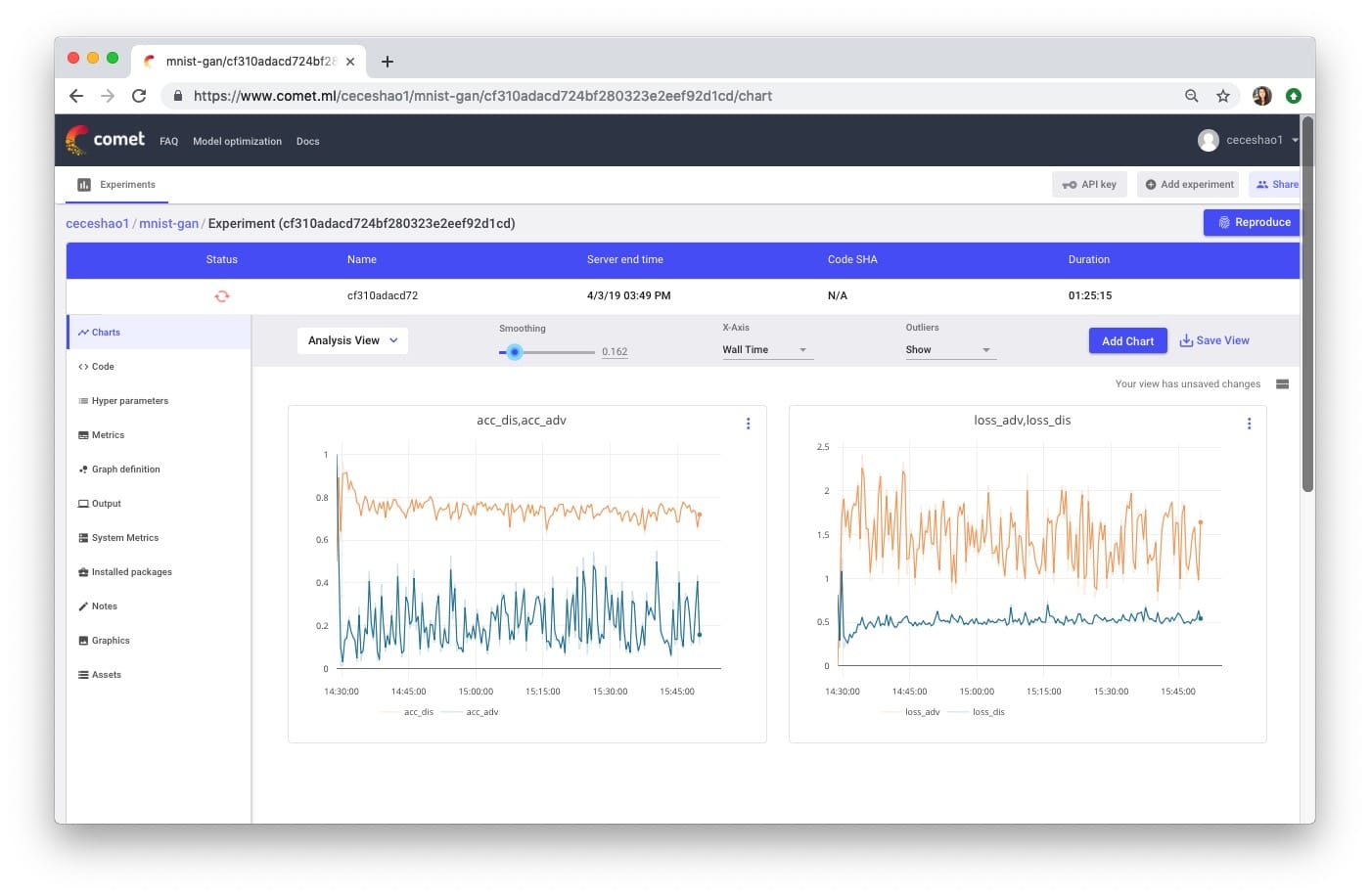
我們可以使用Comet.ml跟蹤Generator和Discriminator模型的訓練進度。
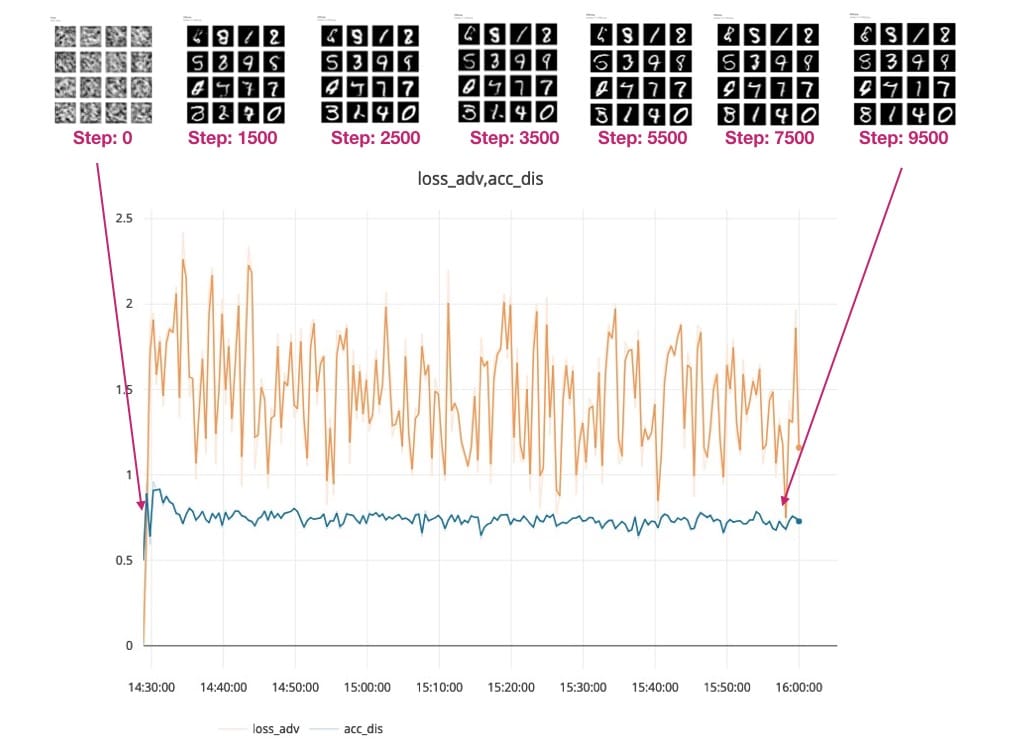
我們正在繪製鑒別器和對抗模型的準確性和損失 – 這裡要跟蹤的最重要指標是:
- 鑒別者的損失(見右圖中的藍線) – dis_loss
- 對抗模型的準確性(見左圖中的藍線) - acc_adv
請在此處查看此實驗的培訓進度。
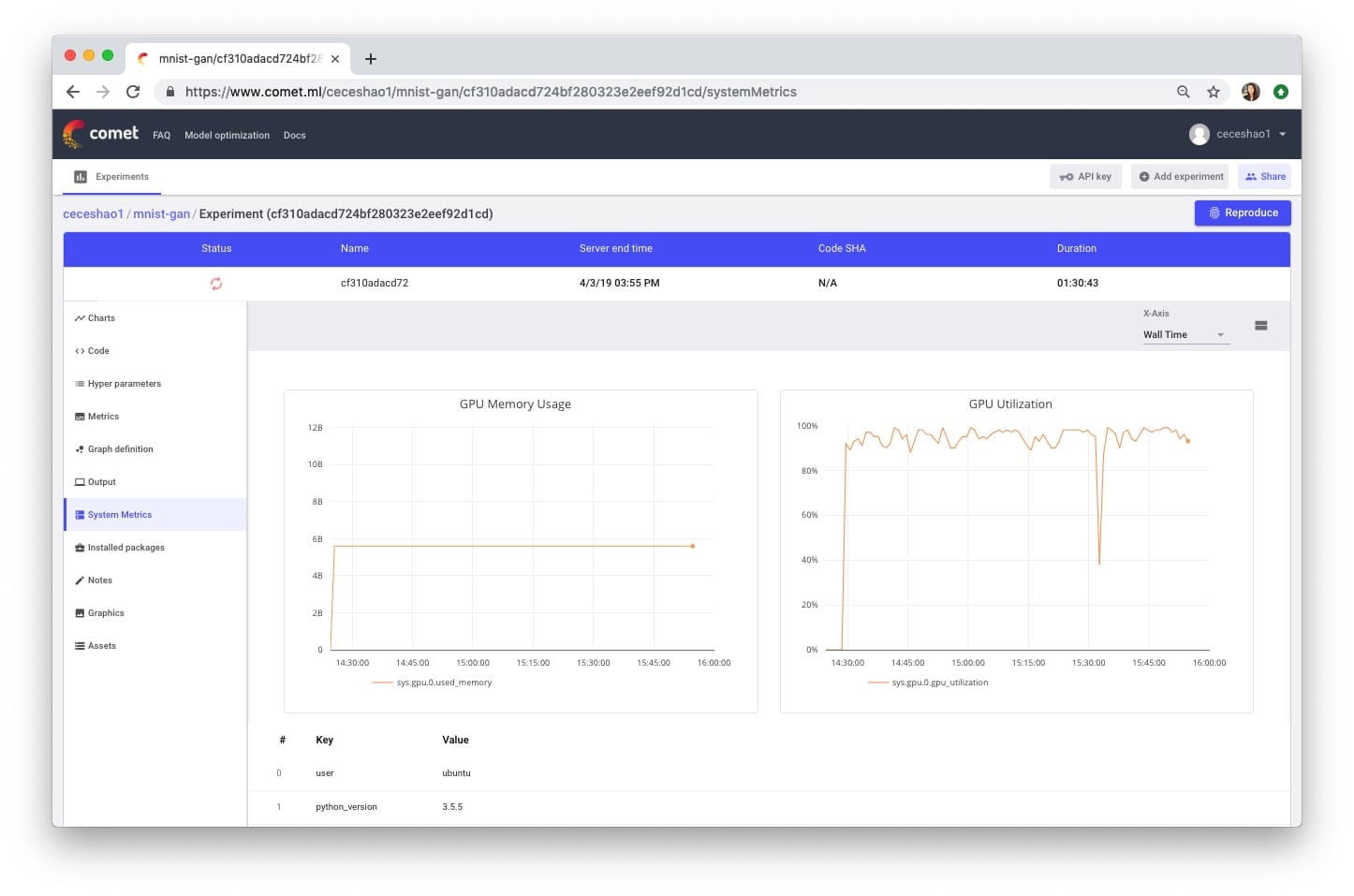
您還需要確認您的培訓過程實際上是否正在使用GPU,您可以在Comet System Metrics選項卡中查看。
您注意到我們的for循環訓練包括從測試向量報告圖像的代碼:
if i % 500 == 0:
# Visualize the performance of the generator by producing images from the test vector
images = net_generator.predict(vis_noise)
# Map back to original range
#images = (images + 1 ) * 0.5
plt.figure(figsize=(10,10))
for im in range(images.shape[0]):
plt.subplot(4, 4, im+1)
image = images[im, :, :, :]
image = np.reshape(image, [28, 28])
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.tight_layout()
# plt.savefig('/home/ubuntu/cecelia/deeplearning-resources/output/mnist-normal/{}.png'.format(i))
plt.savefig(r'output/mnist-normal/{}.png'.format(i))
experiment.log_image(r'output/mnist-normal/{}.png'.format(i))
plt.close('all')我們想要每隔幾步報告生成的輸出的部分原因是,我們可以直觀地分析我們的生成器和鑒別器模型在生成逼真的手寫數字方面的表現,並正確地將生成的數字分類為“真實”或“假”,分別。
我們來看看這些生成的輸出!在此Comet實驗中查看您自己生成的輸出
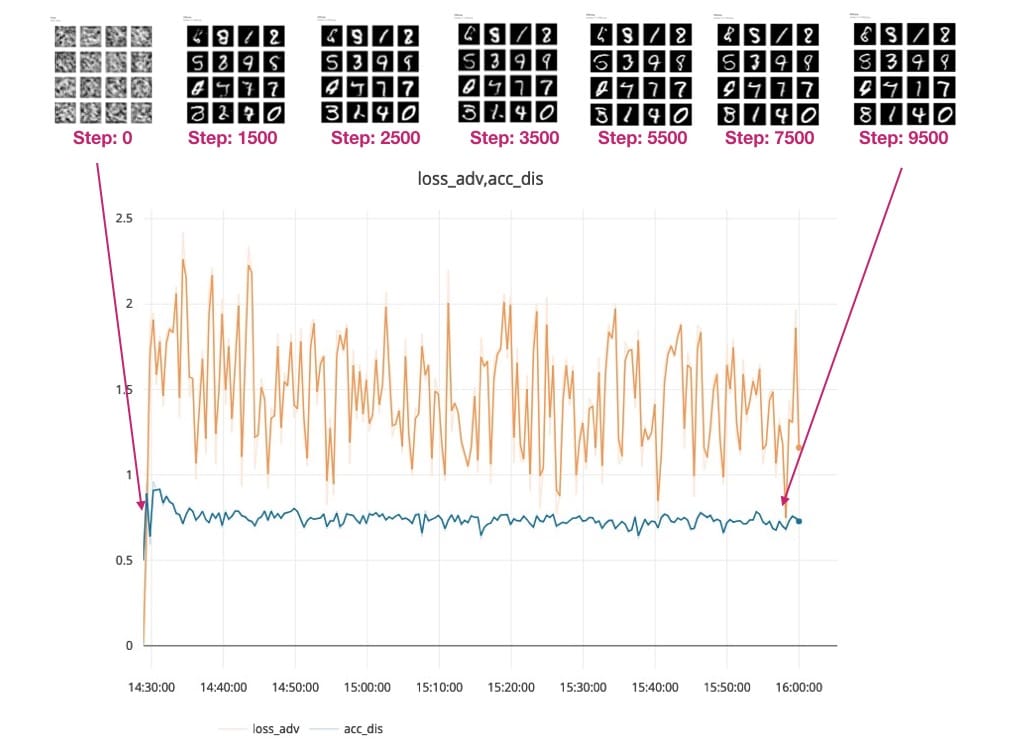
您可以看到Generator模型如何從這個模糊的灰色輸出(參見下面的0.png)開始,它看起來並不像我們期望的手寫數字。

隨着培訓的進行和我們模型的損失下降,生成的數字變得更加清晰。查看生成的輸出:
步驟500:

步驟1000:

步驟1500:

最後在步驟10,000 - 您可以在下面的紅色框中看到GAN生成數字的一些樣本

一旦我們的GAN模型完成訓練,我們甚至可以在Comet的圖形選項卡中查看我們報告的輸出作為電影(只需按下播放按鈕!)。

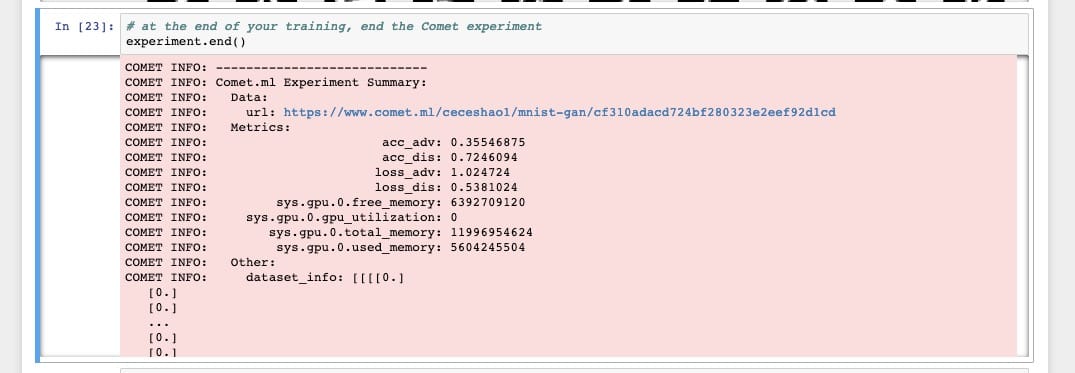
要完成實驗,請確保運行experiment.end()以查看有關模型和GPU使用情況的一些摘要統計信息。
迭代您的模型
我們可以更長時間地訓練模型以查看它如何影響性能,但讓我們嘗試使用幾個不同的參數進行迭代。
我們使用的一些參數是:
- 鑒別器的優化器
- 學習率
- 輟學概率
- 批量大小
從Wouter的原始博客文章中,他提到了自己在測試參數方面的努力:
我已經測試了兩者
SGD,RMSprop並且Adam對於鑒別器的優化器但是RMSprop表現最好。RMSprop使用低學習率並且我將值限制在-1和1之間。學習率的小衰減可以幫助穩定
我們將嘗試將鑒別器的丟失概率從0.4增加到0.5,並增加鑒別器的學習率(從0.008到0.0009)和生成器的學習率(從0.0004到0.0006)。很容易看出這些變化如何失控並難以追蹤……🤯
要創建不同的實驗,只需再次運行實驗定義單元格,Comet會為您的新實驗發給您一個新的網址!跟蹤您的實驗很好,因此您可以比較差異:
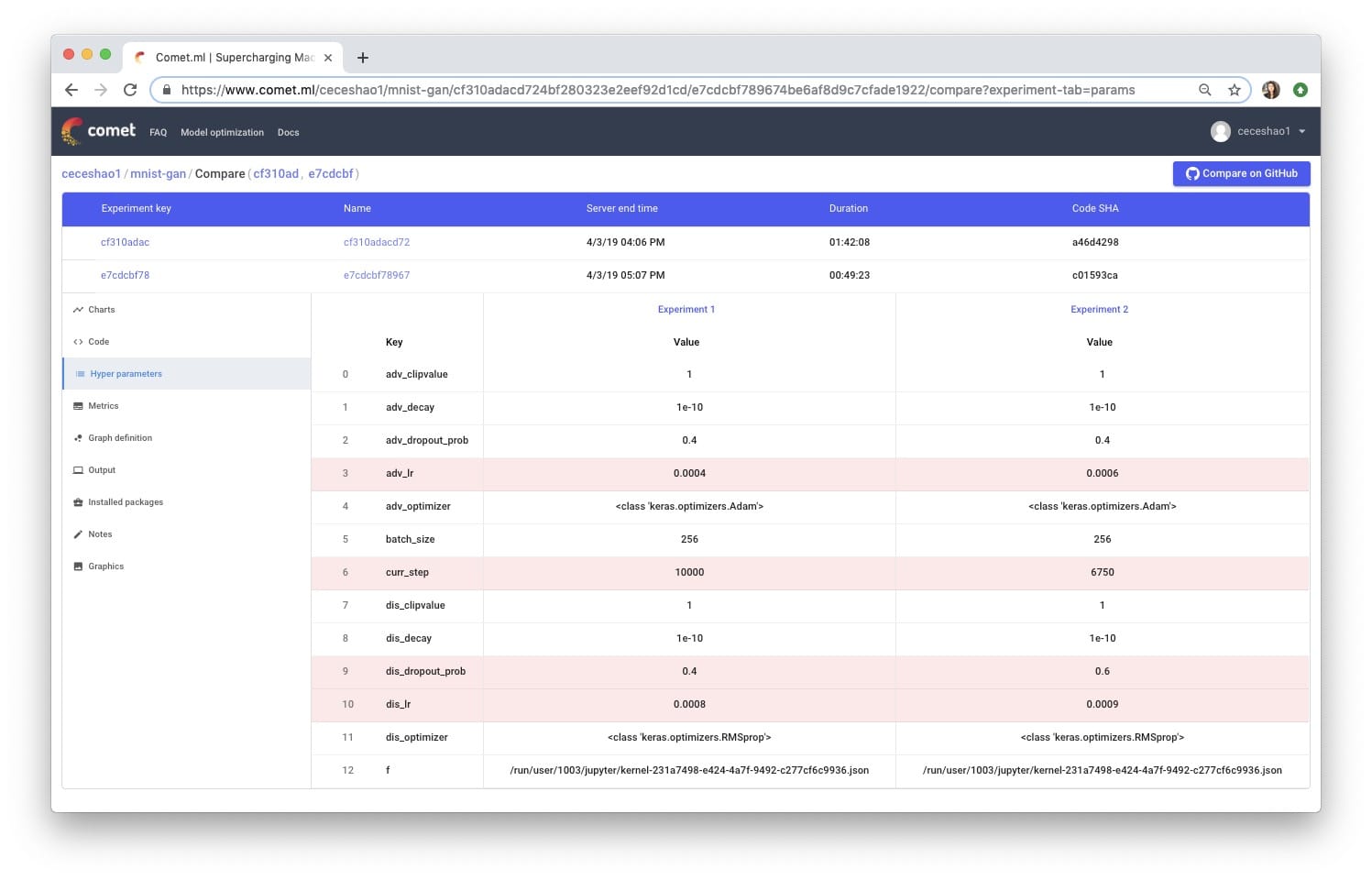
不幸的是,我們的調整沒有改善模型的性能!事實上,它產生了一些時髦的輸出:

這就是本教程的內容!如果您喜歡這篇文章,請隨時與可能覺得有用的朋友分享😎
本文轉自towardsdatascience,原文地址

Comments