

本文轉載自公眾號 讀芯術,原文地址
現實世界中的數據可能十分混亂複雜,不論它是相關的SQL數據庫、Excel文件或是其它任何數據源。儘管這些數據通常都是表格的結構,即每一行(樣本)相對於每一列(特徵)都有其對應的值,但是這些數據可能很難理解和處理。為了讓機器學習模型能夠更輕鬆地讀取數據,我們可以運用特徵工程來提升模型的性能。
什麼是特徵工程?

特徵工程是指將給定的數據轉換成為更易解析的形式的過程。本文中,我們希望能使機器學習模型更加透明,同時也能夠生成一些特徵,讓沒有相關背景知識的人能夠更好的理解提供給他們的可視化數據內容。然而,機器學習模型中透明的概念是很複雜的,因為針對不同種類的數據,不同的模型需要使用不同的方法。
示例:坐標
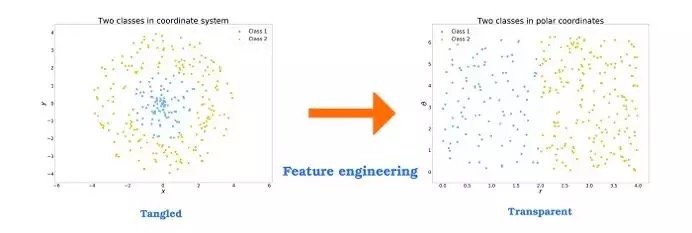
為了理解特徵工程的概念,我們可以舉一個簡單的例子。在下面的圖中,我們能夠看見兩種點。想象一下,現在有一座靠近這些點的倉庫,它只能為一些距離有限的客戶提供服務。從人類的角度來看,很容易就能理解我們需要考慮距離倉庫有限半徑內的點。這就需要兩種已知特徵的組合。
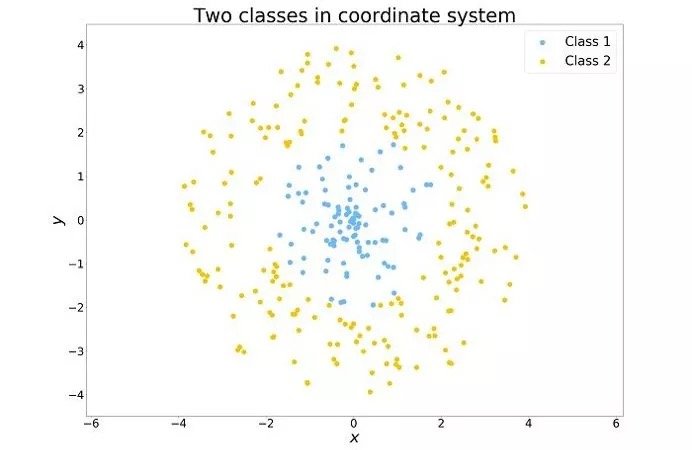
但是這對算法來說並不是顯而易見的。例如,基於決策樹(decision tree)的算法一次只會考慮一個特徵,並將數據集分為兩個部分,其中一個的特徵值高於任意閾值,另一個低於閾值。如上所述劃分空間需要大量地進行這種拆分。
坐標轉換
但是,我們可以進行一個高中學過的簡單坐標轉化。也就是從所謂的笛卡爾坐標系(x,y)轉換為極坐標系(r,0)。這裡我們使用如下轉換:
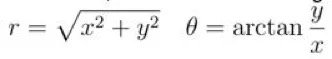
現在,任何算法都更容易對數據進行分析。將數據集按照r軸進行拆分,閾值設為r split=2。顯然這個例子並沒有什麼價值,現實中的數據很少會如此簡單,但是它展示了適當的特徵工程的潛力。

連續數據
連續數據是最常見的數據類型。它有可能包含給定範圍中的任意值。比如,它可以是產品的價格、工業生產過程中的溫度,或是地圖中對象的坐標。這裡主要通過領域數據來生成特徵。例如,你可以用售價減去進價得到利潤,或者可以計算地圖上兩地之間的距離。新的可生成特徵只受可用特徵和已知的數學運算的限制。
分類特徵
第二種最常見的數據類型是分類特徵,指能從一組有限的值中獲取值的特徵。通常該特徵只能有一個單一的值。還有另一種情況,但是在這種情況下,這種特徵常常被拆分為一組特徵。例如依據ISO/IEC 5218標準,性別可被分為下列四種值之一:未知、男性、女性和不適用。
編碼和獨熱(one-hots)
這種數據的問題在於算法並不是設計用來處理文本數據的。處理這個問題的標準變通方法是分類編碼。引入一個整數來代表每一個類別。例如,之前提到的性別的標準分類編碼分別為0、1、2和9。但是有時候為了可視化或模型效率,可以使用不同的編碼。我們可以用數個布爾特徵來代替含有多個層級的單一特徵,這些布爾特徵中只有一個能夠取True值。這叫做獨熱編碼(one-hot encoding),尤其流行於神經網絡。
缺失值
在現實世界中,有時候無法獲取一些數據,或者該數據在處理過程中發生了丟失。因此,數據中經常會含有缺失值。
處理這些值是單獨的一門藝術。這部分數據處理被稱為數據清洗,且通常被認為是一個單獨的步驟。然而在創建一些新的特徵時,需要牢記缺失值有可能隱藏在不同的名字和值背後。
一些編程語言和庫中含有特殊的對象與缺失值對應。通常它由“NaN”表示-並不是數字,而是用任意的可用值代替。例如,在一列正整數中,缺失值可以被編碼為“-1”。但是如果不預先對它的值進行分析,在計算該特徵的平均值時就會遭遇不便。其它時候,缺失值可以用“0”代替,這樣就能夠輕鬆地進行求和,但是卻無法生成一個需要除操作的新特徵。
另一種更常見的選擇是用當前值的平均值或中位數來填補缺失值。但是同樣,再次計算平均值時會得到不同的結果,所以根據真實平均值和錯誤平均值生成的新特徵之間會有明顯差異。這些例子都顯示出一個不變的事實,理解你的數據!這在進行特徵工程時也很重要。
這裡有缺失!
一個常見的方法是引入一個布朗特徵,指示出給定樣本中的給定特徵是否含有缺失值。若有缺失則布朗特徵會顯示為True,若一切正常則顯示False。它讓機器學習模型能夠判斷是否應當將給定值視為可信的,或是否應當另行處理。
歸一化
另一個常見的特徵工程方法是將數據置入一個給定的區間。為什麼要這麼做呢?第一個原因很簡單,即對有限範圍內的數字進行運算會避免一些數值誤差,同時限制所需的計算性能。第二個原因是一些機器學習算法能夠更好的處理歸一化的數據。數據歸一化的方法有多種。
標準歸一化
在自然和人類社會中,許多事物都服從於正太(高斯)分布。這就是為什麼會向分布中引入歸一特徵。它由如下等式表示:

這裡X表示新的特徵,它等於舊特徵的每個樣本減去舊特徵的平均值後再除以標準偏差。標準偏差表示特徵值的離散程度。這樣,X的取值範圍會在[-1,1]的區間內。
特徵縮放
另一種歸一化是用特徵值減去最小值Xmin,再除以它的取值範圍Xmax – Xmin,得到入下表達式:
這種歸一化會將給定的特徵歸入[0,1]的區間內。
正確的模型歸一化
正如之前提到的,不同的模型需要不同的歸一化來實現高效運行。舉個例子,在k-近鄰的案例中,特定的特徵範圍表示權重。值越大特徵就越重要。在神經網絡的案例中,歸一化對於最終運行結果本身來說並不重要,但是它能夠加快訓練速度。另一方面,基於決策樹的算法並不會從歸一化中獲益,也不會受到歸一化的不良影響。
問題的正確歸一化
有時正確的歸一化並不源自一般的數據或計算考量,而是來自領域知識。例如,在根據溫度對一些物理系統進行建模時,引入開氏溫標無疑是大有裨益的,它能夠使數據間的關係簡單化。在數據科學中,領域知識總是十分有用的。
日期與時間
下一種常見的數據類型集合是所有不同格式的日期和時間。
這裡的問題在於日期時間的格式多種多樣。例如,數據可能是帶格式的字符串,或是存在於給定的語言或庫中的標準化日期類別。在世界上不同的組織和地區之間,其標準與格式可能存在差異。
舉個例子,每個歐洲人在處理美國格式的日期時都會炸毛,即10.27.2018。如果DD/MM/YYYY和MM/DD/YYYY格式的日期被作為簡單字符串導入同一個數據集,可能很容易導致一些誤會或是模型運行不佳。該問題在於數據並不是簡單的數值數據。它並不能直接導入機器學習模型。最簡單的方法是將該數據拆分為3個整數特徵,分別代表日、月和年。但這並不是全部。我們還可以構建一些文化相關的特徵。例如,這一天是不是周末或是節假日。其它選項還有特定大事件開始的時間或日期,或者連續活動之間的間隔。此外,時間也一樣。它可以用時、分、秒來表示。但是也可以只按秒計時,或是從一個特定的大事件開始計算。例如,實際上大多數軟件都以標準時間1970年1月1日00:00:00作為時間的開始,這也可以很好地應用於特徵工程中。
示例:修補時間
我們可以拿一個日期起到重要作用的數據集舉例。這是一個來自the Blue Book for Bulldozers competition的數據集。
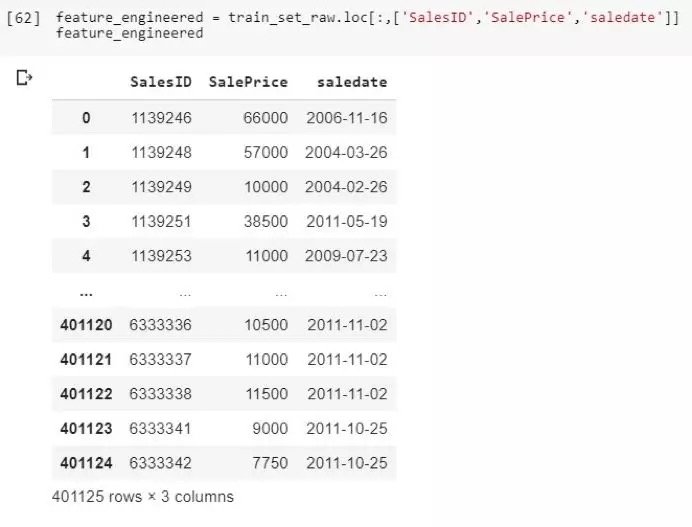
在這裡,我們藉助Python中的Pandas庫載入這個數據集。為了便於說明,我們只取三個特徵。SalesID表示交易編號,需要預測的是SalePrice。另外,在該數據集中能夠找到售出機器的更多信息和售出日期。我們可以稍稍利用日期。
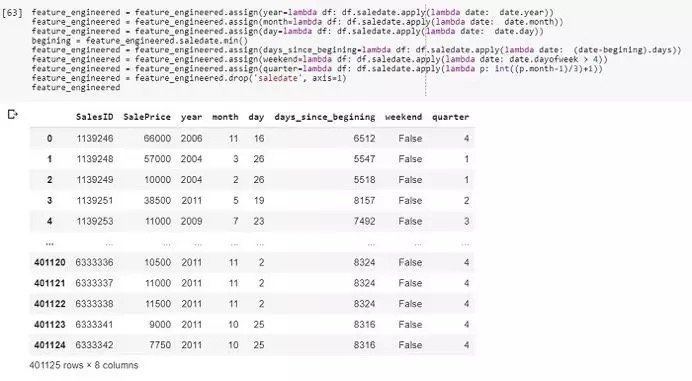
通過幾行簡單的代碼,日期列轉換成了6個可被模型讀取的特徵,可以利用它們來提取更多銷售信息。
文本
在計算機中,文本是以數字表示的ASCII代碼進行編碼的。這聽起來可能是個很好處理的東西,但是大錯特錯!從文本中提取信息需要藉助語言結構,也就是單詞中字母之間的關係和句子中的單詞本身。這跨越了一整個交叉學科領域的分支,叫做自然語言處理(NLP)。許多開發都是為了更輕鬆地提取這些信息。因為這至少需要另一篇文章或一整本書來闡釋,所以在這裡不再贅述。
從文本中分類
除了處理整個文本,還可以將其拆分成為單個單詞,並嘗試查找出現率最高的那一個。舉個例子,我們可能有權進入一些人力資源部門的數據庫。其中一個字段可能是學術頭銜。在這之中可能查找出許多類似於工科學士、理學碩士、哲學博士的字段。但是字段的數量會很龐大。可以從中提取的是例如學士、碩士、博士之類的詞語,省略特定的領域。這裡包含了一個含有4級(包括不含頭銜的)教育水平的分類特徵。一個相似的例子是帶稱謂的全名。在這個字段中會出現像Mr. Alan Turing、Mrs. Ada Lovelace、Miss Skłodowska之類的詞組。我們可以提取Mr.、Mrs.、Miss.等表示性別和婚姻狀況的稱謂。如你所見,利用文本數據的方法很多,並且無需使用NLP昂貴的全部計算性能。
圖表
如果不重新撰寫一整本專刊,可視化數據是第二種至少需要一篇單獨的文章進行討論的數據。分析這種數據的問題困擾了科學家們數十年之久。一整個計算機視覺領域應運而生。但值得一提的是,由於數年前深度學習革命,一種簡單的圖像分析方法隨之出現。卷積神經網絡(CNNs)可以通過使用其中一個通用的框架和顯卡強勁的計算性能,為沒有太多的計算機視覺(CV)或是特定科目領域知識的用戶提供一個合理的解決方案。
如你所見,在創建新的特徵方面存在許多可能性。其真實的目的是設計能夠促進數據科學過程的特徵。但是除了之前提及的方法,還有更多。例如,通過混合連續特徵和分類特徵來生成新的特徵。NLP和CV賦予了我們更多的特徵,但這並不是全部。全部掌握它們的唯一方法就是不斷地練習與實驗。因其巨大的多元性,特徵工程常常被稱為一門藝術。

Comments