

本文轉自公眾號 專知,原文地址
過去的一年裡,深度神經網路開創了自然語言處理的激動人心的時代。 使用預訓練模型的領域的研究已經導致許多NLP任務的最新結果的巨大飛躍,例如文本分類,自然語言推理和問答。一些關鍵的里程碑是ELMo,ULMFiT和OpenAI Transformer。 這些方法都允許我們在大型資料庫(例如所有維基百科文章)上預先訓練無監督語言模型,然後在下游任務上微調這些預先訓練的模型。也許這一領域今年最激動人心的事件是BERT的發布,這是一種基於多語言Transformer的模型,它在各種NLP任務中取得了最先進的成果。 BERT是一種基於Transformer架構的雙向模型,它以更快的基於注意的方法取代了RNN(LSTM和GRU)的順序特性。 該模型還預訓練了兩個無監督的任務,掩模語言建模和下一個句子預測。 這允許我們使用預先訓練的BERT模型,通過對下游特定任務(例如情緒分類,意圖檢測,問答等)進行微調。
我們將使用Kaggle的垃圾評論分類挑戰來衡量BERT在多標籤文本分類中的表現。
我們從哪裡開始?
Google Research最近公開了BERT的張量流實現,並發布了以下預先訓練的模型:
BERT-Base, Uncased: 12層, 768個隱層, 12-heads, 110M 個參數BERT-Large, Uncased: 24層, 1024個隱層, 16-heads, 340M 個參數BERT-Base, Cased: 12層, 768個隱層, 12-heads , 110M 個參數BERT-Large, Cased: 24層, 1024個隱層, 16-heads, 340M 個參數BERT-Base, Multilingual Cased (New, recommended): 104 種語言, 12層, 768個隱層, 12-heads, 110M 個參數BERT-Base, Chinese: Chinese Simplified and Traditional, 12層, 768個隱層, 12-heads, 110M 個參數
我們將使用較小的Bert-Base,無框架模型來完成此任務。 Bert-Base模型有12個層,所有文本都將由分詞器轉換為小寫。
我們將使用HuggingFace的優秀PyTorch BERT埠,可在https://github.com/huggingface/pytorch-pretrained-BERT獲得。 我們已經使用HuggingFace的repo中提供的腳本將預先訓練的TensorFlow檢查點轉換為PyTorch權重。
我們的實現很大程度上受到BERT原始實現中提供的run_classifier示例的啟發。
數據準備
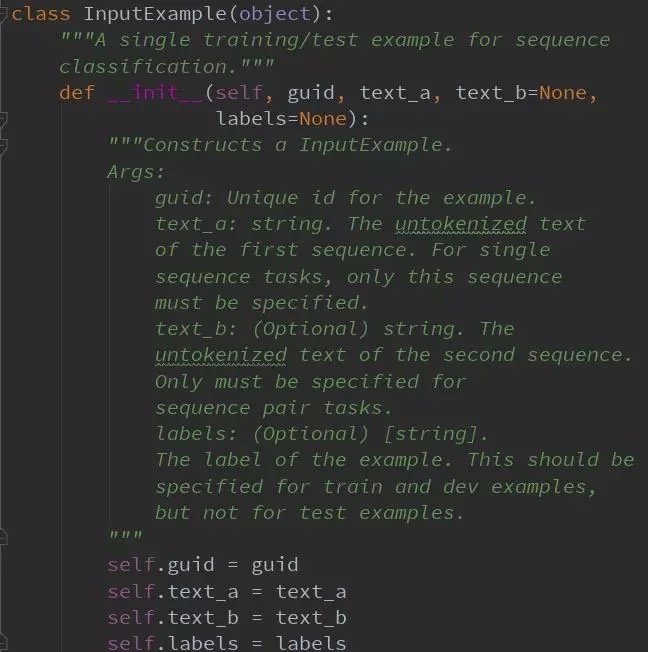
我們在類InputExample 準備數據:
- text_a: 評論內容
- text_b:未用到
- labels: 訓練數據對應為標籤,測試數據為空
分詞
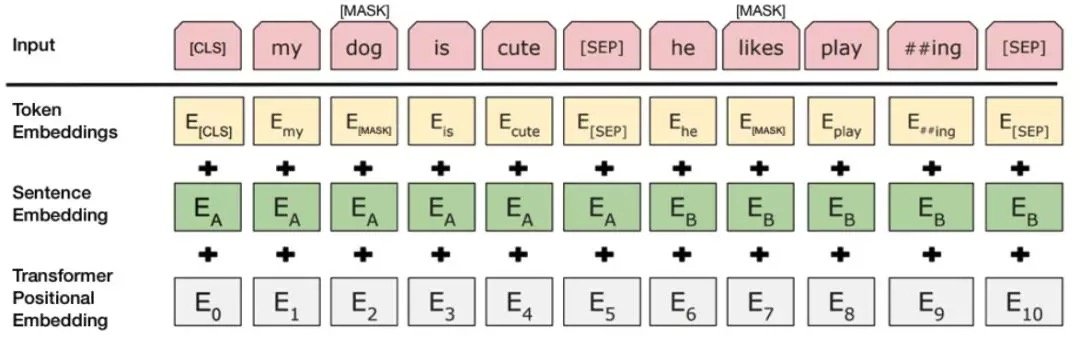
BERT-Base,無監督模型使用30,522個單詞的辭彙。 分詞過程涉及將輸入文本拆分為辭彙表中可用的標記列表。 為了處理辭彙表中不可用的單詞,BERT使用一種稱為基於BPE的WordPiece標記化技術。 在這種方法中,辭彙表之外的詞逐漸被分成子詞,然後該詞由一組子詞表示。 由於子詞是辭彙表的一部分,我們已經學習了表示這些子詞的上下文,並且該詞的上下文僅僅是子詞的上下文的組合。 有關此方法的更多詳細信息,請參閱使用子字詞單位的稀有單詞的神經機器翻譯模型。
https://arxiv.org/pdf/1508.07909。
模型結構
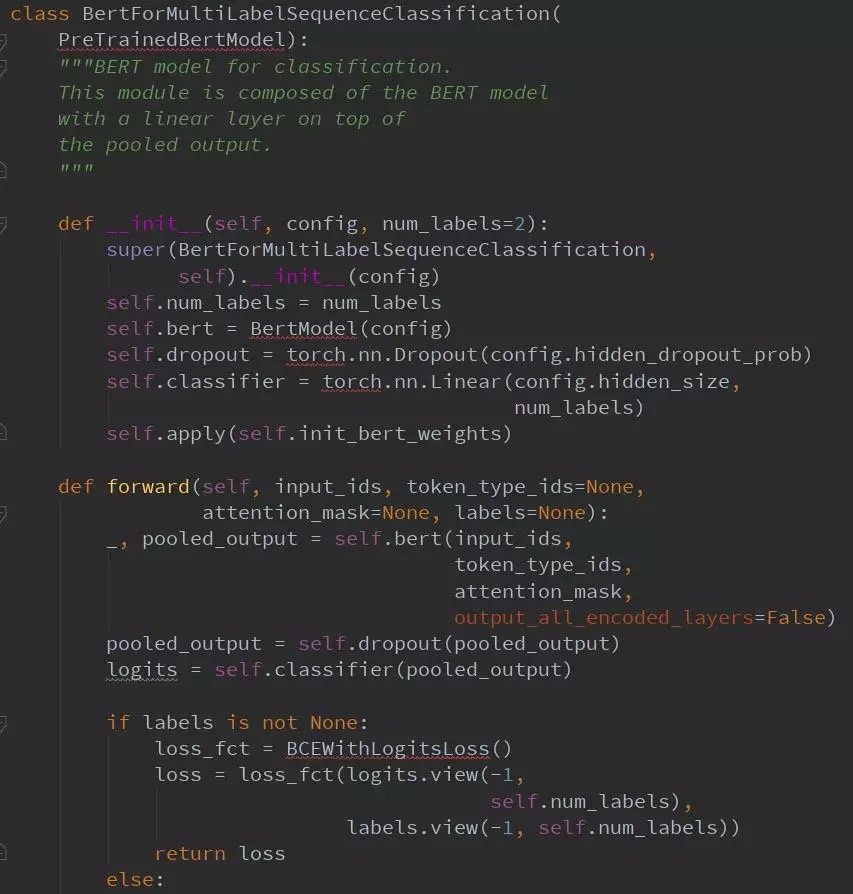

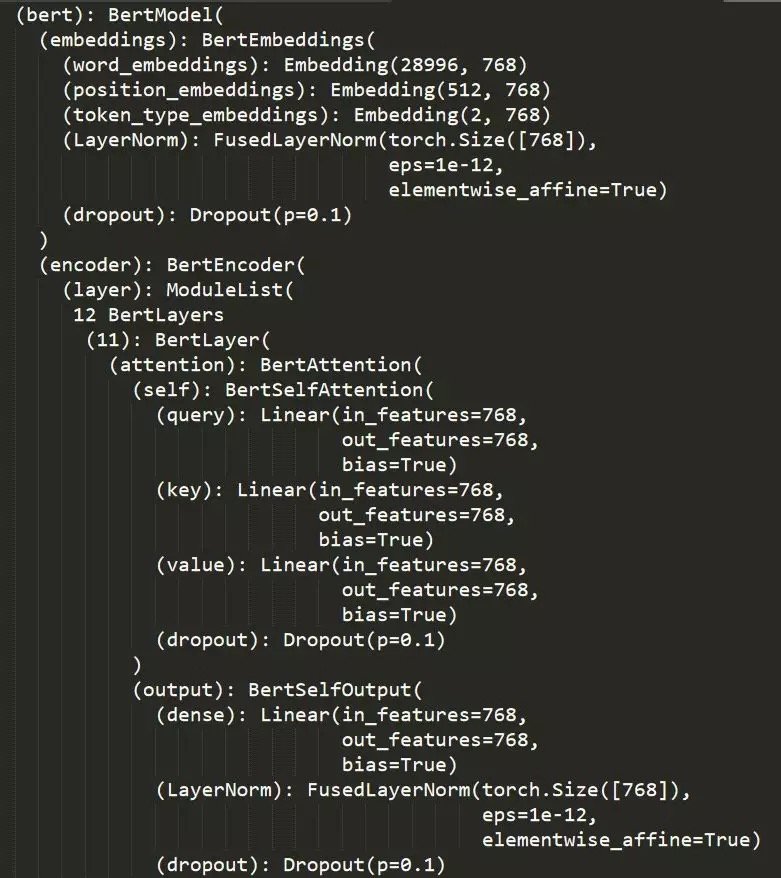
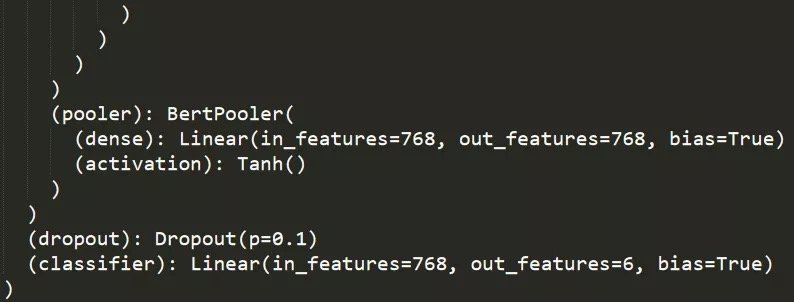
訓練
訓練循環與run_classifier.py中原始BERT實現中提供的循環相同。 我們訓練了4個時期的模型,批量大小為32,序列長度為512,即預訓練模型的最大可能性。 根據原始論文的建議,學習率保持在3e-5。
我們有機會使用多個GPU。 所以我們將Pytorch模型包裝在DataParallel模塊中。 這使我們能夠在所有可用的GPU上傳播我們的培訓工作。
由於某種原因我們沒有使用半精度FP16技術,具有logits loss函數的二進位crosss熵不支持FP16處理。 這並不會影響最終結果,只需要更長的時間訓練。
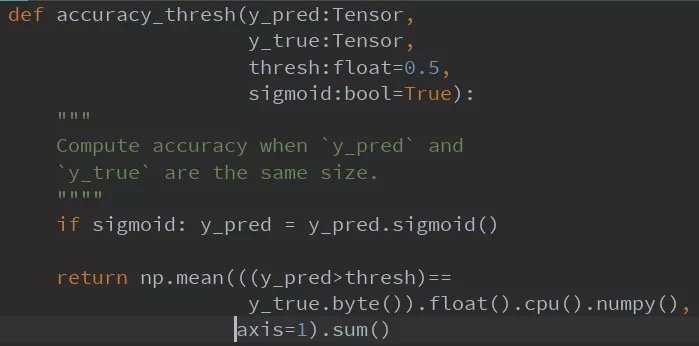
評估指標
我們調整了精度度量函數以包括閾值,默認設置為0.5。

對於多標籤分類,更重要的指標是ROC–AUC曲線。 這也是Kaggle比賽的評估指標。 我們分別計算每個標籤的ROC-AUC。 我們還在個別標籤的roc-auc分數上使用微觀平均。
我們進行了一些實驗,只有一些變化,但更多的實驗得到了類似的結果。
結果如下:
訓練損失:0.022,驗證損失:0.018,驗證準確度:99.31%
各個標籤的ROC-AUC分數:
toxic: 0.9988
severe-toxic: 0.9935
obscene: 0.9988
threat: 0.9989
insult: 0.9975
identity_hate: 0.9988
Micro ROC-AUC: 0.9987

Comments