

最近我們一直在看電腦玩人類遊戲,無論是多人遊戲機器人還是Dota2,PUB-G,Mario等一對一遊戲中的對手。當他們的AlphaGo計劃在2016年擊敗韓國圍棋世界冠軍時,Deepmind(一家研究公司)創造了歷史。如果你是一個激烈的遊戲玩家,可能你一定聽過Dota 2 OpenAI Five比賽,其中機器對抗人類在幾場比賽中擊敗世界頂級Dota2球員(如果你對此感興趣,這裡是對演算法和機器所玩遊戲的完整分析)。

所以這是核心問題,為什麼我們需要強化學習?它只用於遊戲嗎?或者它可以應用於現實世界的場景和問題嗎?如果您是第一次學習強化學習,那麼這個問題的答案超出了您的想像。它是人工智慧領域中廣泛使用和發展最快的技術之一。
以下是一些激勵您構建增強系統的應用程序,
- 自駕車
- 賭博
- 機器人
- 推薦系統
- 廣告與營銷
強化學習的簡要回顧與淵源
那麼,當我們掌握了大量的機器學習和深度學習技術時,這個強化學習的來源是什麼?「它由Rich Sutton和Andrew Barto發明,Rich的博士。論文顧問。「它已經在20世紀80年代形成,但當時是古老的。後來,Rich相信其有希望的性質,它最終會得到認可。
強化學習通過學習它所處的環境來支持自動化,機器學習和深度學習也是如此,不是相同的策略,而是支持自動化。那麼,為什麼要加強學習呢?
這非常類似於自然學習過程,其中,過程/模型將接收關於其是否表現良好的反饋。深度學習和機器學習也是學習過程,但最關注的是尋找現有數據中的模式。另一方面,強化學習通過反覆試驗方法進行學習,並最終獲得正確的行動或全局最優。強化學習的另一個顯著優勢是我們無需像監督學習一樣提供整個培訓數據。相反,一些塊就足夠了。
了解強化學習
想像一下,你正在教你的貓新技巧,但不幸的是,貓不懂我們的語言所以我們無法告訴他們我們想用它們做什麼。相反,模仿一種情況,你的貓試圖以許多不同的方式作出反應。如果貓的反應是理想的,我們會用牛奶獎勵他們。現在猜猜是什麼,下一次貓暴露在相同的情況下,貓會執行類似的動作,期望更多的食物更熱情。所以這是從積極的反應中學習,如果他們受到憤怒的面孔等負面反應的對待,他們往往不會向他們學習。
同樣,這就是強化學習的工作原理,我們給機器一些輸入和動作,然後根據輸出獎勵它們。獎勵最大化將是我們的最終目標。現在讓我們看看我們如何將上述同樣的問題解釋為強化學習問題。
- 貓將成為暴露於「環境」的「代理人」。
- 環境是一個房子/遊樂區,取決於你教給它的東西。
- 遇到的情況稱為「狀態」,例如,你的貓在床下爬行或跑步。這些可以解釋為狀態。
- 代理通過執行從一個「狀態」改變到另一個「狀態」的動作來做出反應。
- 在州改變之後,我們根據所執行的行動給予代理「獎勵」或「懲罰」。
- 「政策」是選擇行動以尋找更好結果的策略。
既然我們已經理解了強化學習的內容,那麼讓我們深入探討強化學習和深層強化學習的起源和演變,以及如何解決有監督或無監督學習無法解決的問題,這是有趣的事實上,Google搜索引擎使用強化演算法進行了優化。
熟悉強化學習術語
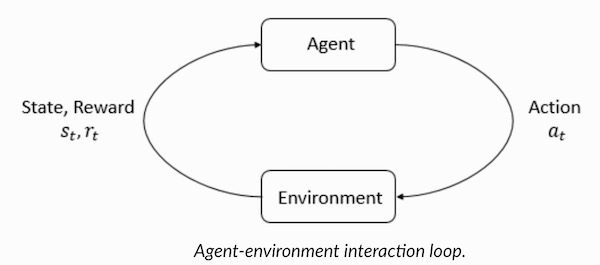
Agent和Environment在強化學習演算法中起著至關重要的作用。環境是代理人倖存的世界。代理人還會感知來自環境的獎勵信號,這個數字告訴它當前世界狀態的好壞。代理人的目標是最大化其累積獎勵,稱為回報。在我們編寫第一個強化學習演算法之前,我們需要理解以下「術語」。
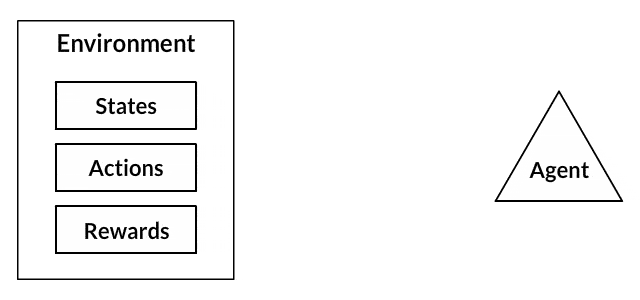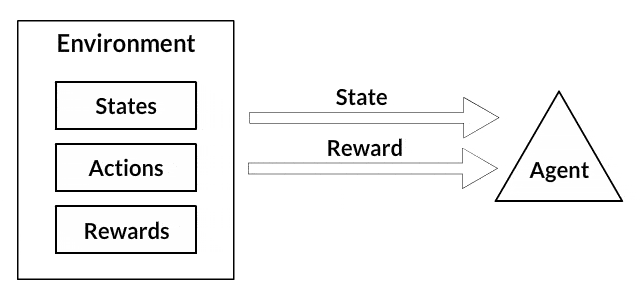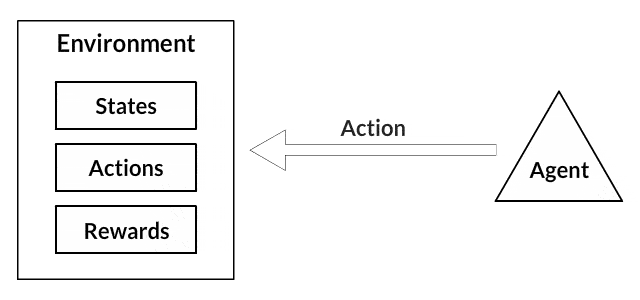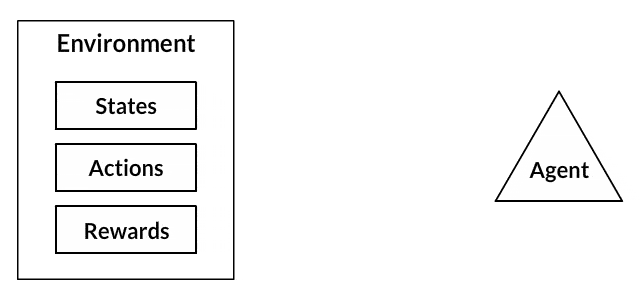
- 狀態:狀態是對世界的完整描述,它們不隱藏狀態上存在的任何信息。它可以是位置,常數或動態。我們主要在數組,矩陣或更高階張量中記錄這些狀態。
- 行動:行動通常基於環境,不同的環境導致基於代理的不同行為。代理的有效操作集記錄在稱為操作空間的空間中。這些通常是有限的。
- 環境:這是代理人生活和互動的地方。對於不同類型的環境,我們使用不同的獎勵,政策等。
- 獎勵和回報:獎勵函數R是必須在強化學習中一直被跟蹤的函數。它在調整,優化演算法和停止訓練演算法方面起著至關重要的作用。這取決於當前的世界狀況,剛剛採取的行動以及世界的下一個狀態。
- 策略:策略是代理用於選擇下一個操作的規則,這些也稱為代理大腦。
現在我們已經看到了所有的加固術語,現在讓我們使用強化演算法來解決問題。在此之前,我們需要了解我們如何設計問題並在解決問題時分配此強化學習術語。
解決計程車問題
現在我們已經看到了所有的加固術語,現在讓我們使用強化演算法來解決問題。在此之前,我們需要了解我們如何設計問題並在解決問題時分配這種強化學習術語。
假設我們的計程車有一個培訓區,我們教它將停車場的人員運送到四個不同的地方(R,G,Y,B) 。在此之前,我們需要了解並設置python開始運行的環境。如果你從頭開始做python,我會推薦這篇文章。
您可以使用OpenAi的Gym來設置Taxi-Problem環境,這是解決強化問題最常用的庫之一。好吧,在使用之前我們需要在你的機器上安裝健身房,為此,你可以使用python包安裝程序也稱為pip。以下是要安裝的命令。
pip install gym現在讓我們看看我們的環境將如何呈現,此問題的所有模型和界面已經在健身房配置並命名為Taxi-V2。要在下面呈現此環境,請參閱代碼段。
「有4個地點(用不同的字母標記),我們的工作是在一個地方接載乘客,然後將他送到另一個地方。我們獲得了+20分的成功下降,並且每走一步都會失去1分。非法接送和下車行動也將被罰10分。「(資料來源:https://gym.openai.com/envs/Taxi-v2/ )
這將是控制台上的渲染輸出:

完美,環境是OpenAi Gym的核心,它是統一的環境界面。以下是對我們非常有幫助的env方法:
env.reset:重置環境並返回隨機初始狀態。
env.step(action):將環境步進一步。
env.step(action)r eturns以下變數
observation:觀察環境。reward:如果你的行為有益或沒有done:表示我們是否已經成功接載並下降了一名乘客,也稱為一集info:用於調試目的的其他信息,如性能和延遲env.render:渲染一個環境框架(有助於可視化環境)
現在我們已經看到了環境,讓我們更深入地了解問題,計程車是這個停車場唯一的車。我們可以將停車場分成一個5x5網格,這為我們提供了25個可能的計程車位置。這25個地點是我們國家空間的一部分。請注意我們計程車的當前位置狀態是坐標(3,1)。
在環境中,[(0,0), (0,4), (4,0), (4,3)]如果您可以將上面渲染的環境解釋為坐標軸,則可以在四個可能的位置放置計程車中的乘客:R,G,Y,B或(行,列)坐標。
當我們還考慮到計程車內的一(1)個額外乘客狀態時,我們可以將乘客位置和目的地位置的所有組合來達到我們的計程車環境的總數。有四(4)個目的地和五(4 + 1)個乘客位置。所以,我們的計程車環境5×5×5×4=500總共有可能的狀態。代理遇到500個州中的一個,並採取行動。在我們的案例中,行動可以是向一個方向移動或決定接送乘客。
換句話說,我們有六個可能的操作:pickup,drop,north,east,south,west(。這四個方向是由計程車移動的移動)
這是:我們的代理在給定狀態下可以採取的所有操作的集合。action space
您將在上圖中注意到,由於牆壁,計程車無法在某些狀態下執行某些操作。在環境的代碼中,我們將簡單地為每個牆壁打擊提供-1懲罰,並且計程車不會移動到任何地方。這隻會受到處罰,導致計程車考慮繞牆而行。
獎勵表:創建計程車環境時,還會創建一個名為的初始獎勵表P。我們可以把它想像成一個矩陣,它將狀態數作為行數,將動作數作為列,即states × actions矩陣。
由於每個州都在這個矩陣中,我們可以看到分配給我們插圖狀態的默認獎勵值:
>>> import gym
>>> env = gym.make("Taxi-v2").env
>>> env.P[328]
{0: [(1.0, 433, -1, False)],
1: [(1.0, 233, -1, False)],
2: [(1.0, 353, -1, False)],
3: [(1.0, 333, -1, False)],
4: [(1.0, 333, -10, False)],
5: [(1.0, 333, -10, False)]
}這本詞典有一個結構{action: [(probability, nextstate, reward, done)]}。
- 0-5對應於計程車在圖示中的當前狀態下可以執行的動作(南,北,東,西,皮卡,下降)。
done用來告訴我們什麼時候我們成功地將乘客送到了正確的位置。
為了在沒有任何強化學習的情況下解決問題,我們可以設置目標狀態,選擇一些樣本空間,然後如果它通過多次迭代達到目標狀態,我們假設它是最大獎勵,否則如果它接近目標則獎勵增加如果步驟的獎勵是-10,則提高州和罰款minimum。
現在讓我們編寫這個問題,而不需要強化學習。
由於我們P在每個州都有我們的默認獎勵表,我們可以嘗試讓我們的計程車導航只使用它。
我們將創建一個無限循環,直到一個乘客到達一個目的地(一集),或者換句話說,當收到的獎勵是20.該env.action_space.sample()方法自動從所有可能動作的集合中選擇一個隨機動作。
讓我們看看發生了什麼:
import gym
from time import sleep
# Creating thr env
env = gym.make("Taxi-v2").env
env.s = 328
# Setting the number of iterations, penalties and reward to zero,
epochs = 0
penalties, reward = 0, 0
frames = []
done = False
while not done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
# Put each rendered frame into the dictionary for animation
frames.append({
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
}
)
epochs += 1
print("Timesteps taken: {}".format(epochs))
print("Penalties incurred: {}".format(penalties))
# Printing all the possible actions, states, rewards.
def frames(frames):
for i, frame in enumerate(frames):
clear_output(wait=True)
print(frame['frame'].getvalue())
print(f"Timestep: {i + 1}")
print(f"State: {frame['state']}")
print(f"Action: {frame['action']}")
print(f"Reward: {frame['reward']}")
sleep(.1)
frames(frames)輸出:
我們的問題已經解決但沒有優化,或者這個演算法不能一直工作,我們需要有一個合適的交互代理,這樣機器/演算法所需的迭代次數就會少得多。Q-Learning演算法讓我們看看它是如何在下一節中實現的。
Q-Learning簡介
這種演算法是最常用的基本強化演算法,它利用環境獎勵隨著時間的推移學習,在給定狀態下採取最佳動作。在上面的實現中,我們從代理將從中學習的獎勵表「P」。使用獎勵表,它選擇下一個動作,如果它有益,然後他們更新一個名為Q值的新值。創建的這個新表稱為Q表,它們映射到稱為(State,Action)組合的組合。如果Q值更好,我們會有更優化的獎勵。
例如,如果計程車面臨包括其當前位置的乘客的狀態,則與其他動作(例如,下降或北方)相比,拾取的Q值很可能更高。
Q值初始化為任意值,並且當代理將自身暴露給環境並通過執行不同的操作接收不同的獎勵時,使用以下等式更新Q值:
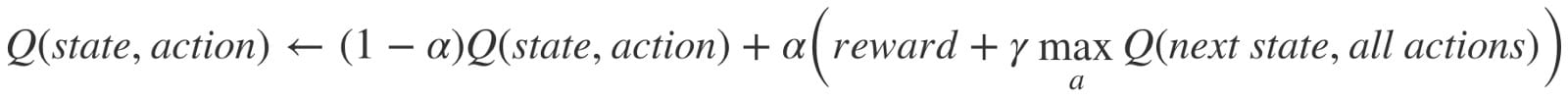
這裡有一個問題,如何初始化這個Q值以及如何計算它們,因為我們用任意常量初始化Q值,然後當代理暴露給環境時,它通過執行不同的動作接收各種獎勵。執行操作後,Q值由等式執行。
這裡Alpha和Gamma是Q學習演算法的參數。Alpha被稱為學習率,γ被稱為折扣因子,值的範圍在0和1之間,有時等於1。伽瑪可以為零,而阿爾法則不能,因為損失應該以一定的學習率更新。這裡的Alpha表示與監督學習中使用的相同。Gamma決定了我們希望給予未來獎勵多少重要性。
以下是演算法簡介,
- 步驟1:使用全零和Q值將Q表初始化為任意常量。
- 第2步:讓代理人對環境做出反應並探索行動。對於狀態中的每個更改,請為當前狀態(S)的所有可能操作中選擇任意一個。
- 步驟3:作為該動作(a)的結果,前進到下一個狀態(S’)。
- 步驟4:對於來自狀態(S’)的所有可能動作,選擇具有最高Q值的動作。
- 步驟5:使用等式更新Q表值。
- 狀態6:將下一個狀態更改為當前狀態。
- 步驟7:如果達到目標狀態,則結束並重複該過程。
Python中的Q-Learning
import gym
import numpy as np
import random
from IPython.display import clear_output
# Init Taxi-V2 Env
env = gym.make("Taxi-v2").env
# Init arbitary values
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# Hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.1
all_epochs = []
all_penalties = []
for i in range(1, 100001):
state = env.reset()
# Init Vars
epochs, penalties, reward, = 0, 0, 0
done = False
while not done:
if random.uniform(0, 1) < epsilon:
# Check the action space
action = env.action_space.sample()
else:
# Check the learned values
action = np.argmax(q_table[state])
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
# Update the new value
new_value = (1 - alpha) * old_value + alpha * \
(reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1
if i % 100 == 0:
clear_output(wait=True)
print("Episode: {i}")
print("Training finished.")完美,現在你所有的值都將存儲在變數中q_table 。
這就是你所有的模型都經過訓練,環境現在可以更準確地降低乘客。在那裡,你可以了解強化學習並能夠編碼新問題。
本文轉載自 towardsdatascience,原文地址

Comments