

本文轉載自公眾號 AI科技評論,原文地址
AI 科技評論按:目前人們對聊天機器人的認識還在調戲微軟小冰的階段,可以明顯感覺到小冰不是很關心上下文之間的關聯。而且在我們的觀念里,聊天機器人也沒辦法真的理解人類所說的話,沒辦法跟人類討論事情、明確地達到什麼共同目標。
不過,Facebook的人工智能研究機構FAIR剛剛開源並公開發表的聊天機器人就開始擁有了跟人類進行協商談判、進行討價還價的能力。通過監督學習+強化學習,這個聊天機器人不僅能理解字詞和語義的對應關係,還能針對自己的目標制定策略,跟別人進行協商討論達成一致。
以下為 AI 科技評論根據FAIR文章進行的詳細介紹。

生活的每一天里,我們一睜眼就要不停地跟別人協商事情。要麼是討論看哪個電視台,要麼是說服家裡小孩吃蔬菜,或者買東西的時候討價還價。這幾件事的共同點是,都需要複雜的交流和講理能力,而這些能力很難在計算機里見到。
發展到現在,聊天機器人方面的研究已經可以形成聊天系統,它能進行簡短對話,能完成訂餐館這樣的簡單任務。但是讓機器人跟人進行有意義的對話還是很難的,因為這需要機器人把它對對話的理解和它對世界的知識進行組合,然後再生成一句能幫它達到自己的目標的句子。
今天,Facebook FAIR的研究員們開源並公開發表的聊天機器人有了一項新能力,這個新能力就是協商。
有着不同目標的人類之間會產生衝突,然後通過協商達成一種大家共同認可的妥協,現在研究員們證明了聊天機器人也可以做到這些。具有不同目標的聊天機器人(具體實現是端到端訓練的神經網絡)在一段從頭到尾的協商中,可以跟其它聊天機器人或者人類一起做出共同的決定或者達到共同的目標。
任務:多種類討價還價
FAIR的研究員們研究了一種多種類討價還價任務下的協商任務。給兩個智能體展示同一組物體(比如2本書,1個帽子,3個籃球),為了能把東西分給它們,就需要教它們協商自己分到的數目。
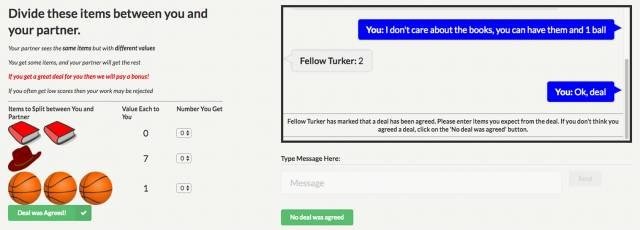
每個智能體都有自己的價值函數,它代表了智能體對每種物體的關心程度如何(比如在智能體1看來每個籃球值3分)。然後,就像生活中一樣,每個智能體都沒法確切知道別的智能體的價值函數,只能從對話中進行推測(如果對方說他想要籃球,那在他看來籃球的分值肯定比較高)。
FAIR的研究員們設計了很多類似這樣需要協商的情境,而且始終不會讓兩個智能體同時達成自己最滿意的分法。以及,如果拒絕協商(或者如果10輪對話以後還沒達成一致),那麼兩個智能體都會得0分。簡單說,進行協商是關鍵,如果還協商到了一個好的結果那就得分更高。
對話推演(Dialog Rollouts)
協商是一個語言性和講理性的綜合問題,其中的參與者要先形成自己的意圖,還要能用語言表達出來。合作和對抗的元素都會出現在這些對話中,這就需要智能體們理解並形成長期計劃,然後據此進行表達以便達到自己的目標。
為了建立這種有長期計劃能力的對話智能體,FAIR研究員們有一個核心的技術創新,他們把這個點子叫做“對話推演”(dialog rollouts)。
如果聊天機器人可以建立對談者的虛擬模型然後“提前考慮”,或者預感到未來對話的可能方向,它們就可以選擇避開沒有信息量的、引發困惑的或者糟糕的來回討論,轉而向著成功一些的方向去。
具體來說,FAIR開發出了對話推演這樣的新穎技術,一個使用這種技術的智能體可以一直模擬未來的對話到結尾,這樣它就可以選出可以在未來帶來最高收益的話語。
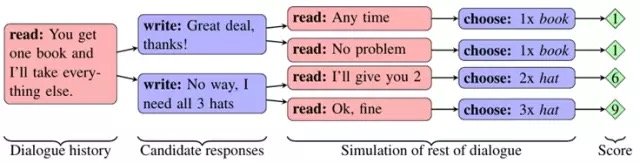
類似的方法已經在遊戲環境中得到過應用,但是用來解決語言問題還是第一次,因為可選擇的行動數目要多多了。為了提高效率,研究員們首先生成了一組數量不多的話語可供選擇,然後為了估計這些話語是否成功,他們對其中的每一條都反覆模擬完整的後續對話。這個模型的預測準確率足夠高,也要歸功於這項技術從以下幾個方面顯著提升了協商水平:
- 協商時候更努力:這些新的智能體能跟人類進行更長的對話,代價是對價碼的接受會慢一點。相比人類有時候不達成一致就走掉了,這個實驗中的模型會一直協商到取得成功的結果為止。
- 智能化的應對:有時候會出現這樣的狀況,智能體一開始會假裝對沒什麼價值的東西感興趣,就為了後來可以放棄它們來表現出自己在“妥協”,這確實是一個人類經常使用的談判技巧。這種行為可不是研究員們設計給它們的,而是智能體在想辦法達成目標的過程中自己發現的談判方法。
- 產生新穎的句子:儘管神經網絡模型可以很輕鬆地從訓練數據中重複一些句子,這項研究也展示出在有必要的時候模型也能自己生成一些句子。
建立及評價一個協商數據集
為了能夠訓練協商智能體以及做大規模量化評估,FAIR團隊用眾包的方法建立了一個人和人之間協商對話的數據集。其中參與的人看到了一組東西和每個東西的價值,然後要商量他們之間怎麼分這些東西。然後研究員們就用這些對話訓練出了一個能模仿人類行為進行協商的循環神經網絡(RNN)。在對話中的任何時刻,這個模型都會猜測人類在這種狀況下會說什麼。
在以前目標導向的對話研究中,模型都是完全由人類的語言和決定進行“端到端”訓練得到的,這意味着這種方法可以方便地用在其它任務中。
為了讓模型不僅僅停留在對人類的模仿,FAIR的研究員們接下來讓模型轉而向完成協商的目標發展。為了讓模型達到目標,研究員們讓模型自己跟自己進行了上千輪協商,並且用到了強化學習在得到好的結果的時候獎勵模型。為了避免讓算法生成自己的一套語言,模型同時也要訓練生成類人的語言。
為了評價這些協商智能體,FAIR讓它們上網跟人類聊天。之前的大多數研究都在避免跟真人聊天,或者研究的是難度更低的領域,這都是因為對各種各種的人類語言進行回答需要訓練複雜的模型。
有意思的是,在FAIR的實驗中,多數人都沒發現跟他們聊天的不是真人,而是機器人,說明機器人已經學會如何在這個領域流暢地用英文進行對話了。FAIR最優秀的協商機器人就運用了強化學習和對話推演,它的表現已經可以跟人類談判員相提並論。它達成的交易里,較好一些的和糟糕一些的差不多多,這也說明了FAIR的聊天機器人不僅會說英語,而且還能智能地考慮應該說什麼。
用於聊天機器人的強化學習
監督學習可以模仿人類用戶的動作,但是它沒法具體表現出達成目標的意志。FAIR團隊選了另一種方法,他們先用監督學習進行預訓練,然後用強化學習的方法結合評價指標對模型進行微調。以結果來說,他們用監督學習學到了如何把語言文字和意思相對應,然後用強化學習幫助判斷說什麼語句。
在增強學習中,智能體會試着根據自己與另一個智能體之間的對話優化自己的參數。不過同時這另一個智能體也可以是一個人,所以FAIR就用了一個訓練過的監督學習模型來模仿人類。這個模仿人類的模型是固定不變的,因為研究者們發現如果兩個模型的參數都可以優化的話,它們之間的對話就會偏離人類的語言,演化出一種它們自己的談判語言。在每一場對話結束以後,智能體都會根據自己談成的結果得到獎勵。這種獎勵是用智能體整個過程里的所有語言輸出運用策略梯度進行反向傳播得到的,目的是為了讓智能體有更高的可能性選擇會有更高獎勵的動作。
期待更高發展
對Facebook來說這是一項突破性的研究,對整個研究領域和機器人開發者來說,這是建立能講道理、交談、協商的機器人的重大進展,而這幾項都是建立個性化數字助理的重要組成部分。
對FAIR的研究人員而言,他們也希望與其它的研究人員繼續共同討論研究成果、共同分析想要解決的問題。他們也期待更多有才幹的人投入想法和精力,推動這個領域進一步發展。
via Deal or no deal? Training AI bots to negotiate,AI 科技評論編譯

Comments