

本文轉載自公眾號 新智元,原文地址
【新智元導讀】無監督學習是機器學習技術中的一類,用於發現數據中的模式。本文介紹用Python進行無監督學習的幾種聚類算法,包括K-Means聚類、分層聚類、t-SNE聚類、DBSCAN聚類等。
無監督學習是機器學習技術中的一類,用於發現數據中的模式。無監督算法的數據沒有標註,這意味着只提供輸入變量(X),沒有相應的輸出變量。在無監督學習中,算法自己去發現數據中有意義的結構。
Facebook首席AI科學家Yan Lecun解釋說,無監督學習——即教機器自己學習,不需要明確地告訴它們所做的每一件事情是對還是錯,是“真正的”AI的關鍵。
監督學習 VS 無監督學習
在監督學習中,系統試圖從之前給出的例子中學習。反之,在無監督學習中,系統試圖從給出的例子中直接找到模式。因此,如果數據集有標記,那麼它是有監督問題,如果數據集無標記,那麼它是一個無監督問題。

如上圖,左邊是監督學習的例子; 我們使用回歸技術來尋找特徵之間的最佳擬合線。而在無監督學習中,輸入是基於特徵分離的,預測則取決於它屬於哪個聚類(cluster)。
重要術語
- 特徵(Feature):用於進行預測的輸入變量。
- 預測(Predictions):當提供一個輸入示例時,模型的輸出。
- 示例(Example):數據集的一行。一個示例包含一個或多個特徵,可能有標籤。
- 標籤(Label):特徵的結果。
為無監督學習做準備
在本文中,我們使用Iris數據集(鳶尾花卉數據集)來進行我們的第一次預測。該數據集包含150條記錄的一組數據,有5個屬性——花瓣長度,花瓣寬度,萼片長度,萼片寬度和類別。三個類別分別是Iris Setosa(山鳶尾),Iris Virginica(維吉尼亞鳶尾)和Iris Versicolor(變色鳶尾)。對於我們的無監督算法,我們給出鳶尾花的這四個特徵,並預測它屬於哪一類。我們在Python中使用sklearn Library來加載Iris數據集,並使用matplotlib來進行數據可視化。以下是代碼片段。
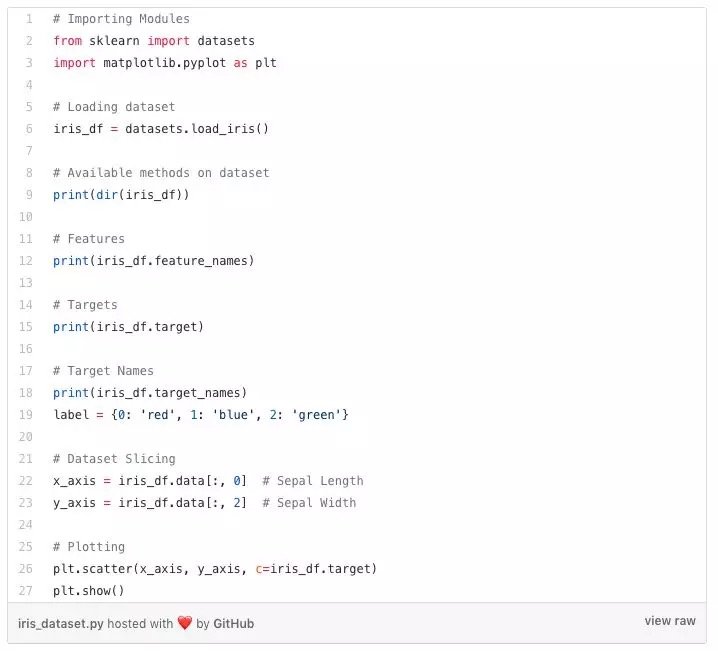


聚類(Clustering)
在聚類中,數據被分成幾個組。簡單地說,其目的是將具有相似特徵的組分開,並將它們組成聚類。
可視化示例:

在上圖中,左邊的圖像是未完成分類的原始數據,右邊的圖像是聚類的(根據數據的特徵對數據進行分類)。當給出要預測的輸入時,就會根據它的特徵在它所屬的聚類中進行檢查,並做出預測。
Python中的K-Means聚類
K-Means是一種迭代聚類算法,它的目的是在每次迭代中找到局部最大值。首先,選擇所需數量的聚類。由於我們已經知道涉及3個類,因此我們通過將參數“n_clusters”傳遞到K-Means模型中,將數據分組為3個類。
現在,隨機將三個點(輸入)分成三個聚類。基於每個點之間的質心距離,下一個給定的輸入被分為所需的聚類。然後,重新計算所有聚類的質心。
聚類的每個質心是特徵值的集合,定義生成的組。檢查質心特徵權重可以定性地解釋每個聚類代表什麼類型的組。
我們從sklearn庫導入K-Means模型,擬合特徵並進行預測。
Python中的K Means實現:
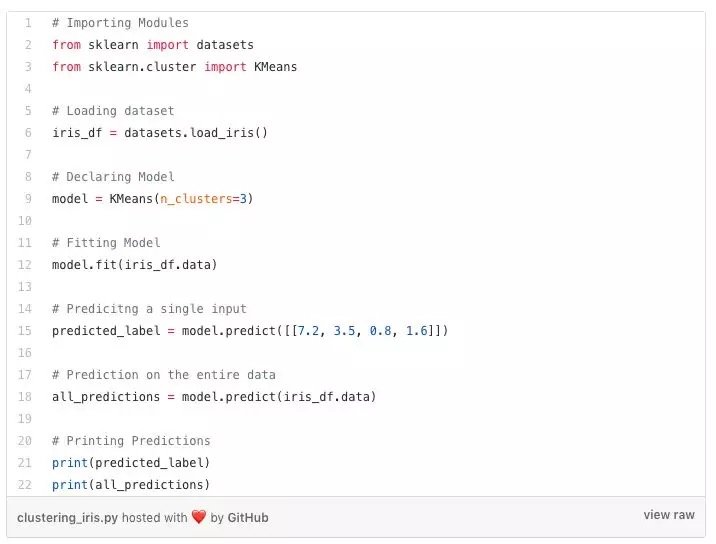

分層聚類
顧名思義,分層聚類是一種構建聚類層次結構的算法。該算法從分配給它們自己的一個cluster的所有數據開始,然後將最近的兩個cluster加入同一個cluster。最後,當只剩下一個cluster時,算法結束。
分層聚類的完成可以使用樹狀圖來表示。下面是一個分層聚類的例子。 數據集可以在這裡找到:https://raw.githubusercontent.com/vihar/unsupervised-learning-with-python/master/seeds-less-rows.csv
Python中的分層聚類實現:


K Means聚類與分層聚類的區別
- 分層聚類不能很好地處理大數據,但K Means聚類可以。因為K Means的時間複雜度是線性的,即O(n),而分層聚類的時間複雜度是二次的,即O(n2)。
- 在K Means聚類中,當我們從聚類的任意選擇開始時,多次運行算法產生的結果可能會有所不同。不過結果可以在分層聚類中重現。
- 當聚類的形狀是超球形時(如2D中的圓形,3D中的球形),K Means聚類更好。
- K-Means聚類不允許嘈雜的數據,而在分層聚類中,可以直接使用嘈雜的數據集進行聚類。
t-SNE聚類
t-SNE聚類是用於可視化的無監督學習方法之一。t-SNE表示t分布的隨機近鄰嵌入。它將高維空間映射到可以可視化的2或3維空間。具體而言,它通過二維點或三維點對每個高維對象進行建模,使得相似的對象由附近的點建模,而不相似的對象很大概率由遠離的點建模。
Python中的t-SNE聚類實現,數據集是Iris數據集:
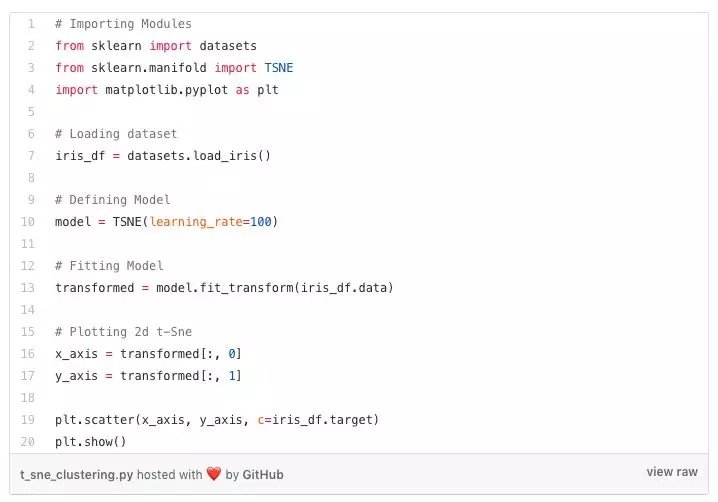

這裡Iris數據集具有四個特徵(4d),它被變換並以二維圖形表示。類似地,t-SNE模型可以應用於具有n個特徵的數據集。
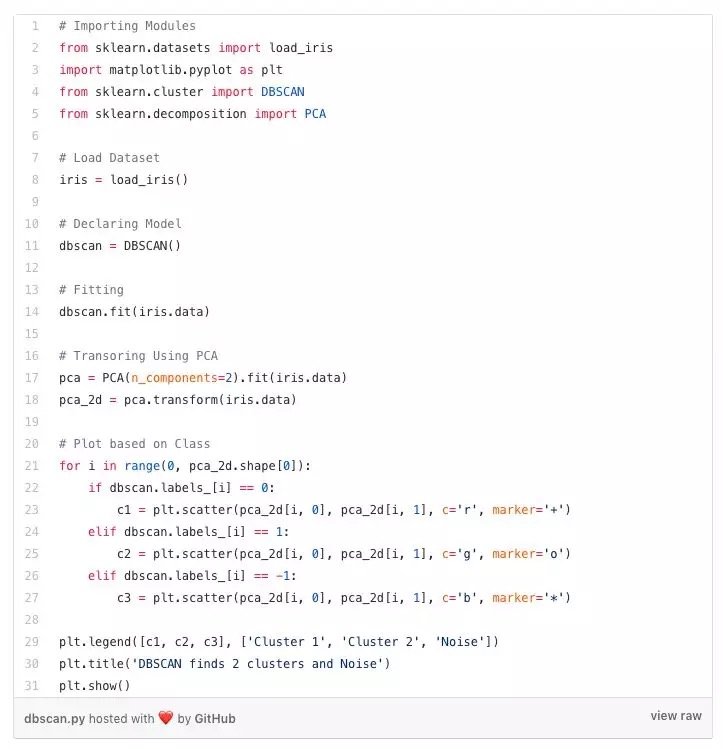
DBSCAN聚類
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪聲的基於密度的聚類方法)是一種流行的聚類算法,用作預測分析中 K-means的替代。它不要求輸入聚類的數值才能運行。但作為交換,你必須調整其他兩個參數。
scikit-learn實現提供了eps和min_samples參數的默認值,但這些參數通常需要調整。eps參數是在同一鄰域中考慮的兩個數據點之間的最大距離。min_samples參數是被認為是聚類的鄰域中的數據點的最小量。
Python中的DBSCAN聚類:

更多無監督技術:
- 主成分分析(PCA)
- 異常檢測(Anomaly detection)
- 自動編碼(Autoencoders)
- 深度置信網絡(Deep Belief Nets)
- Hebbian Learning
- 生成對抗網絡(GAN)
- 自組織映射(Self-Organizing maps)

Comments