

从 BOW 到 BERT
自 2013 年 Mikolov 等人提出了 Word2Vec 以来,我们在词嵌入方面已经有了很多发展。如今,几乎所有机器学习业内人士都能熟背“国王减去男人加上女人等于女王”这类箴言。目前,这些可解释的词嵌入已成为许多基于深度学习的 NLP 系统的重要部分。
去年 10 月初,Google AI 提出了 BERT 表征——Transformer 双向编码表征(论文链接:https://arxiv.org/abs/1810.04805,项目代码:https://github.com/google-research/bert)。看上去,Google 又完成了惊人之举:他们提出了一种新的学习上下文词表征的模型,该模型在 11 个 NLP 任务上都优化了当前最好结果,“甚至在最具挑战性的问答任务上超过了人类的表现”。然而,这中间仍然存在着一个问题:这些上下文词表示究竟编码了什么内容?这些特征是否能像 Word2Vec 生成的词嵌入那样具有可解释性?
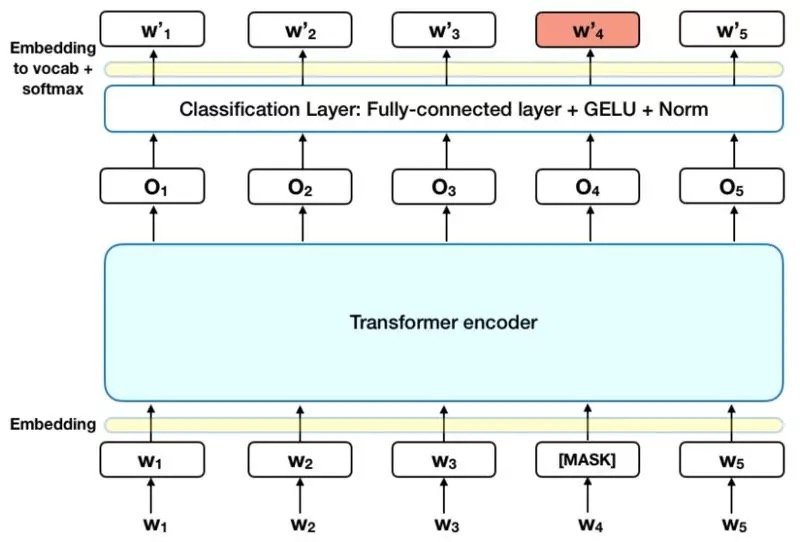
本文就重点讨论上述问题:BERT 模型生成的固定词表征的可解释性。我们发现,不用分析得太过深入,我们就能观察到一些有趣的现象。
分析 BERT 表征
无上下文方式
我们先来看一个简单例子——不管任何上下文。这里,我们先忽略掉 BERT 其实是在一串连续的表征上训练的这一事实。在本文讲到的所有实验中,我们都会进行以下两个操作:
- 提取目标词的表征
- 计算词之间的余弦距离
提取“男人”,“女人”,“国王”和“女王”这几个词的向量特征,我们发现,在进行了经典重建操作(即国王减去男人加上女人)后,重建的词向量实际上距离女王更远了。
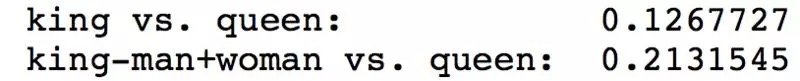
但实际上,也许我们这样测试 BERT 并不合理。BERT 本来是被训练用于 Masked-LM 和 Next-Sequence-Prediction 这类序列预测任务的。换句话说,BERT 中的权重是在使用了上下文信息建立词表征的条件下获得的。它不仅仅是一个学习上下文无关表征的损失函数。
上下文方式
为了消除上一节中的不合理性,我们可以在正确语境中使用我们的词汇来构建句子,如“国王通过法律”,“女王通过法律”,“冰箱很凉”等等。在这些新的条件下,我们开始研究:
- 特定单词的表示如何在不同的上下文中使用(例如,作为主语还是宾语,以不同的描述性形容词为条件,以及与无上下文的单词本身相对应)。
- 当我们从正确的上下文中提取表征时,语义向量空间假设是否还会成立。
我们先从一个简单的实验开始。使用“冰箱”这一词汇,我们造了以下 5 个句子:
- 冰箱(在无任何上下文的情况下使用 冰箱 一词)
- 冰箱在厨房里(将 冰箱 作为句子的主语)
- 冰箱很凉(仍然是将 冰箱 作为句子的主语)
- 他把食物放在冰箱里(将 冰箱 作为介词“在……里”的宾语)
- 冰箱通过了法律(把 冰箱 用在不合理的语境里)
在这里,我们确认了我们之前的假设,并发现使用没有任何上下文的冰箱会返回一个与在适当的环境中使用冰箱非常不同的表示。另外,将 冰箱 作为主语的句子(句子 2,3)返回的表示比将冰箱作为宾语的句子(句子 4)和不合理上下文(句子 5)所返回的表示更相似。

我们来再看一个例子,这次使用 派 这个词。我们还是造 5 个句子:
- 派(在无任何上下文的情况下使用 派 一词)
- 那个人吃了一个派(使用 派 作为宾语)
- 那个人扔掉了一个派(使用 派 作为宾语)
- 那块派很美味(使用 派 作为主语)
- 那块派吃了一个人(把 派 用在不合理的语境里)
我们观察到的趋势和上一个冰箱实验很相似。

接下来,我们来看看最早的 国王、女王、男人 和 女人 的例子。我们来造 4 个几乎一样的句子,只改变它们的主语。
- 国王通过了法律
- 女王通过了法律
- 男人通过了法律
- 女人通过了法律
从以上句子里,我们提取主语的 BERT 表征。在这个例子中,我们得到了更好的结果:国王减去男人加上女人和女王之间的余弦距离缩小了一点点。

最后,我们来看一下当句子结构不变但句子情感不同时,词表征有什么变化。这里,我们造三个句子。
- 数学是一个困难的学科
- 数学是一个难学的学科
- 数学是一个简单的学科
使用这些句子,我们可以探讨当我们改变情感时主题和形容词表示会发生什么变化。有趣的是,我们发现同义(即困难和难学)的形容词具有相似的表示,但是反义词(即困难和简单)的形容词具有非常不同的表示。
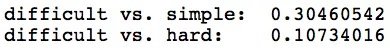
另外,当我们改变情感时,我们发现,主语数学在句子情感相同时相似度更高(如困难和难学),而在情感不同时相似度低(如困难和简单)。

总之,我们的实验结果似乎表明,像 Word2Vec 一样,BERT 也可以学习语义向量表示(尽管不那么明显)。BERT 似乎确实非常依赖于上下文信息:没有任何上下文的单词与具有某些上下文的相同单词非常不同,而且不同的上下文(如改变句子情感)也会改变主语的表示。
不过请记住,在证据有限的情况下总是存在过度概括的风险。本文所做的这些实验并不完整,只能算是一个开始。我们使用的样本规模非常小(相对于英语单词的海量词典来说),同时我们是在非常特定的实验数据集上评估非常特定的距离度量(余弦距离)。分析 BERT 表示的未来工作应该在所有这些方面有所扩展。最后,感谢 John Hewitt 和 Zack Lipton 提供了有关该主题的这一很有意义的讨论。
本文转自公众号 AI前线,原文地址

Comments