

当我在大学时,附近有一家冰淇淋店,我和几个朋友去看看。我们走了进去,它看起来完全正常 – 它们有所有常见的味道,如薄荷,巧克力等。然而,在柜台的尽头,他们有这种味道叫做“西兰花惊喜”。一个自然好奇的人,我不得不尝试。我向柜台后面的服务员询问样品。它是白色的,带有少许绿色斑点,味道甜美,奶油味浓郁。我很困惑 – 这里没有西兰花的味道。所以我问,“有什么惊喜?”“没有西兰花,”她笑着回答。
机器学习(ML)也有惊喜。关于组织内部ML部署的最大误解之一是理解困难和价值。
将ML集成到您的业务工作流程中可以分为五个活动:
定义关键绩效指标 – 关键绩效指标使我们能够衡量和讨论我们正在努力改进的内容。常见的KPI包括客户保留,制造收益或员工流动。设置KPI是机器学习中的关键步骤,因为它们最终会推动优化到高性能模型。
收集数据 – 收集将用于训练ML算法的数据。是的,如果您缺少数据,您可以使用其他人生产的ML模型。但是,这些业务考虑与其他SaaS产品类似,所以让我们将它们排除在范围之外。
基础设施 – ML基础设施包括各种软件:数据管理,注释工具,模型培训和测试环境。此基础架构是一项前期投资,但可以更有效地迭代和改进模型和数据集。
优化ML算法 – 在这里我们考虑基于给定数据集/问题使用哪种模型,必要训练数据量,神经网络中的层以及超参数调整等因素。有太多的选择。
集成 – 让ML模型在真空中工作是一项伟大的成就,但直到模型与真实的工作流程集成才开始产生切实的业务影响。集成是构建管道和结构的过程,可以在用户和计算机之间无缝传递信息和数据。
基于与有兴趣部署机器学习的公司的许多对话,在优化机器学习算法中需要很高的感知努力并从中获益。

这有几个可能的原因:
- 对于大多数从业者来说,优化ML模型是堆栈中最大的“未知”,因此很容易想象它比实际更复杂和耗时。
- 可用性启发式 – 由于ML算法和优化在文献和媒体中被更多地讨论,人们通常认为它们比实际实现过程中扮演更大的角色。
惊喜
当我与在Google内部构建和扩展这些ML系统的经验丰富的从业者交谈时,我听到了一个非常不同的故事。基于这些对话,优化ML算法所需的相对努力要少得多,但是 收集数据, 建筑基础设施 和 积分 每需要做更多的工作。期望与现实之间的差异是深远的。
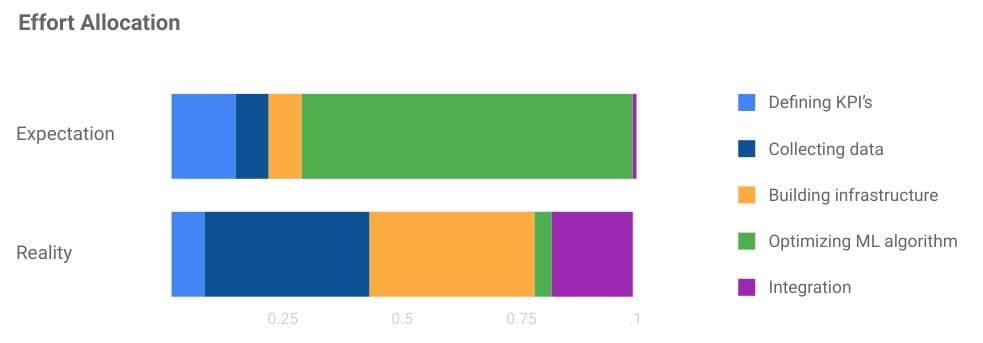
定义KPI – 一旦我们部署了数据驱动的系统,我们就会花更少的时间和组织资源来选择KPI,因为有不断的数据反馈流。这消除了对代理KPI的需求。由于良好的ML取决于良好的数据,我们必须拥有一个很好的收集管道。
收集数据 – 收集数据几乎总是低估了启动ML项目的组成部分。在上一篇文章中描述了构建数据收集和处理策略时要考虑的一些因素。
基础设施 – 基础设施建设,主要是软件工程任务,而不是“ML任务”,是大多数项目中最耗时的部分之一。
优化ML算法 – 培训和优化ML模型的任务几乎总是花费比预期更少的时间和精力,原因有两个。首先,性能是您拥有的数据的强大功能。然而,与清理数据相比,调整算法带来的好处相形见绌。其次,用于优化ML算法的工具(如AutoML)使得基于标记或未标记数据训练和优化模型变得更加容易和快捷。
集成 – 集成是ML部署过程中另一个被低估的部分。错误和异常处理,冗余以及从静态产品转移到连续迭代之一的挑战提出了许多软件,产品和工程挑战。想想你的训练数据中隐藏的所有技术债务!
– –
ML实际上有两个惊喜。
首先,许多公司错误地认为ML实施过程的哪些部分将是困难的。工具和技术进步正大大改变了ML优化,其速度是软件基础设施所无法比拟的,用于强力数据收集和管理。像西兰花冰淇淋一样 – 在端到端的ML系统中通常没有那么多的ML。
其次,实施ML 的路径(询问有关您的客户的问题,建立基础设施以收集,解释和处理该数据等)是有价值的,无论ML到底是否实际实施。并非所有问题都有ML驱动的解决方案,但许多问题都有,甚至那些没有问题的解决方案也会受益于这一旅程。
本文转自medium,原文地址


Comments