

本文转载自机器之心,原文地址
谷歌大脑最新研究提出通过神经架构搜索寻找更好的 Transformer,以实现更好的性能。该搜索得到了一种名为 Evolved Transformer 的新架构,在四个成熟的语言任务(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十亿词语言模型基准(LM1B))上的表现均优于原版 Transformer。
在过去的几年里,神经架构搜索领域取得了极大进展。通过强化学习和进化得到的模型已经被证明可以超越人类设计的模型(Real et al., 2019; Zoph et al., 2018)。这些进展大多聚焦于改善图像模型,但也有一些研究致力于改善序列模型(Zoph & Le, 2017; Pham et al., 2018)。但在这些研究中,研究者一直致力于改良循环神经网络(RNN),该网络长期以来一直用于解决序列问题(Sutskever et al., 2014; Bahdanau et al., 2015)。
然而,最近的研究表明,RNN 并非解决序列问题的最佳方法。由于卷积网络(如卷积 Seq2Seq)(Gehring et al., 2017)和完全注意力网络(如 Transformer)(Vaswani et al., 2017)的成功,前馈网络已经可以用于解决 seq2seq 任务,它的主要优势在于训练速度比 RNN 快,训练起来也更加容易。
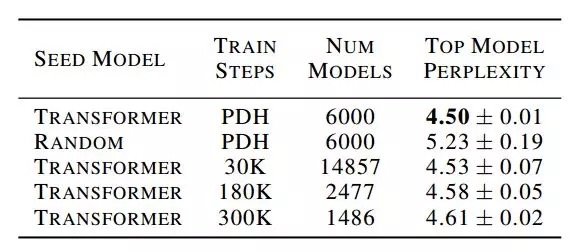
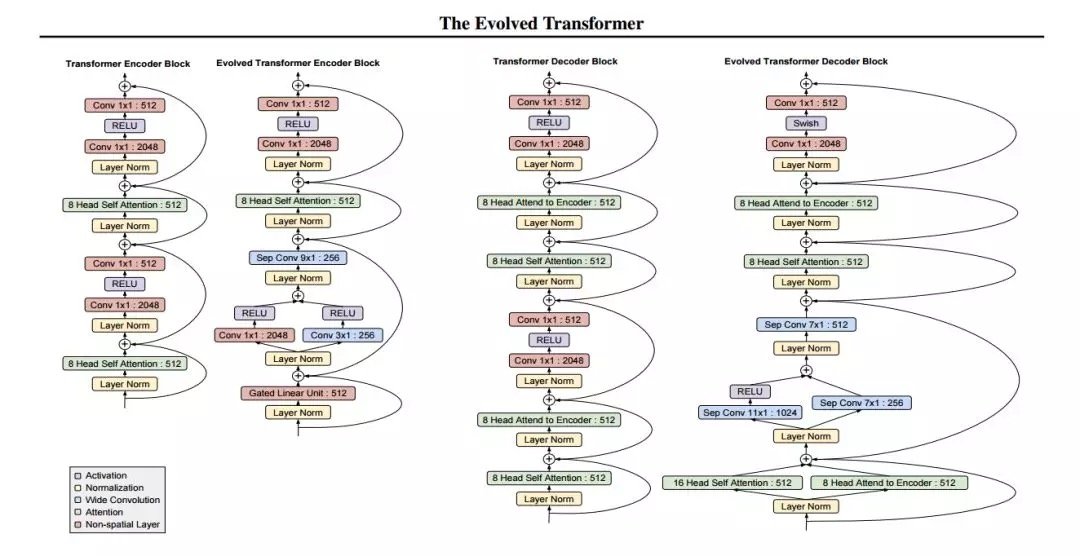
本文旨在检验神经架构搜索方法的使用,为 seq2seq 任务设计更好的前馈架构。具体来说,谷歌大脑研究人员使用锦标赛选择(tournament selection)架构搜索,从 Transformer(被认为是当前最佳、应用最广的架构)演化出更好、更高效的架构。为了实现这一点,研究者构建了一个反映前馈 seq2seq 模型最新进展的搜索空间,开发了一种名为渐进式动态障碍(progressive dynamic hurdle,PDH)的方法,借助该方法可以直接在计算要求较高的 WMT 2014 英德翻译任务上执行搜索。该搜索得到了一种名为 Evolved Transformer 的新架构,在四个成熟的语言任务(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十亿词语言模型基准(LM1B))上的表现均优于原版 Transformer。在用大型模型进行的实验中,Evolved Transformer 的效率(FLOPS)是 Transformer 的两倍,而且质量没有损失。在更适合移动设备的小型模型(参数量为 7M)中,Evolved Transformer 的 BLEU 值高出 Transformer 0.7。
论文:The Evolved Transformer

论文链接:https://arxiv.org/abs/1901.11117
摘要:近期研究强调了 Transformer 在解决序列任务中的优势。同时,神经架构搜索已经发展到可以超越人类设计的模型。本文的目的在于利用架构搜索找到更好的 Transformer 架构。我们首先根据前馈序列模型的最新进展构建了一个大的搜索空间,然后运行进化架构搜索,用 Transformer 为我们的初始种群(initial population)排序。为了在计算成本高昂的 WMT 2014 英德翻译任务上有效地运行此搜索,我们开发了渐进式动态障碍方法,该方法允许我们将更多的资源动态分配给更有潜力的候选模型。我们在实验中发现的架构——Evolved Transformer——在四个公认的语言任务(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十亿词语言模型基准(LM1B))上的表现都优于 Transformer。在用大型模型进行的实验中,Evolved Transformer 的效率(FLOPS)是 Transformer 的两倍,而且质量没有损失。在更适合移动设备的小型模型(参数量为 7M)中,Evolved Transformer 在 WMT’14 英德任务中的 BLEU 值高出 Transformer 0.7。
方法
研究者采用了基于进化的架构搜索,因为该方法简单,而且已经被证明在资源有限的情况下比强化学习更加高效(Real et al., 2019)。他们使用与 Real 等人(2019)所用算法相同的锦标赛选择算法算法,但省略了老式的正则化。算法大致描述如下。
锦标赛选择进化架构搜索首先定义描述神经网络架构的基因编码;然后,从基因编码空间中随机采样创建一个初始种群来创建个体。基于这些个体在目标任务上描述的神经网络的训练为它们分配适应度(fitness),再在任务的验证集上评估它们的表现。然后,研究者对种群进行重复采样,以产生子种群,从中选择适应度最高的个体作为亲本(parent)。被选中的亲本使自身基因编码发生突变(编码字段随机改变为不同的值)以产生子模型。然后,通过在目标任务上的训练和评估,像对待初始种群一样为这些子模型分配适应度。当适应度评估结束时,再次对种群进行抽样,子种群中适应度最低的个体被移除,也就是从种群中移除。然后,新评估的子模型被添加到种群中,取代被移除的个体。这一过程会重复进行,直到种群中出现具备高度适应度的个体,这在本文中表示性能良好的架构。
结果
在此章节中,我们首先对自己的搜索方法、动态进化障碍以及其他进化搜索方法的表现做了基准测试。我们然后设置了 Evolved Transformer 以及与 Transormer 比对的基准。






Comments