
人工智能研究在过去二十年中发展到了多远?全球信息分析公司Elsevier分享其调查结果。
Author Archive
词嵌入 | Word embedding

想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
文本表示(Representation)
文本是一种非结构化的数据信息,是不可以直接被计算的。
文本表示的作用就是将这些非结构化的信息转化为结构化的信息,这样就可以针对文本信息做计算,来完成我们日常所能见到的文本分类,情感判断等任务。

文本表示的方法有很多种,下面只介绍 3 类方式:
- 独热编码 | one-hot representation
- 整数编码
- 词嵌入 | word embedding

独热编码 | one-hot representation
假如我们要计算的文本中一共出现了4个词:猫、狗、牛、羊。向量里每一个位置都代表一个词。所以用 one-hot 来表示就是:
猫:[1,0,0,0]
狗:[0,1,0,0]
牛:[0,0,1,0]
羊:[0,0,0,1]

但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
整数编码
这种方式也非常好理解,用一种数字来代表一个词,上面的例子则是:
猫:1
狗:2
牛:3
羊:4
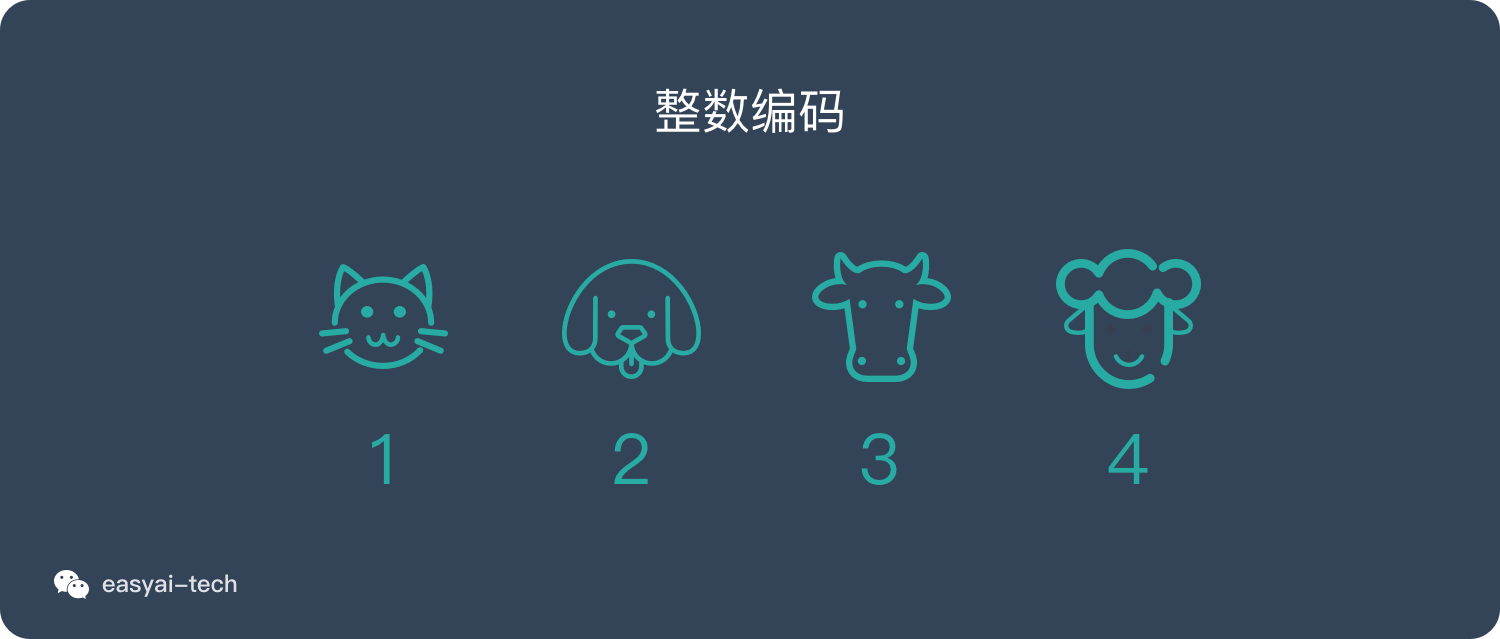
将句子里的每个词拼起来就是可以表示一句话的向量。
整数编码的缺点如下:
- 无法表达词语之间的关系
- 对于模型解释而言,整数编码可能具有挑战性。
什么是词嵌入 | word embedding?
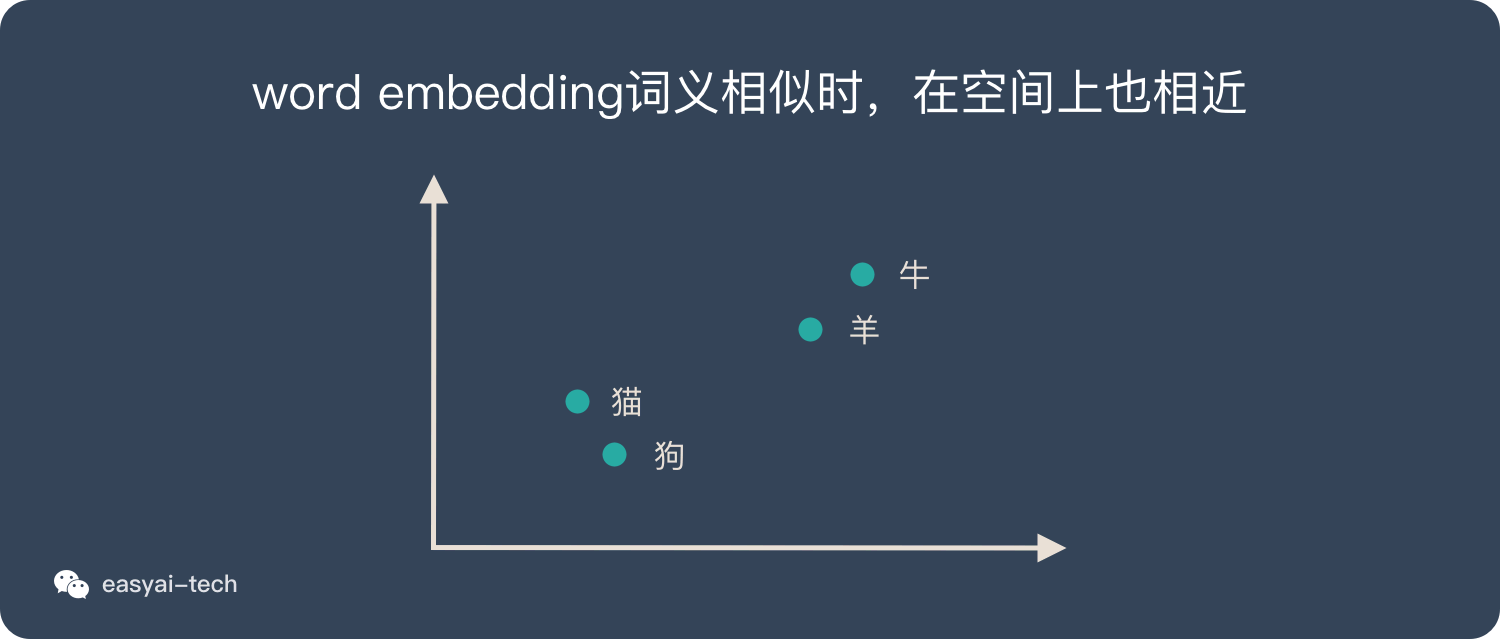
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,不过他有更多的优点。
词嵌入并不特指某个具体的算法,跟上面2种方式相比,这种方法有几个明显的优势:
- 他可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。
再回顾上面的例子:
2 种主流的 word embedding 算法

Word2vec
这是一种基于统计方法来获得词向量的方法,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
这种算法有2种训练模式:
- 通过上下文来预测当前词
- 通过当前词来预测上下文
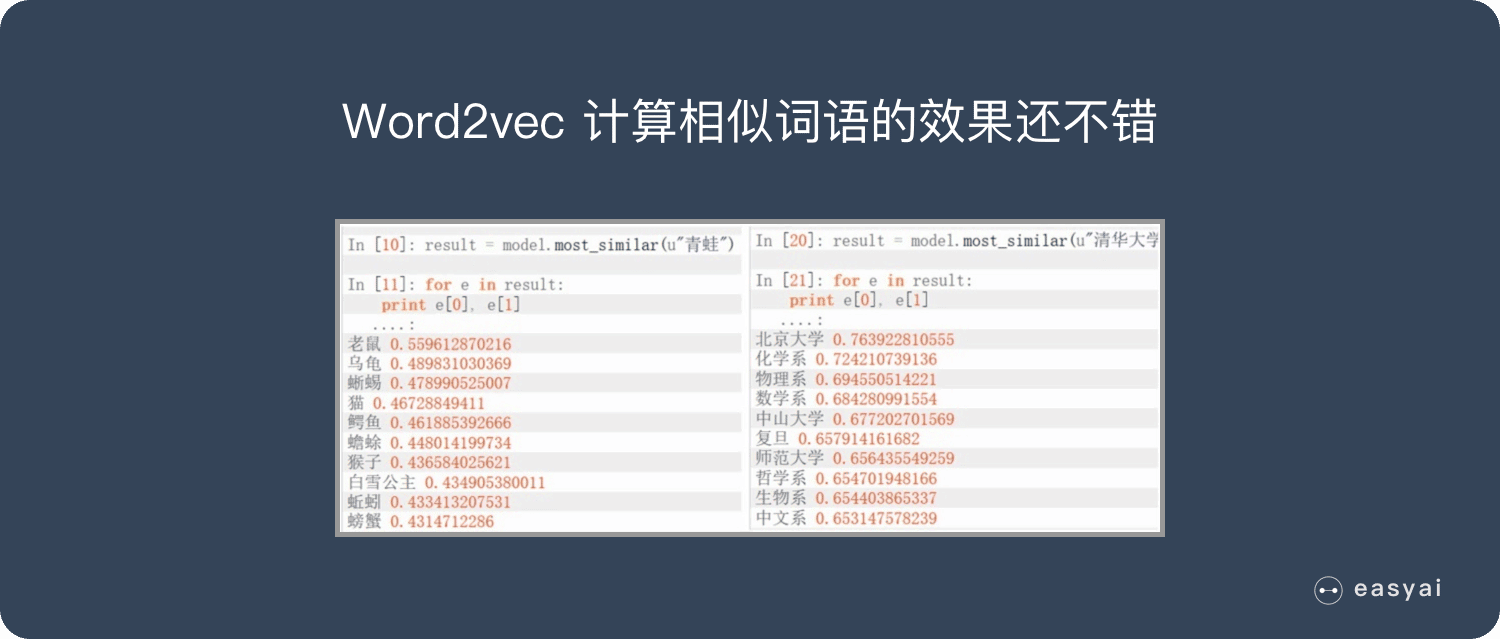
想要详细了解 Word2vec,可以看看这篇文章:《一文看懂 Word2vec(基本概念+2种训练模型+5个优缺点)》
GloVe
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
想要了解 GloVe 的 三步实现方式、训练方法、和 w2c 的比较。可以看看这篇文章:《GloVe详解》
百度百科和维基百科
百度百科版本
词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。 从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。
生成这种映射的方法包括神经网络,单词共生矩阵的降维,概率模型,可解释的知识库方法,和术语的显式表示 单词出现的背景。
当用作底层输入表示时,单词和短语嵌入已经被证明可以提高NLP任务的性能,例如语法分析和情感分析。
维基百科版本
Word embedding 是自然语言处理中的重要环节,它是一些语言处理模型的统称,并不具体指某种算法或模型。Word embedding 的任务是把词转换成可以计算的向量 。从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。
生成这种映射的方法包括神经网络,单词共生矩阵的降维,概率模型,可解释的知识库方法,和术语的显式表示单词出现的上下文。
当用作底层输入表示时,单词和短语嵌入已经被证明可以提高NLP任务的性能,例如句法分析和情感分析。
Word2vec

Word2vec 是 Word Embedding 方式之一,属于 NLP 领域。他是将词转化为「可计算」「结构化」的向量的过程。本文将讲解 Word2vec 的原理和优缺点。
这种方式在 2018 年之前比较主流,但是随着 BERT、GPT2.0 的出现,这种方式已经不算效果最好的方法了。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 Word2vec ?
什么是 Word Embedding ?
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
这一步解决的是”将现实问题转化为数学问题“,是人工智能非常关键的一步。
了解更多,可以看这篇文章:《一文看懂词嵌入 word embedding(与其他文本表示比较+2种主流算法)》

将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。因为在后续的任务中会直接用到这个词向量。
什么是 Word2vec ?
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec 在整个 NLP 里的位置可以用下图表示:
在 Word2vec 出现之前,已经有一些 Word Embedding 的方法,但是之前的方法并不成熟,也没有大规模的得到应用。
下面会详细介绍 Word2vec 的训练模型和用法。
Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
- Negative Sample(负采样)
- Hierarchical Softmax
具体加速方法就不详细讲解了,感兴趣的可以自己查找资料。
Word2vec 的优缺点
需要说明的是:Word2vec 是上一代的产物(18 年之前), 18 年之后想要得到最好的效果,已经不使用 Word Embedding 的方法了,所以也不会用到 Word2vec。
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中
缺点:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化

百度百科
百度百科版本
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
语音合成标记语言-SSML丨Speech Synthesis Markup Language
小白版本
中学的时候参加朗诵比赛,老师教我在文字上“做记号”,把所有的停顿、重音、轻音、语速节奏等全都在文字上标记出来,这样再读就非常简单了。

而语音合成(TTS)的过程其实也是朗读的过程,机器若要实现拟人化的朗读发音,其实也可以给它提前把文字做上标记,用到的就是语音合成标记语言(SSML)。
除了进行朗读技巧的标记,SSML还可以对有歧义的文本进行标记,以确定读法,例如:
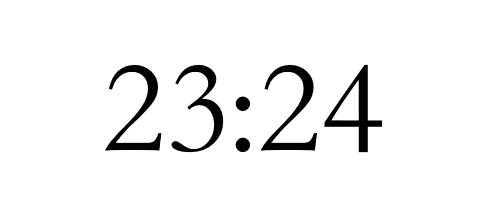
表示时间时可读为:
- “二十三点二十四分”
- “晚上十一点二十四分”
表示比分时则读为:
- “二十三比二十四”
如果还要在特定环境下需要在语句朗读时加入BGM,也可通过SSML实现定制化的TTS。
百度百科版本
语音合成标记语言(SSML:Speech Synthesis Markup Language),它是W3C的语音接口框架的一部分,是关于语音应用和在万维网上构建语音应用的一套规范,通过SSML,人们可以更多的通过移动电话、桌面计算机和其他设备来聆听合成语音,把计算和信息传输延伸到全球每个角落。
SSML是另一种在构建基于语音浏览器技术的VUI时令人迷惑的一部分。SSML能通过语音合成引擎界面推动便携性的发展,这个界面由不同供应商以统一方式提供。SSML是另一种W3C标准,它基于JSML(JSpeech Synthesis Markup Language,Java语音合成置标语言)。SSML根据它试图解决的问题更易于理解。
查看详情
维基百科版本
语音合成标记语言(SSML)是一种XML为基础的标记语言用于语音合成应用中。这是一个推荐W3C的语音浏览器工作组。SSML通常嵌入在VoiceXML脚本中以驱动交互式电话系统。但是,它也可以单独使用,例如用于创建有声读物。对于桌面应用程序,其他标记语言很受欢迎,包括Apple的嵌入式语音命令和Microsoft的SAPI Text to Speech(TTS)标记,也是一种XML语言。
查看详情
扩展阅读
依存句法分析-Constituency-based parse trees
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是句法分析?
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析。
语义分析通常以句法分析的输出结果作为输入以便获得更多的指示信息。根据句法结构的表示形式不同,最常见的句法分析任务可以分为以下三种:
句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。
深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar,LTAG)、词汇功能文法(Lexical Functional Grammar,LFG)、组合范畴文法(Combinatory Categorial Grammar,CCG)等,对句子进行深层的句法以及语义分析。
什么是依存句法分析?
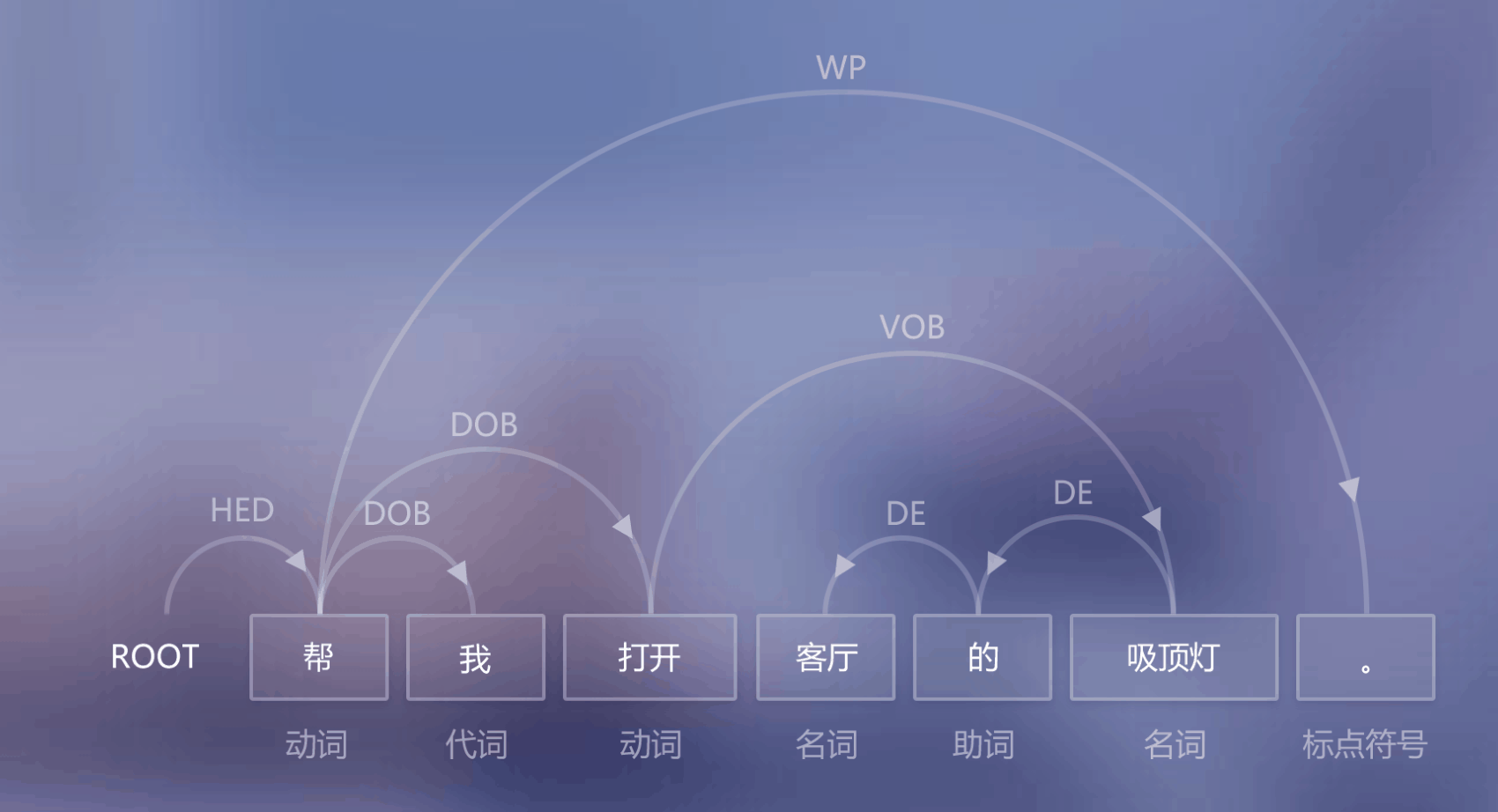
维基百科是这样描述的:The dependency-based parse trees of dependency grammars see all nodes as terminal, which means they do not acknowledge the distinction between terminal and non-terminal categories. They are simpler on average than constituency-based parse trees because they contain fewer nodes.
依存句法是由法国语言学家L.Tesniere最先提出。它将句子分析成一颗依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。
在自然语言处理中,用词与词之间的依存关系来描述语言结构的框架称为依存语法(dependence grammar),又称从属关系语法。利用依存句法进行句法分析是自然语言理解的重要技术之一。
相关重要概念
依存句法认为“谓语”中的动词是一个句子的中心,其他成分与动词直接或间接地产生联系。
依存句法理论中,“依存”指词与词之间支配与被支配的关系,这种关系不是对等的,这种关系具有方向。确切的说,处于支配地位的成分称之为支配者(governor,regent,head),而处于被支配地位的成分称之为从属者(modifier,subordinate,dependency)。
依存语法本身没有规定要对依存关系进行分类,但为了丰富依存结构传达的句法信息,在实际应用中,一般会给依存树的边加上不同的标记。
依存语法存在一个共同的基本假设:句法结构本质上包含词和词之间的依存(修饰)关系。一个依存关系连接两个词,分别是核心词(head)和依存词(dependent)。依存关系可以细分为不同的类型,表示两个词之间的具体句法关系。
常见方法
基于规则的方法: 早期的基于依存语法的句法分析方法主要包括类似CYK的动态规划算法、基于约束满足的方法和确定性分析策略等。
基于统计的方法:统计自然语言处理领域也涌现出了一大批优秀的研究工作,包括生成式依存分析方法、判别式依存分析方法和确定性依存分析方法,这几类方法是数据驱动的统计依存分析中最为代表性的方法。
基于深度学习的方法:近年来,深度学习在句法分析课题上逐渐成为研究热点,主要研究工作集中在特征表示方面。传统方法的特征表示主要采用人工定义原子特征和特征组合,而深度学习则把原子特征(词、词性、类别标签)进行向量化,在利用多层神经元网络提取特征。
依存分析器的性能评价
通常使用的指标包括:无标记依存正确率(unlabeled attachment score,UAS)、带标记依存正确率(labeled attachment score, LAS)、依存正确率(dependency accuracy,DA)、根正确率(root accuracy,RA)、完全匹配率(complete match,CM)等。这些指标的具体意思如下:
- 无标记依存正确率(UAS):测试集中找到其正确支配词的词(包括没有标注支配词的根结点)所占总词数的百分比。
- 带标记依存正确率(LAS):测试集中找到其正确支配词的词,并且依存关系类型也标注正确的词(包括没有标注支配词的根结点)占总词数的百分比。
- 依存正确率(DA):测试集中找到正确支配词非根结点词占所有非根结点词总数的百分比。
- 根正确率(RA):有二种定义,一种是测试集中正确根结点的个数与句子个数的百分比。另一种是指测试集中找到正确根结点的句子数所占句子总数的百分比。
- 完全匹配率(CM):测试集中无标记依存结构完全正确的句子占句子总数的百分比。
相关数据集
Penn Treebank:Penn Treebank是一个项目的名称,项目目的是对语料进行标注,标注内容包括词性标注以及句法分析。
SemEval-2016 Task 9中文语义依存图数据:http://ir.hit.edu.cn/2461.html
CoNLL经常开放句法分析的学术评测,比如:
相关工具推荐
StanfordCoreNLP
斯坦福大学开发的,提供依存句法分析功能。
HanLP
HanLP是一系列模型与算法组成的NLP工具包。提供了中文依存句法分析功能。
SpaCy
工业级的自然语言处理工具,遗憾的是目前不支持中文。
FudanNLP
复旦大学自然语言处理实验室开发的中文自然语言处理工具包,包含信息检索: 文本分类、新闻聚类;中文处理: 中文分词、词性标注、实体名识别、关键词抽取、依存句法分析、时间短语识别;结构化学习: 在线学习、层次分类、聚类。
本文转自公众号 AI小白入门 ,原文地址
TensorFlow 2.0 的重生
TensorFlow 2.0 带来了大量改变。谷歌工程师 Cassie Kozyrkov 表示:之前的 TensorFlow 已死,而新版 TensorFlow 使它获得重生。
使用Python进行强化学习的编程方法
强化是一类机器学习,其中代理通过执行动作来学习如何在环境中行为,从而绘制直觉并查看结果。在本文中,您将学习如何理解和设计强化学习问题并在Python中解决
强化学习在现实世界中的应用
如果您是公司的决策者,我希望这篇文章足以说服您重新思考您的业务,看看是否可以使用强化学习
超级智能的致命赌博
随着人类的命运处于平衡状态,即使是小风险也需要采取严肃的行动
机器学习可以给营销人员带来的5大优势
以营销为例。今天的营销人员正在努力向客户传递相关信息。虽然人类无法单独大规模地与大量客户进行通信,但机器可以。不确定在实践中看起来像什么?在本文中,我将解释机器学习在营销中的五个关键用途。