
與其他領域相比,機器學習/人工智能現在似乎有更高頻率的超級有趣的發展。
Author Archive
關於文本預處理(英文),看這一篇就夠了
文本預處理是一個被嚴重忽視的話題。本文將介紹文本預處理的真正含義,文本預處理的不同方法,以及估計可能需要多少預處理的方法。
自然語言生成 – Natural-language generation | NLG

自然語言生成 – NLG 是 NLP 的重要組成部分,他的主要目的是降低人類和機器之間的溝通鴻溝,將非語言格式的數據轉換成人類可以理解的語言格式。
本文除了介紹 NLG 的基本概念,還會介紹 NLG 的3個 Level、6個步驟和3個典型的應用。
想要了解更多 NLP 相關的內容,請訪問 NLP專題 ,免費提供59頁的NLP文檔下載。
訪問 NLP 專題,下載 59 頁免費 PDF
什麼是 NLG?
NLG 是 NLP 的一部分

NLP = NLU + NLG
自然語言生成 – NLG 是 NLP 的重要組成部分。NLU 負責理解內容,NLG 負責生成內容。
以智能音箱為例,當用戶說「幾點了?」,首先需要利用 NLU 技術判斷用戶意圖,理解用戶想要什麼,然後利用 NLG 技術說出「現在是6點50分」。
自然語言生成 – NLG 是什麼?

NLG 是為了跨越人類和機器之間的溝通鴻溝,將非語言格式的數據轉換成人類可以理解的語言格式,如文章、報告等。
自然語言生成 – NLG 有2種方式:
- text – to – text:文本到語言的生成
- data – to – text :數據到語言的生成
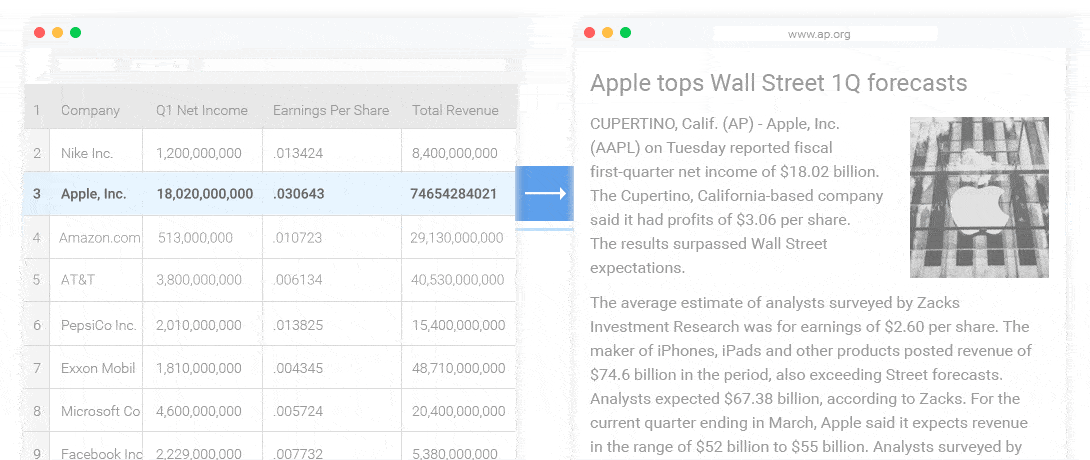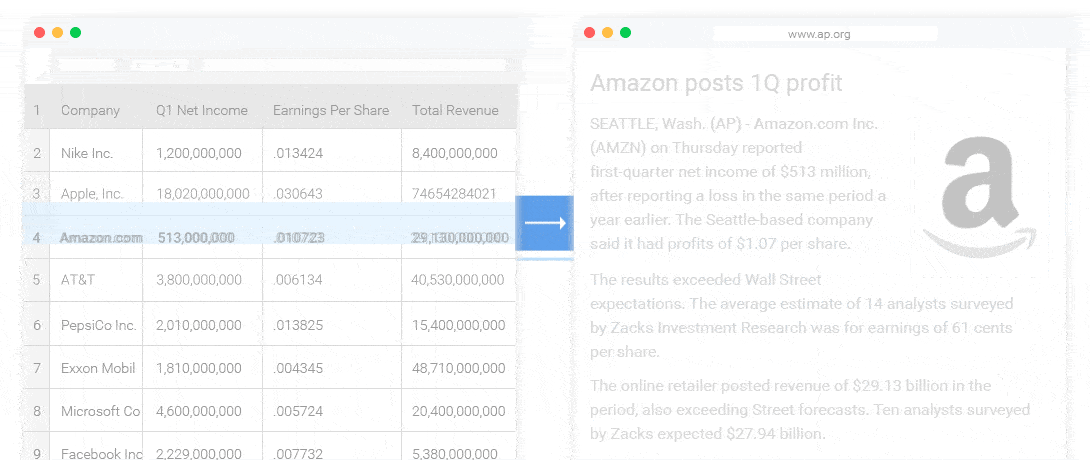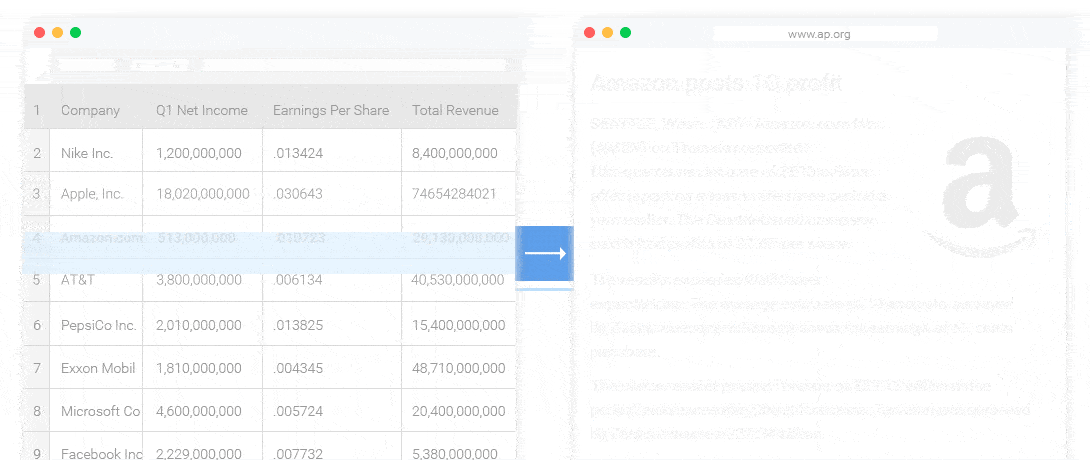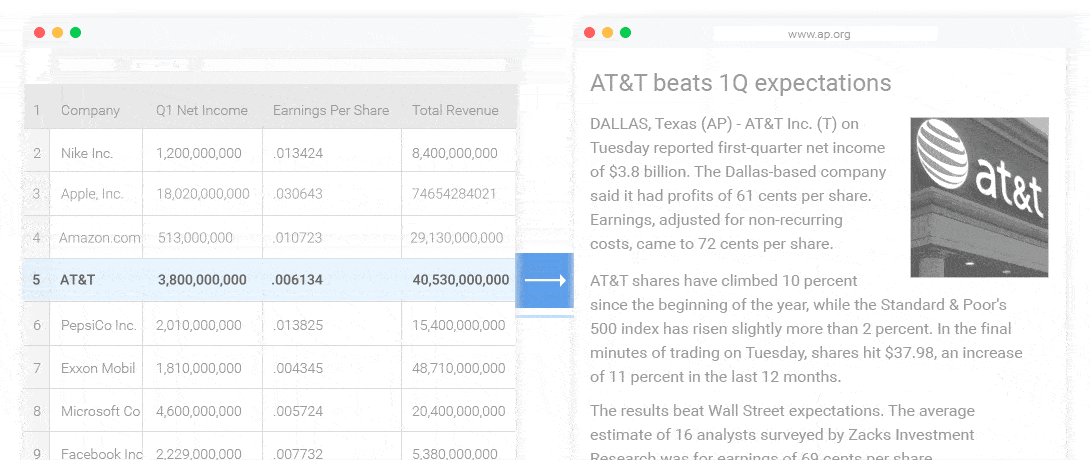
NLG 的3個 Level

簡單的數據合併:自然語言處理的簡化形式,這將允許將數據轉換為文本(通過類似Excel的函數)。為了關聯,以郵件合併(MS Word mailmerge)為例,其中間隙填充了一些數據,這些數據是從另一個源(例如MS Excel中的表格)中檢索的。
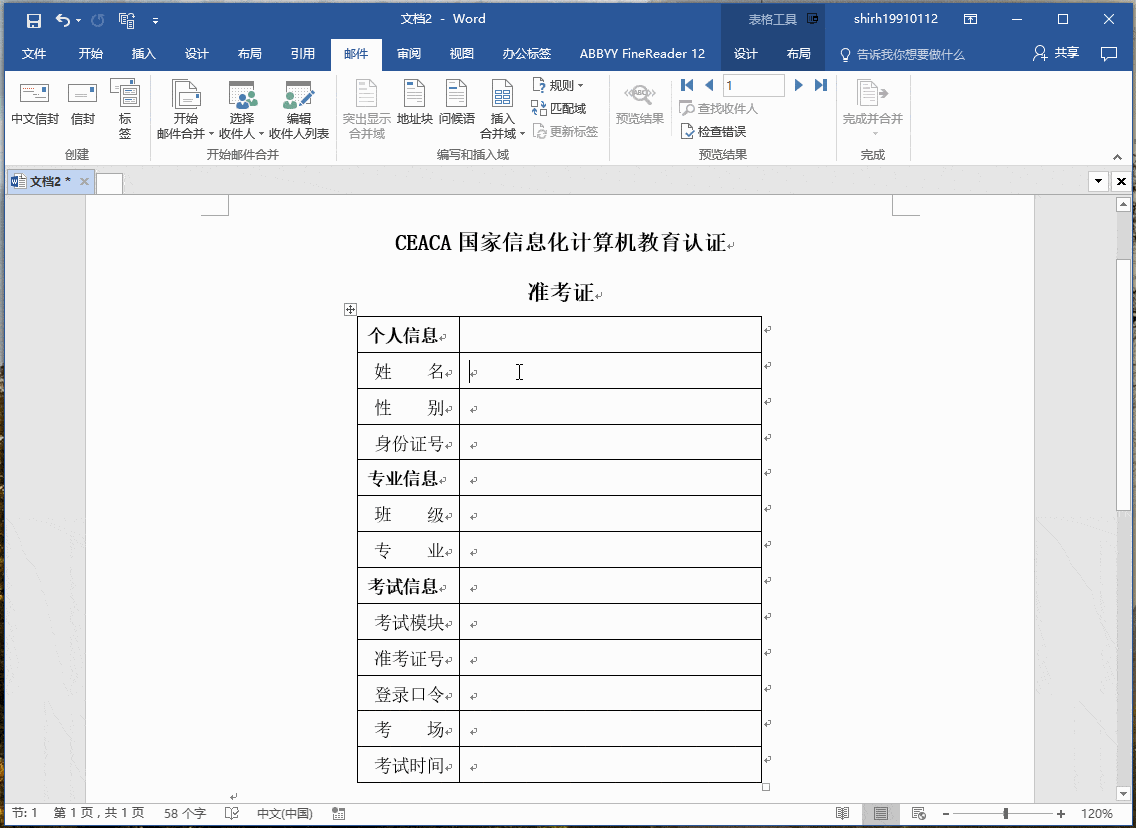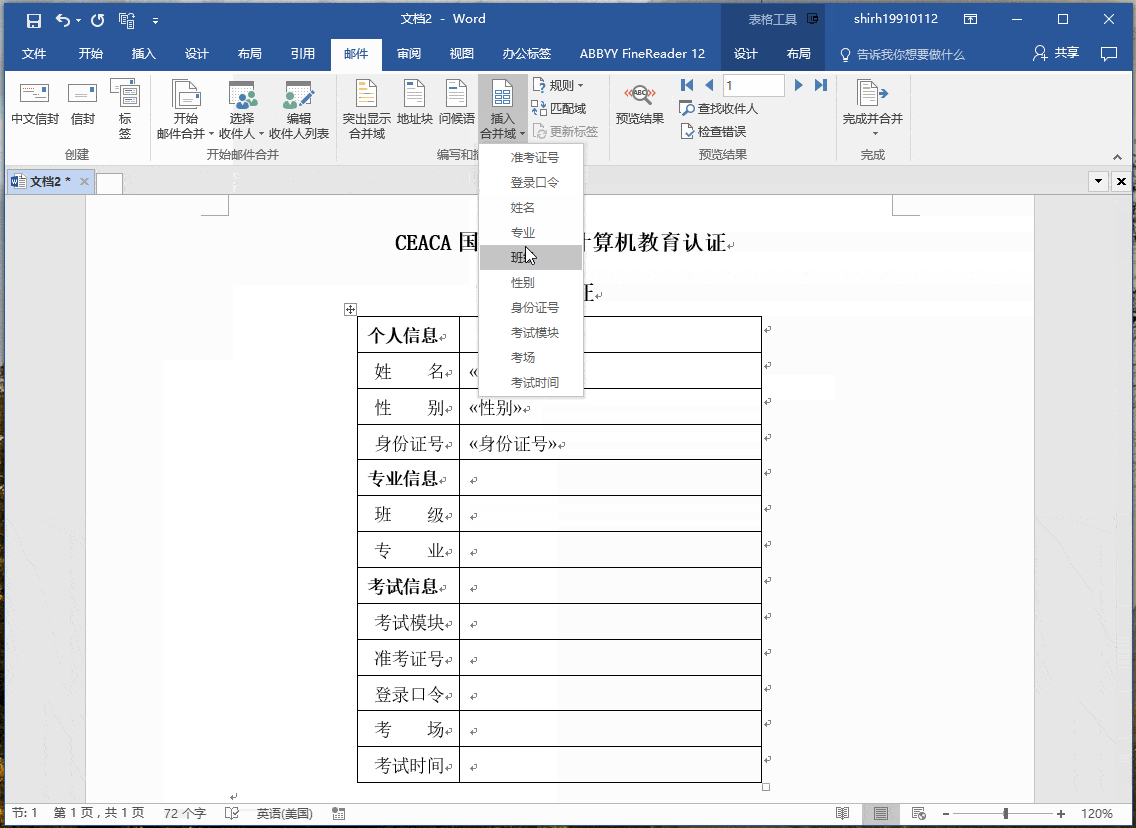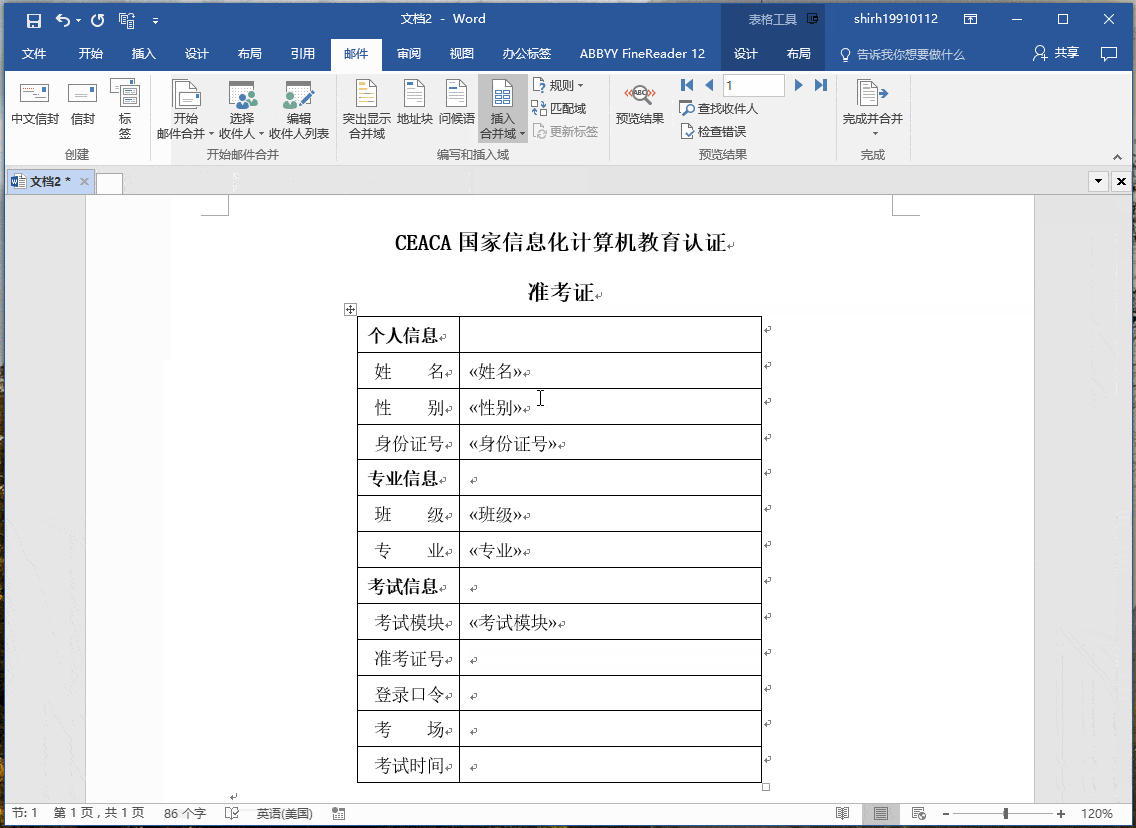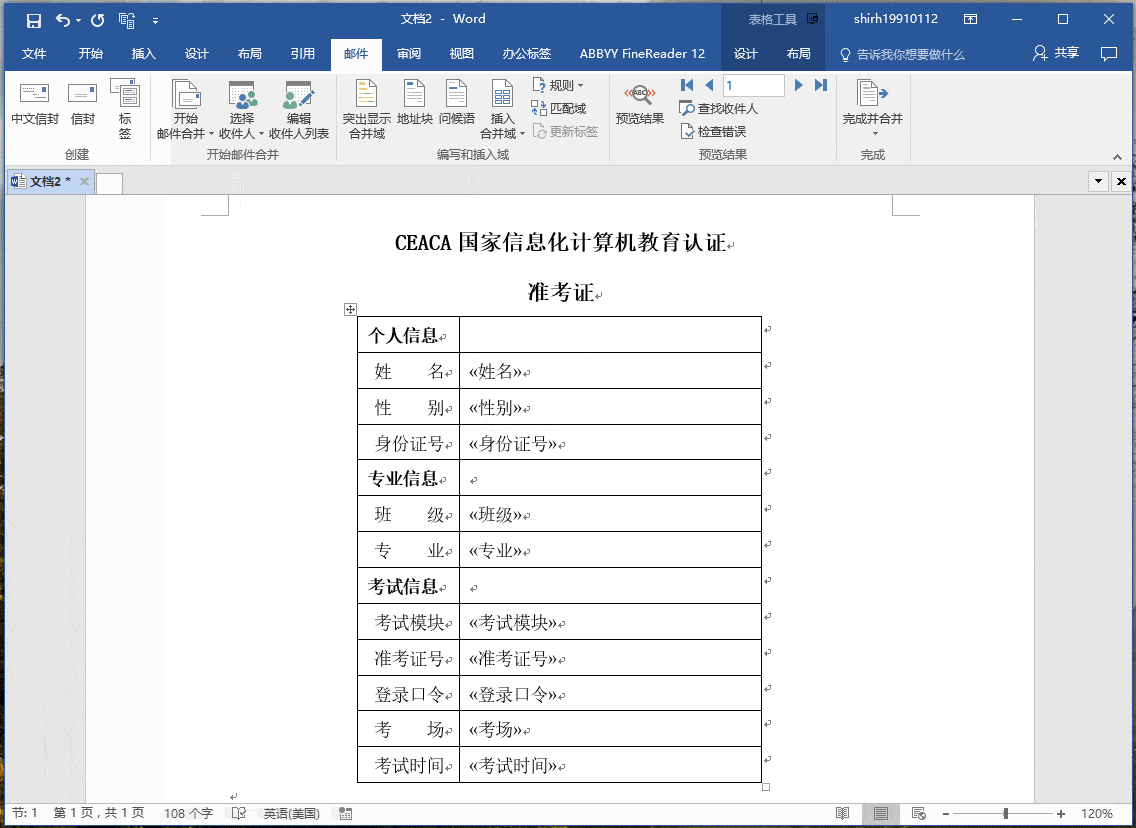
模板化的 NLG :這種形式的NLG使用模板驅動模式來顯示輸出。以足球比賽得分板為例。數據動態地保持更改,並由預定義的業務規則集(如if / else循環語句)生成。

高級 NLG :這種形式的自然語言生成就像人類一樣。它理解意圖,添加智能,考慮上下文,並將結果呈現在用戶可以輕鬆閱讀和理解的富有洞察力的敘述中。
NLG 的6個步驟

第一步:內容確定 – Content Determination
作為第一步,NLG 系統需要決定哪些信息應該包含在正在構建的文本中,哪些不應該包含。通常數據中包含的信息比最終傳達的信息要多。
第二步:文本結構 – Text Structuring
確定需要傳達哪些信息後,NLG 系統需要合理的組織文本的順序。例如在報道一場籃球比賽時,會優先表達「什麼時間」「什麼地點」「哪2支球隊」,然後再表達「比賽的概況」,最後表達「比賽的結局」。
第三步:句子聚合 – Sentence Aggregation
不是每一條信息都需要一個獨立的句子來表達,將多個信息合併到一個句子里表達可能會更加流暢,也更易於閱讀。
第四步:語法化 – Lexicalisation
當每一句的內容確定下來後,就可以將這些信息組織成自然語言了。這個步驟會在各種信息之間加一些連接詞,看起來更像是一個完整的句子。
第五步:參考表達式生成 – Referring Expression Generation|REG
這個步驟跟語法化很相似,都是選擇一些單詞和短語來構成一個完整的句子。不過他跟語法化的本質區別在於「REG需要識別出內容的領域,然後使用該領域(而不是其他領域)的詞彙」。
第六步:語言實現 – Linguistic Realisation
最後,當所有相關的單詞和短語都已經確定時,需要將它們組合起來形成一個結構良好的完整句子。
NLG 的3種典型應用
NLG 的不管如何應用,大部分都是下面的3種目的:
- 能夠大規模的產生個性化內容
- 幫助人類洞察數據,讓數據更容易理解
- 加速內容生產
下面給大家列一些比較典型的應用:

自動寫新聞
某些領域的新聞是有比較明顯的規則的,比如體育新聞。目前很多新聞已經藉助 NLG 來完成了。
聊天機械人
大家了解聊天機械人都是從 Siri 開始的,最近幾年又出現了智能音箱的熱潮。
除了大家日常生活中很熟悉的領域,客服工作也正在被機械人替代,甚至一些電話客服也是機械人。

BI 的解讀和報告生成
幾乎各行各業都有自己的數據統計和分析工具。這些工具可以產生各式各樣的圖表,但是輸出結論和觀點還是需要依賴人。NLG 的一個很重要的應用就是解讀這些數據,自動的輸出結論和觀點。(如下圖所示)

總結
自然語言生成 – NLG 是 NLP 的重要組成部分,他的主要目的是降低人類和機器之間的溝通鴻溝,將非語言格式的數據轉換成人類可以理解的語言格式。
NLG 的3個level:
- 簡單的數據合併
- 模塊化的 NLG
- 高級 NLG
NLG 的6個步驟:
- 內容確定 – Content Determination
- 文本結構 – Text Structuring
- 句子聚合 – Sentence Aggregation
- 語法化 – Lexicalisation
- 參考表達式生成 – Referring Expression Generation|REG
- 語言實現 – Linguistic Realisation
NLG 應用的3個目的:
- 能夠大規模的產生個性化內容
- 幫助人類洞察數據,讓數據更容易理解
- 加速內容生產
NLG 的3個典型應用:
- 自動寫新聞
- 聊天機械人
- BI 的解讀和報告生成
百度百科版本+維基百科
百度百科版本
自然語言生成是研究使計算機具有人一樣的表達和寫作的功能。即能夠根據一些關鍵信息及其在機器內部的表達形式,經過一個規划過程,來自動生成一段高質量的自然語言文本。
自然語言處理包括自然語言理解和自然語言生成。自然語言生成是人工智能和計算語言學的分支,相應的語言生成系統是基於語言信息處理的計算機模型,其工作過程與自然語言分析相反,是從抽象的概念層次開始,通過選擇並執行一定的語義和語法規則來生成文本。
維基百科版本
自然語言生成(NLG)是語言技術的一個方面,側重於從結構化數據或結構化表示(如知識庫或邏輯形式)生成自然語言。當這種形式表徵被解釋為心理表徵的模型時,心理語言學家更喜歡語言生成這個術語。
可以說一個NLG系統就像一個翻譯器將數據轉換成自然語言表示。然而,由於自然語言的固有表現力,產生最終語言的方法與編譯器的方法不同。NLG已經存在了很長時間,但商業NLG技術最近才被廣泛使用。
擴展閱讀
從基於規則到深度學習,NLP 技術進階三部曲
我們將快速介紹NLP中的3種主要技術方法,以及我們如何使用它們來構建出色的機器!
AI 將如何改寫我們的生活
關於機械人會如何改變我們的生活耳朵一直都在科幻小說中的主食了幾十年。在20世紀40年代,人類和人工智能之間的廣泛互動似乎仍然遙遙無期,艾薩克·阿西莫夫(Isaac Asimov)提出了他着名的「機械人三法則」(Three Laws of Robotics),旨在防止機械人傷害我們。
MirrorGAN出世!浙大等提出文本-圖像新框架,刷新COCO紀錄
浙大、悉尼大學等高校研究員提出MirrorGAN,作為全局-局部注意和語義保持的文本-圖像-文本框架,解決文本描述和視覺內容之間的語義一致性問題,並在COCO數據集上刷新了記錄。
Google手寫字符識別的新進展
15年時Google曾經推出了支持82種語言的手寫輸入,並在去年升級為100種語言。但隨着機器學習的迅速發展,研究人員也在不斷重構着以往的方法為用戶帶來更快更準的體驗。
對比復現34個預訓練模型,PyTorch和Keras你選誰?
初學者該用什麼樣的 DL 架構?當然是越簡單越好、訓練速度越快越好、測試準確率越高越好!那麼我們到底該選擇 PyTorch 還是 Keras 呢?
Q-Learning
什麼是 Q-Learning ?
Q學習是強化學習中基於價值的學習算法。
假設機械人必須越過迷宮併到達終點。有地雷,機械人一次只能移動一個地磚。如果機械人踏上礦井,機械人就死了。機械人必須在儘可能短的時間內到達終點。
得分/獎勵系統如下:
- 機械人在每一步都失去1點。這樣做是為了使機械人採用最短路徑並儘可能快地到達目標。
- 如果機械人踩到地雷,則點損失為100並且遊戲結束。
- 如果機械人獲得動力⚡️,它會獲得1點。
- 如果機械人達到最終目標,則機械人獲得100分。
現在,顯而易見的問題是:我們如何訓練機械人以最短的路徑到達最終目標而不踩礦井?

那麼,我們該如何解決這個問題呢?
什麼是 Q-Table ?
Q-Table只是一個簡單查找表的奇特名稱,我們計算每個州的最大預期未來獎勵。基本上,這張表將指導我們在每個州採取最佳行動。

每個非邊緣區塊將有四個動作數。當機械人處於某種狀態時,它可以向上或向下或向右或向左移動。
所以,讓我們在Q-Table中對這個環境進行建模。
在Q表中,列是動作,行是狀態。

每個Q表得分將是機械人在該狀態下採取該行動時將獲得的最大預期未來獎勵。這是一個迭代過程,因為我們需要在每次迭代時改進Q-Table。
但問題是:
- 我們如何計算Q表的值?
- 值是可用的還是預定義的?
為了學習Q表的每個值,我們使用Q-Learning算法。
Q-Learning 的數學依據
Q-Fuction
所述 Q-Fuction 使用Bellman方程和採用兩個輸入:狀態(小號)和動作(一個)。

使用上面的函數,我們得到表中單元格的Q值。
當我們開始時,Q表中的所有值都是零。
有一個更新值的迭代過程。當我們開始探索環境時,通過不斷更新表中的Q值, Q函數為我們提供了更好和更好的近似。
現在,讓我們了解更新是如何進行的。
Q-Learning 算法的過程詳解

每個彩色框都是一步。讓我們詳細了解每個步驟。
第1步:初始化Q表
我們將首先構建一個Q表。有n列,其中n =操作數。有m行,其中m =狀態數。我們將值初始化為0。


在我們的機械人示例中,我們有四個動作(a = 4)和五個狀態(s = 5)。所以我們將構建一個包含四列五行的表。
步驟2和3:選擇並執行操作
這些步驟的組合在不確定的時間內完成。這意味着此步驟一直運行,直到我們停止訓練,或者訓練循環停止,如代碼中所定義。
我們將根據Q-Table選擇狀態中的動作(a)。但是,如前所述,當劇集最初開始時,每個Q值都為0。
因此,現在探索和開發權衡的概念發揮作用。
我們將使用一種叫做epsilon貪婪策略的東西。
一開始,ε利率會更高。機械人將探索環境並隨機選擇動作。這背後的邏輯是機械人對環境一無所知。
隨着機械人探索環境,epsilon率降低,機械人開始利用環境。
在探索過程中,機械人逐漸變得更有信心估計Q值。
對於機械人示例,有四種操作可供選擇:向上,向下,向左和向右。 我們現在開始訓練 – 我們的機械人對環境一無所知。所以機械人選擇隨機動作,說對了。

我們現在可以使用Bellman方程更新Q值,使其處於開始和向右移動。
步驟4和5:評估
現在我們採取了行動並觀察了結果和獎勵。我們需要更新功能Q(s,a)。

在機械人遊戲的情況下,重申得分/獎勵結構是:
- 功率 = +1
- 我的 = -100
- 結束 = +100


我們將一次又一次地重複這一過程,直到學習停止。通過這種方式,Q表將會更新。
本文翻譯自《An introduction to Q-Learning: reinforcement learning》
維基百科版本
維基百科版本
Q -learning是一種無模型 強化學習算法。Q-learning的目標是學習一種策略,告訴代理在什麼情況下要採取什麼行動。它不需要環境的模型(因此內涵「無模型」),並且它可以處理隨機轉換和獎勵的問題,而不需要調整。
對於任何有限馬爾可夫決策過程(FMDP),Q -learning在從當前狀態開始的任何和所有後續步驟中最大化總獎勵的預期值的意義上找到最優的策略。[1] 在給定無限探索時間和部分隨機策略的情況下,Q- learning可以為任何給定的FMDP確定最佳動作選擇策略。「Q」命名返回用於提供強化的獎勵的函數,並且可以說代表在給定狀態下採取的動作的「質量」。
使用word2vec分析新聞標題並預測文章成功
文章標題的嵌入可以預測受歡迎程度嗎?我們可以從中了解情緒與股票之間的關係?word2vec可以幫助我們回答這些問題,等等。