
语音合成又称文语转换(Text toSpeech,TTS)技术,通过机械的、电子的方法产生人造语音。通俗的讲,语音合成技术就是赋予计算机像人一样可以自如说话的能力。
Author Archive
方兴未艾的语音合成技术与应用
让机器开口说话,则是人类千百年来的梦想。语音合成(Text To Speech),是人类不断探索、实现这一梦想的科学实践,也是受到这一梦想不断推动、不断提升的技术领域。
命名实体识别 – Named-entity recognition | NER

想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是命名实体识别?
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
命名实体识别的发展历史
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。

阶段 1:早期的方法,如:基于规则的方法、基于字典的方法
阶段 2:传统机器学习,如:HMM、MEMM、CRF
阶段 3:深度学习的方法,如:RNN – CRF、CNN – CRF
阶段 4:近期新出现的一些方法,如:注意力模型、迁移学习、半监督学习的方法
4类常见的实现方式
早期的命名实体识别方法基本都是基于规则的。之后由于基于大规模的语料库的统计方法在自然语言处理各个方面取得不错的效果之后,一大批机器学习的方法也出现在命名实体类识别任务。宗成庆老师在统计自然语言处理一书粗略的将这些基于机器学习的命名实体识别方法划分为以下几类:
有监督的学习方法:这一类方法需要利用大规模的已标注语料对模型进行参数训练。目前常用的模型或方法包括隐马尔可夫模型、语言模型、最大熵模型、支持向量机、决策树和条件随机场等。值得一提的是,基于条件随机场的方法是命名实体识别中最成功的方法。
半监督的学习方法:这一类方法利用标注的小数据集(种子数据)自举学习。
无监督的学习方法:这一类方法利用词汇资源(如WordNet)等进行上下文聚类。
混合方法:几种模型相结合或利用统计方法和人工总结的知识库。
值得一提的是,由于深度学习在自然语言的广泛应用,基于深度学习的命名实体识别方法也展现出不错的效果,此类方法基本还是把命名实体识别当做序列标注任务来做,比较经典的方法是LSTM+CRF、BiLSTM+CRF。
NER 的相关数据集
| 数据集 | 简要说明 | 访问地址 |
|---|---|---|
| 电子病例测评 | CCKS2017开放的中文的电子病例测评相关的数据 | 测评1 | 测评2 |
| 音乐领域 | CCKS2018开放的音乐领域的实体识别任务 | CCKS |
| 位置、组织、人… | 这是来自GMB语料库的摘录,用于训练分类器以预测命名实体,例如姓名,位置等。 | kaggle |
| 口语 | NLPCC2018开放的任务型对话系统中的口语理解评测 | NLPCC |
| 人名、地名、机构、专有名词 | 一家公司提供的数据集,包含人名、地名、机构名、专有名词 | boson |
相关工具推荐
| 工具 | 简介 | 访问地址 |
|---|---|---|
| Stanford NER | 斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练出来的。 | 官网 | GitHub 地址 |
| MALLET | 麻省大学开发的一个统计自然语言处理的开源包,其序列标注工具的应用中能够实现命名实体识别。 | 官网 |
| Hanlp | HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。 | 官网 | GitHub 地址 |
| NLTK | NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。 | 官网 | GitHub 地址 |
| SpaCy | 工业级的自然语言处理工具,遗憾的是不支持中文。 | 官网 | GitHub 地址 |
| Crfsuite | 可以载入自己的数据集去训练CRF实体识别模型。 | 文档 | GitHub 地址 |
本文转载自公众号 AI 小白入门,原文地址
扩展阅读
小i机器人收集数据和处理数据的方式
小i机器人是如何积累数据的?数据收集之后怎么处理?
【转】NLP技术落地为何这么难?里面有哪些坑?
CSDN主编下午茶邀请到了小i机器人技术委员会轮值主席兼首席架构师李波,与我们一起探讨了NLP技术落地的难点,以及如何降低开发者门槛的问题。
自然语言处理-Natural language processing | NLP

网络上有海量的文本信息,想要处理这些非结构化的数据就需要利用 NLP 技术。
本文将介绍 NLP 的基本概念,2大任务,4个典型应用和6个实践步骤。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
NLP 为什么重要?
“语言理解是人工智能领域皇冠上的明珠”
比尔·盖茨
在人工智能出现之前,机器智能处理结构化的数据(例如 Excel 里的数据)。但是网络中大部分的数据都是非结构化的,例如:文章、图片、音频、视频…

在非结构数据中,文本的数量是最多的,他虽然没有图片和视频占用的空间大,但是他的信息量是最大的。
为了能够分析和利用这些文本信息,我们就需要利用 NLP 技术,让机器理解这些文本信息,并加以利用。
什么是自然语言处理 – NLP
每种动物都有自己的语言,机器也是!
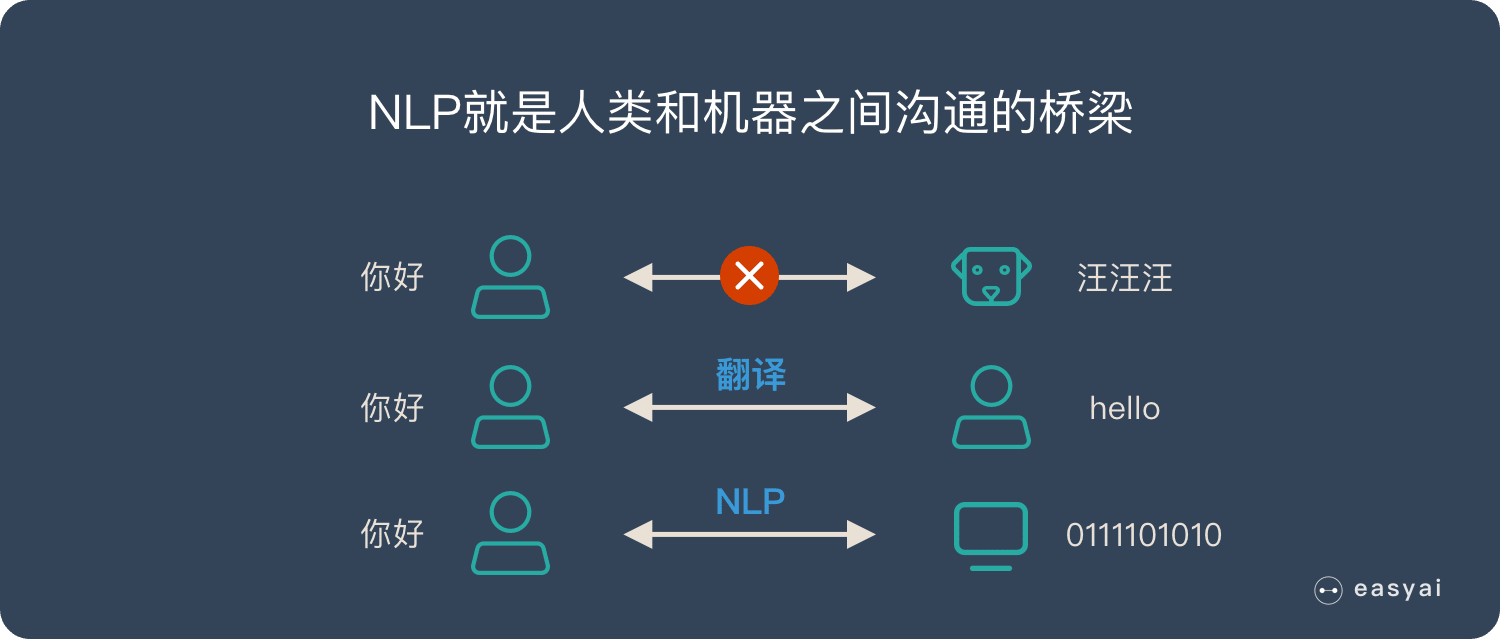
自然语言处理(NLP)就是在机器语言和人类语言之间沟通的桥梁,以实现人机交流的目的。
人类通过语言来交流,狗通过汪汪叫来交流。机器也有自己的交流方式,那就是数字信息。

不同的语言之间是无法沟通的,比如说人类就无法听懂狗叫,甚至不同语言的人类之间都无法直接交流,需要翻译才能交流。
而计算机更是如此,为了让计算机之间互相交流,人们让所有计算机都遵守一些规则,计算机的这些规则就是计算机之间的语言。
既然不同人类语言之间可以有翻译,那么人类和机器之间是否可以通过“翻译”的方式来直接交流呢?
NLP 就是人类和机器之间沟通的桥梁!
为什么是“自然语言”处理?
自然语言就是大家平时在生活中常用的表达方式,大家平时说的「讲人话」就是这个意思。
自然语言:我背有点驼(非自然语言:我的背部呈弯曲状)
自然语言:宝宝的经纪人睡了宝宝的宝宝(微博上这种段子一大把)
NLP 的2大核心任务
NLP 有2个核心的任务:
自然语言理解 – NLU|NLI
自然语言理解就是希望机器像人一样,具备正常人的语言理解能力,由于自然语言在理解上有很多难点(下面详细说明),所以 NLU 是至今还远不如人类的表现。

自然语言理解的5个难点:
- 语言的多样性
- 语言的歧义性
- 语言的鲁棒性
- 语言的知识依赖
- 语言的上下文
想要深入了解NLU,可以看看这篇文章《一文看懂自然语言理解-NLU(基本概念+实际应用+3种实现方式)》
自然语言生成 – NLG

NLG 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
NLG 的6个步骤:
- 内容确定 – Content Determination
- 文本结构 – Text Structuring
- 句子聚合 – Sentence Aggregation
- 语法化 – Lexicalisation
- 参考表达式生成 – Referring Expression Generation|REG
- 语言实现 – Linguistic Realisation
想要深入了解NLG,可以看看这篇文章《一文看懂自然语言生成 – NLG(6个实现步骤+3个典型应用)》
NLP 的5个难点

- 语言是没有规律的,或者说规律是错综复杂的。
- 语言是可以自由组合的,可以组合复杂的语言表达。
- 语言是一个开放集合,我们可以任意的发明创造一些新的表达方式。
- 语言需要联系到实践知识,有一定的知识依赖。
- 语言的使用要基于环境和上下文。
NLP 的4个典型应用

情感分析
互联网上有大量的文本信息,这些信息想要表达的内容是五花八门的,但是他们抒发的情感是一致的:正面/积极的 – 负面/消极的。
通过情感分析,可以快速了解用户的舆情情况。
聊天机器人
过去只有 Siri、小冰这些机器人,大家使用的动力并不强,只是当做一个娱乐的方式。但是最近几年智能音箱的快速发展让大家感受到了聊天机器人的价值。
而且未来随着智能家居,智能汽车的发展,聊天机器人会有更大的使用价值。
语音识别
语音识别已经成为了全民级的引用,微信里可以语音转文字,汽车中使用导航可以直接说目的地,老年人使用输入法也可以直接语音而不用学习拼音…
机器翻译
目前的机器翻译准确率已经很高了,大家使用 Google 翻译完全可以看懂文章的大意。传统的人肉翻译未来很可能会失业。
NLP 的 2 种途径、3 个核心步骤
NLP 可以使用传统的机器学习方法来处理,也可以使用深度学习的方法来处理。2 种不同的途径也对应着不同的处理步骤。详情如下:
方式 1:传统机器学习的 NLP 流程

- 语料预处理
- 中文语料预处理 4 个步骤(下文详解)
- 英文语料预处理的 6 个步骤(下文详解)
- 特征工程
- 特征提取
- 特征选择
- 选择分类器
方式 2:深度学习的 NLP 流程

- 语料预处理
- 中文语料预处理 4 个步骤(下文详解)
- 英文语料预处理的 6 个步骤(下文详解)
- 设计模型
- 模型训练
英文 NLP 语料预处理的 6 个步骤

- 分词 – Tokenization
- 词干提取 – Stemming
- 词形还原 – Lemmatization
- 词性标注 – Parts of Speech
- 命名实体识别 – NER
- 分块 – Chunking
中文 NLP 语料预处理的 4 个步骤

总结
自然语言处理(NLP)就是在机器语言和人类语言之间沟通的桥梁,以实现人机交流的目的。
NLP的2个核心任务:
- 自然语言理解 – NLU
- 自然语言生成 – NLG
NLP 的5个难点:
- 语言是没有规律的,或者说规律是错综复杂的。
- 语言是可以自由组合的,可以组合复杂的语言表达。
- 语言是一个开放集合,我们可以任意的发明创造一些新的表达方式。
- 语言需要联系到实践知识,有一定的知识依赖。
- 语言的使用要基于环境和上下文。
NLP 的4个典型应用:
- 情感分析
- 聊天机器人
- 语音识别
- 机器翻译
NLP 的6个实现步骤:
- 分词-tokenization
- 次干提取-stemming
- 词形还原-lemmatization
- 词性标注-pos tags
- 命名实体识别-ner
- 分块-chunking
百度百科版本+维基百科
百度百科版本
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。
维基百科版本
自然语言处理(NLP)是计算机科学,信息工程和人工智能的子领域,涉及计算机与人类(自然)语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。自然语言处理中的挑战通常涉及语音识别,自然语言理解和自然语言生成。
扩展阅读
【转】深度好文:2018年NLP应用和商业化调查报告
自然语言处理技术在商业化应用上到底是出现了什么问题?为何迟迟没有大的进步?解决问题的关键在哪里?
启发式算法 – Heuristic
百度百科版本
启发式算法(heuristic)是相对于最优化算法提出的。一个问题的最优算法求得该问题每个实例的最优解。
启发式算法可以这样定义:
一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。
现阶段,启发式算法以仿自然体算法为主,主要有蚁群算法、模拟退火法、神经网络等。
维基百科版本
在计算机科学,人工智能和数学优化中,启发式是一种技术,用于在经典方法太慢时更快地解决问题,或者用于在经典方法中找到近似解找不到任何确切的解决方案。这是通过交易速度的最佳性,完整性,准确性或精确度来实现的。
在某种程度上,它可以被认为是一种捷径。一个启发式的功能,也简称为启发,是一个功能是居替代搜索算法根据现有的资料,以决定跟随哪一个分支,在每个分支的一步。例如,它可能接近确切的解决方案。
梯度下降法 – Gradient descent
什么是梯度下降法?
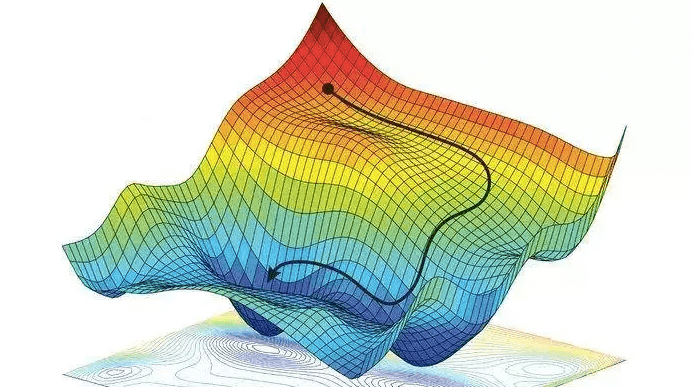
梯度下降算法的公式非常简单,”沿着梯度的反方向(坡度最陡)“是我们日常经验得到的,其本质的原因到底是什么呢?为什么局部下降最快的方向就是梯度的负方向呢?也许很多朋友还不太清楚。没关系,接下来我将以通俗的语言来详细解释梯度下降算法公式的数学推导过程。
我们以爬上山顶为例
假设我们位于一座山的山腰处,没有地图,并不知道如何到达山顶。于是决定走一步算一步,也就是每次沿着当前位置最陡峭最易上山的方向前进一步,然后继续沿下一个位置最陡方向前进一小步。这样一步一步走下去,一直走到觉得我们已经到了山顶。这里通过最陡峭的路径上山的方向就是梯度。
百度百科
梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
维基百科
梯度下降是用于找到函数最小值的一阶 迭代 优化 算法。为了使用梯度下降找到函数的局部最小值,需要采用与当前点处函数的梯度(或近似梯度)的负值成比例的步长。相反,如果采用与梯度的正值成比例的步长,则接近该函数的局部最大值 ; 然后将该过程称为梯度上升。
梯度下降也称为最陡下降。但是,梯度下降不应与最速下降的最速下降方法相混淆。