

自然语言处理或NLP是在 最热的今天AI的领域。NLP是人工智能的一个子领域,致力于使计算机能够理解和处理人类语言,使计算机更接近人类对语言的理解。
计算机非常适合处理标准化和结构化数据,如数据库表和财务记录。他们能够比我们人类更快地处理这些数据。但是我们人类不会在“结构化数据”中进行交流,也不会说二进制!我们使用单词进行交流,这是一种非结构化数据。
然而,我们的Mac和PC还没有人类对自然语言的直观理解。他们无法真正理解语言的真正含义。他们不像我们的朋友艾伦一样想到下面。

使用NLP算法,我们可以使我们的机器更接近人类更深层次的理解语言。今天,NLP使我们能够构建聊天机器人,语言翻译器和自动化系统等东西,向您推荐最好的Netflix电视节目。
我们将快速介绍NLP中的3种主要技术方法,以及我们如何使用它们来构建出色的机器!
阶段一:基于规则的方法
基于规则的方法是所有AI算法的最早类型。实际上,在我们考虑使用机器学习实现一切自动化之前,他们统一了计算机科学。基于规则的算法的本质很简单:
(1)定义一组规则,描述任务的所有不同方面,在本例中为语言
(2)指定这些规则的某种顺序或权重组合以作出最终决定
(3)以相同的方式将由该固定规则组成的公式应用于每个输入
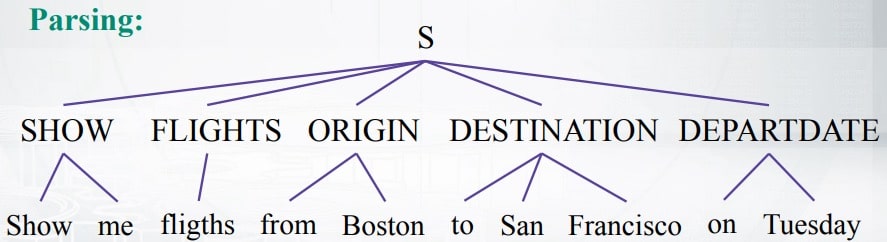
考虑上面的无上下文语法的例子。树的底部显示了“显示星期二从波士顿飞往旧金山的航班”的原始句子。
从人的角度来看,我们可以轻松定义一些规则来帮助机器理解这句话:
(1)只要我们看到“show”这个词,我们就知道我们会做一些视觉。因此,我们将使用标记SHOW标记单词“show”的每个匹配项以及与其一起使用的任何其他单词
(2)“航班”一词是名词; 我们用原始单词标记所有名词。所以“航班”和“航班”都将用FLIGHT标记
(3)“from”自然总是指某些东西最初 来自哪里,所以我们用ORIGIN标记它。我们使用DESTINATION标记的“to”和使用DEPARTDATE标记的“on”是相同的想法。
我们刚刚定义的这三条规则允许我们轻松理解这句话!
SHOW =呈现视觉效果
FLIGHTS =我们想要展示的东西
ORIGIN,DESTINATION,DEPARTDATE =我们想要展示的所有信息
基于规则的算法通常具有非常高的精度,因为规则是用户定义的。当人类用户定义规则时,我们知道它们是正确的。缺点是这种算法具有非常低的召回率; 我们无法定义世界上每一个城市!如果我们忘记将多伦多市放在我们的城市数据库中,那么根本不会被我们的算法检测到
经典机器学习
教授机器如何理解语言的另一种方法是构建经典的机器学习模型。我们的想法是使用一些用户定义的功能来表示一些“端到端”模型。与基于规则的方法类似,此类功能设计可能非常自然:
- 这个词是否大写?
- 这个词是一个城市吗?
- 前一个和下一个词是什么?
- 它是句子中的第一个,最后一个还是一些中间词?
将所有这些信息结合在一起可以让我们非常了解单词或短语的实际含义。
由于我们正在培训机器学习模型,因此我们所有的数据都需要在某个时刻表示为数字。资本与非资本可以表示为1.0和0.0; 对于城市名称也可以这样做 – 在我们的整个城市列表中使用单热编码的1和0。
单词通常表示为基于它们与其他单词的关系的固定长度向量 – 具有相似含义的单词将具有相似的向量,反之亦然。我们可以将单词在句子中的位置表示为某个整数。它可以是分类(第一,中间,最后)或开放(句子中第一个单词的步数)
机器学习模型可以比基于规则的模型具有更高的召回率。但为了实现高精度,它们的功能需要非常精心设计和全面。
深度学习
经典的机器学习算法可以具有高精度并且相对容易实现。但它们的主要缺点确实阻碍了它们:它们需要特征工程。
设计特点,只是普通的硬盘。我们自然而然地理解自然语言,但我们仍然很难将其分解为具体步骤。我们无法想到理解语言的所有必要规则!
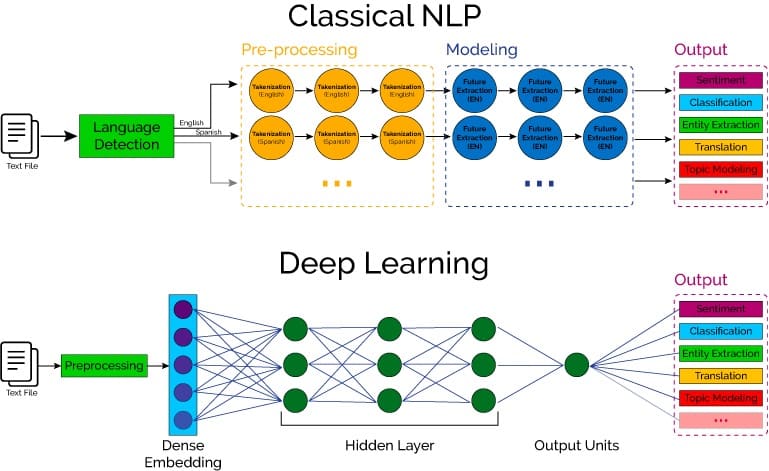
通过深入学习,我们不必进行任何复杂的功能工程。预处理仍然大致相同:将我们的文本转换为计算机可以理解的某种矢量表示,数字。
但是,深度学习不是使用工程特征来进行计算,而是让神经网络自己学习这些特征。在训练期间,输入是文本的特征向量,输出是一些高级语义信息,例如情感,分类或实体提取。在这一切的中间,曾经手工设计的功能现在由深度神经网络通过找到将输入转换为输出的某种方式来学习。
使用NLP的深度学习几乎总能获得更高的准确性。缺点是往往比基于规则和经典的机器学习方法慢得多。它们可能需要几秒钟才能运行,并且需要一些GPU计算。
掌握所有可用工具的知识总是有利的。如果您的准确度降低2-4%,那么请使用简单易用的基于规则的方法。如果你真的想要挤出最后一点精确度并有钱花钱,那就去重量级深度学习吧!
本文转自 medium,原文地址(需要科学上网)

Comments