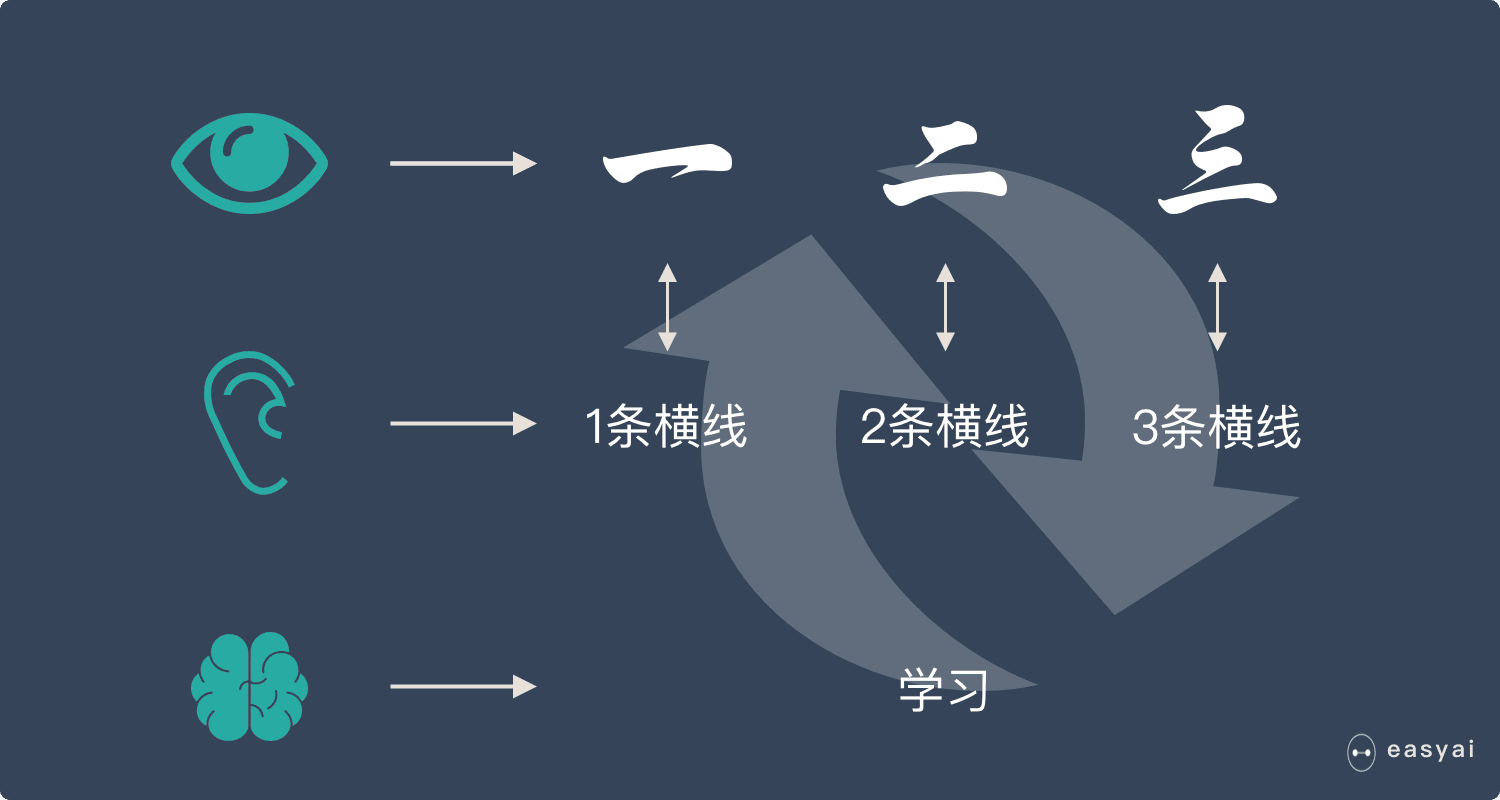
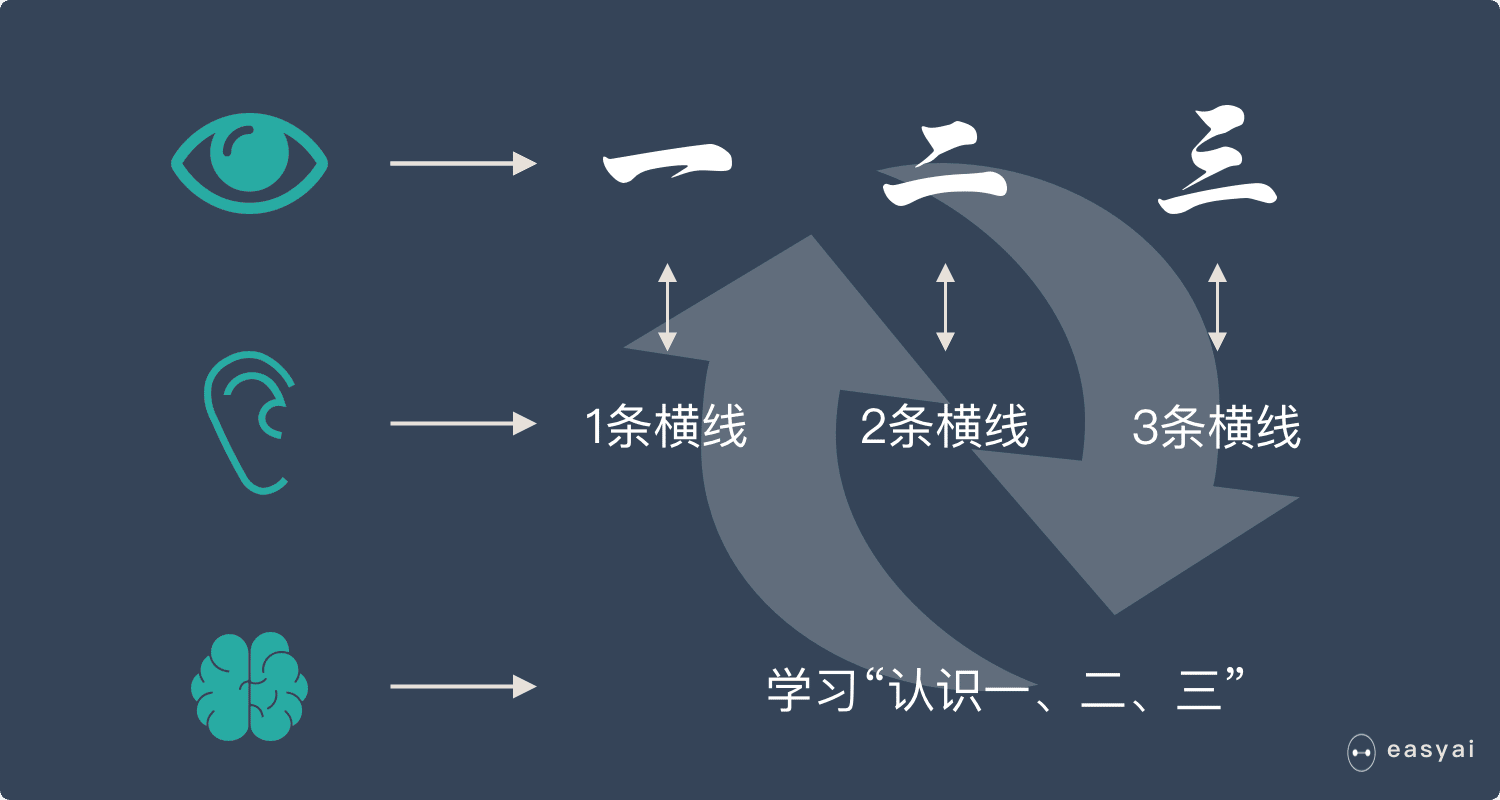
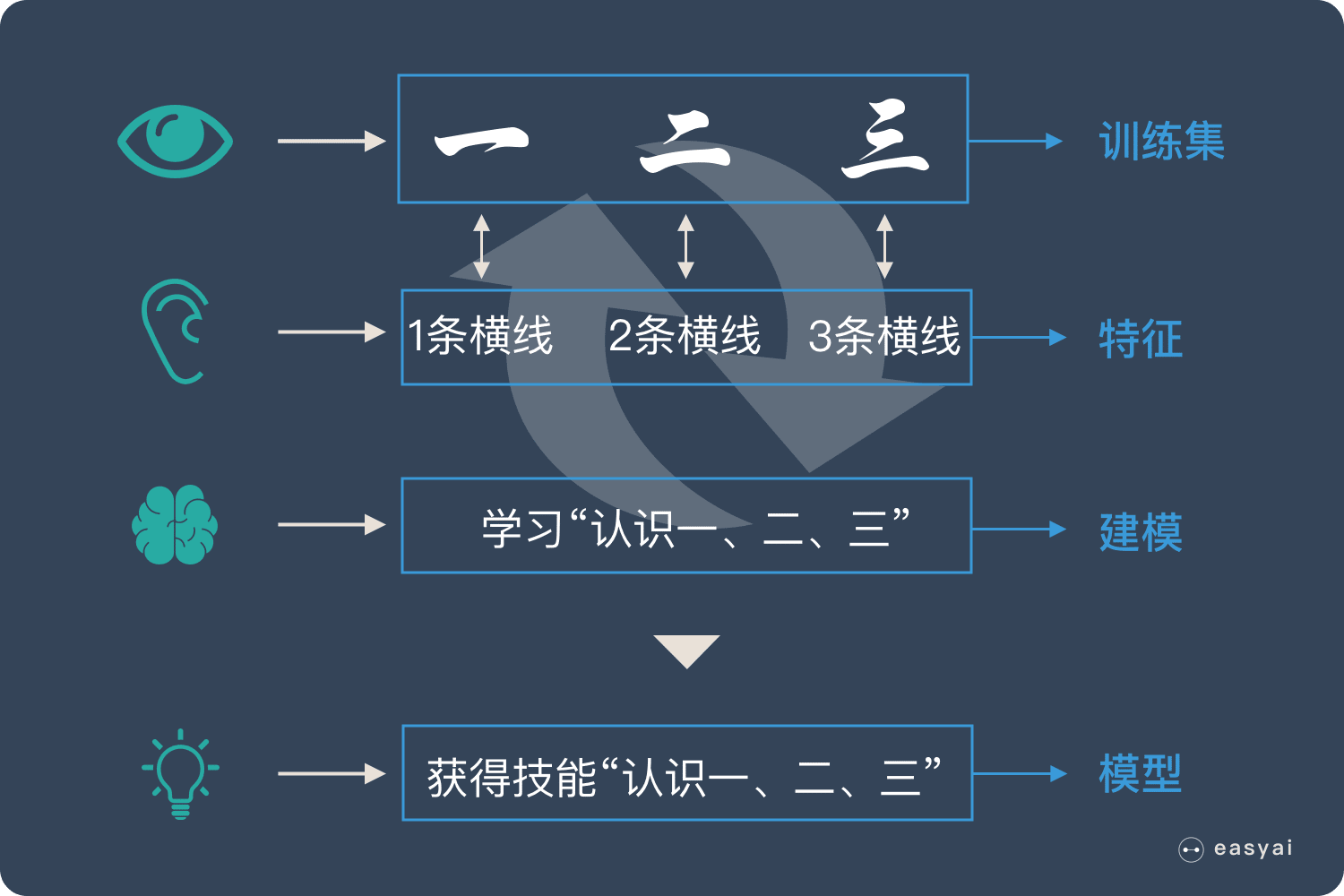
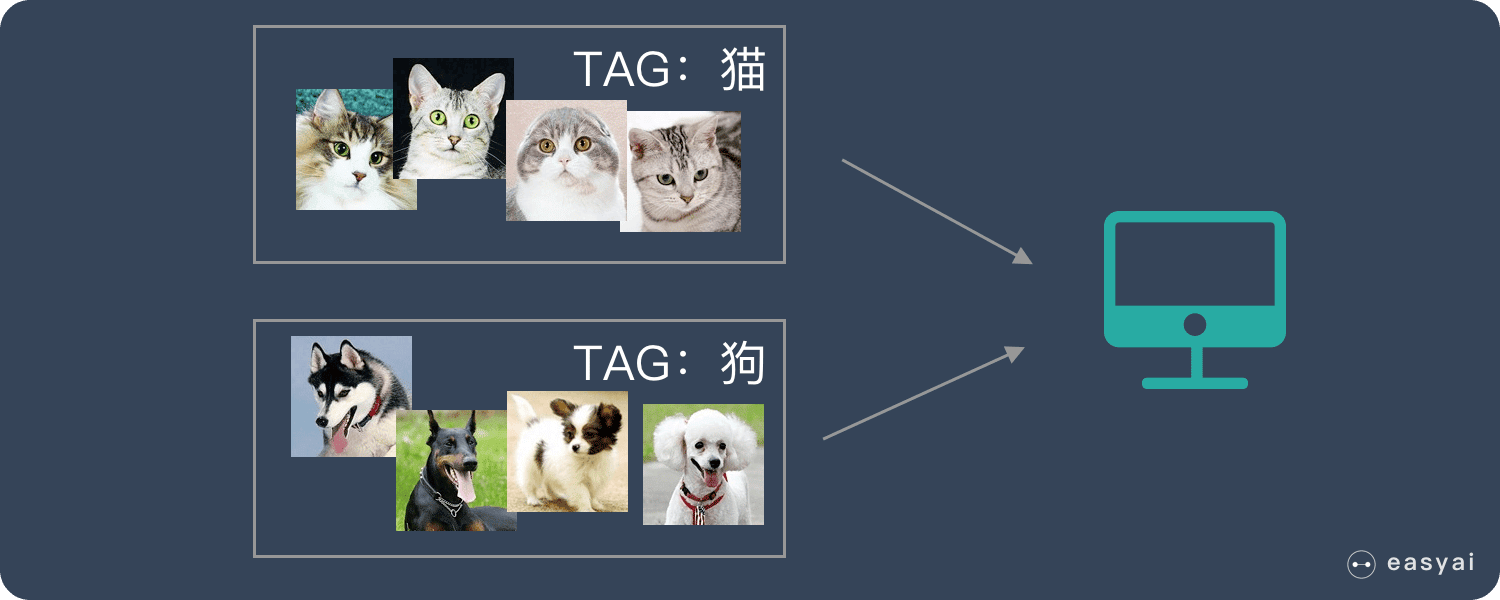
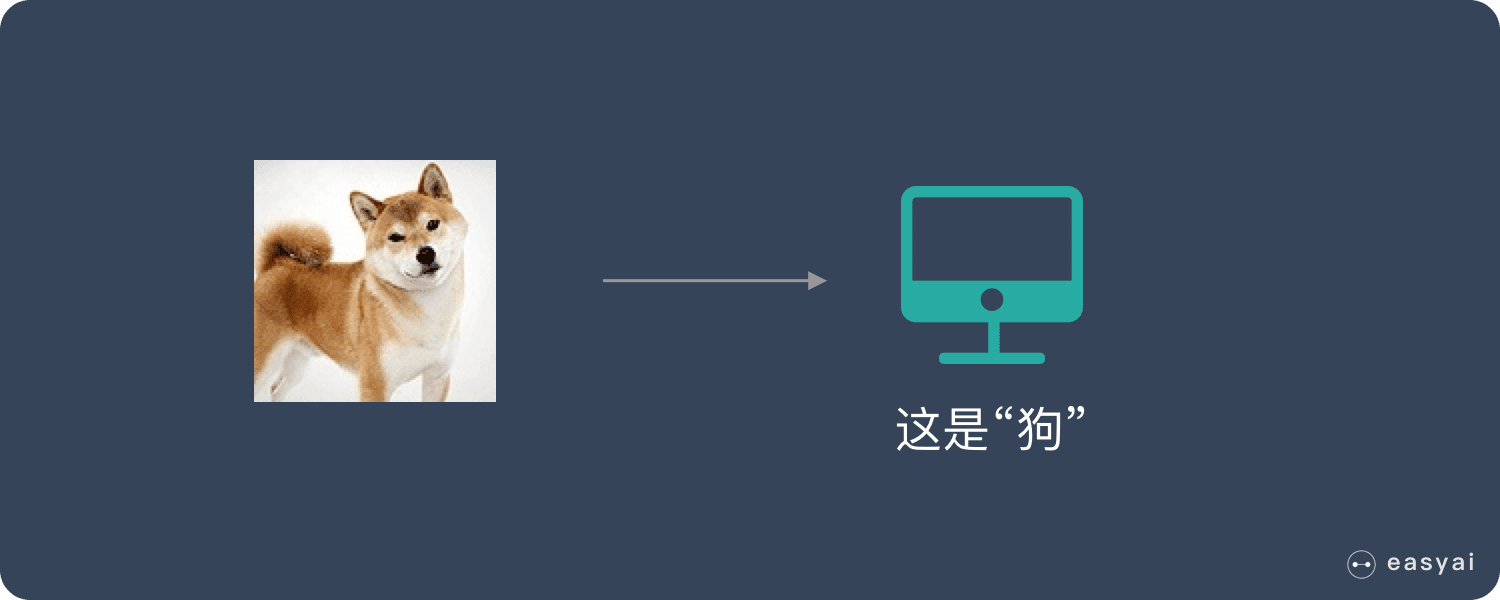
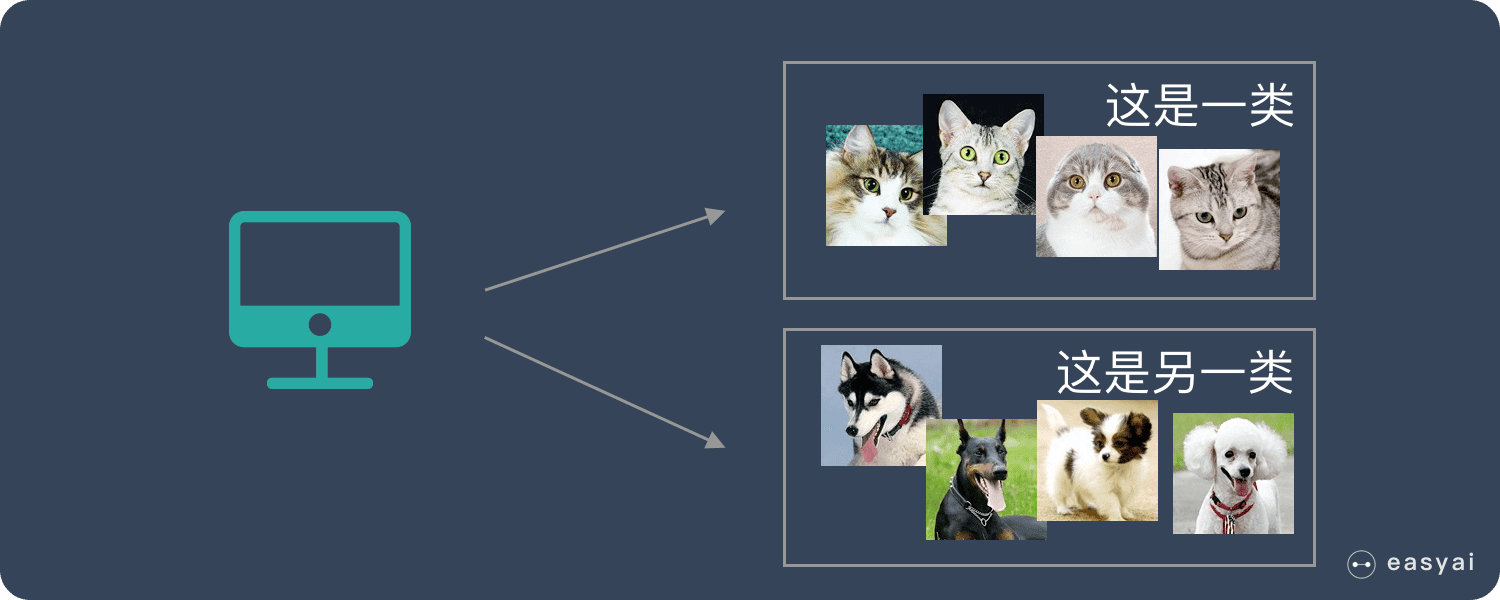
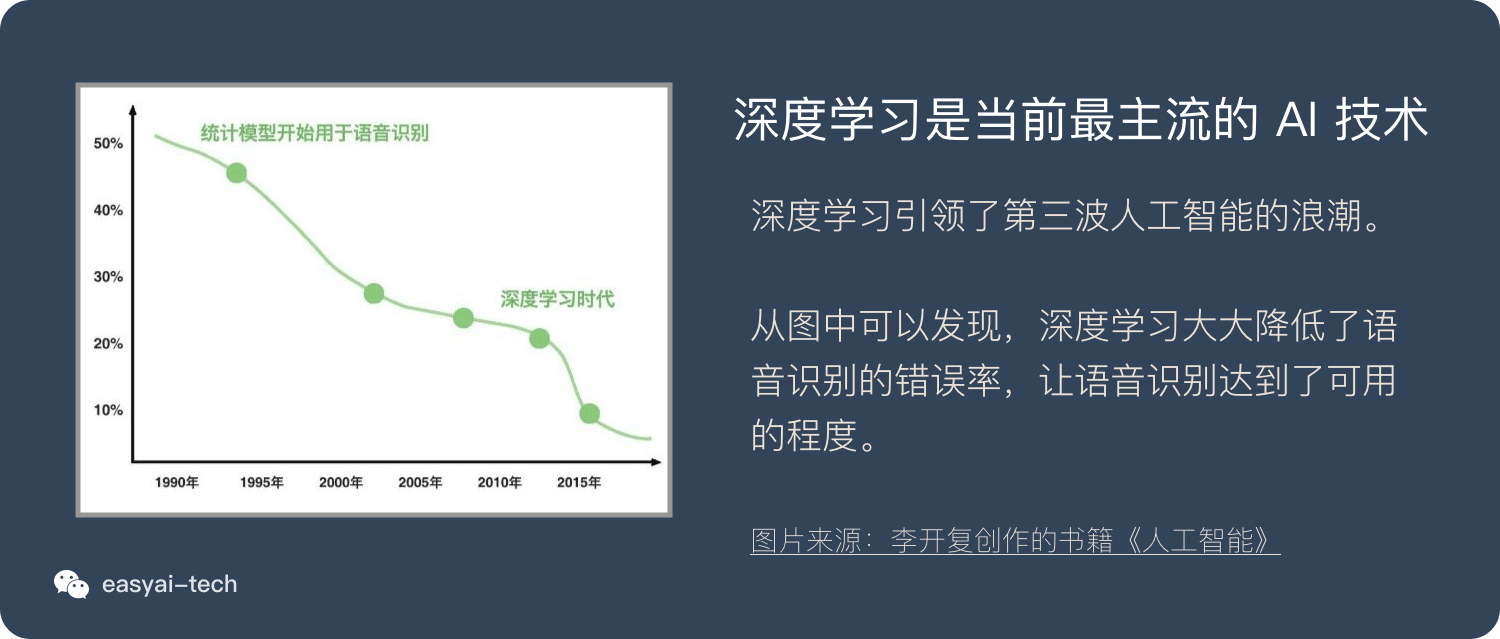
什么是 GPU?
CPU 能力更强大,能做很多事情,适合处理复杂的任务。GPU 结构简单,可以形成人海战术,适合处理重复简单的任务。
知乎上有一个回答很应景:
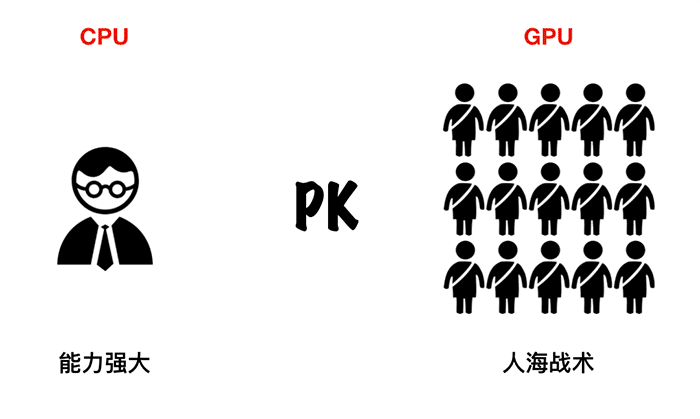
一个数学教授和100个小学生PK。
第一回合,四则运算,一百个题。教授拿到卷子一道道算。一百个小学生各拿一道题。教授刚开始算到第二题的时候,小学生集体交卷。第一回合小学生碾压教授。
第二回合,高等函数。一百个题。当教授搞定后。一百个小学生还不知道在干嘛…….第二回合,教授碾压一百个小学生。好理解吗?
这就是CPU和GPU的浅显比较。
百度百科版本
图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上图像运算工作的微处理器。
用途是将计算机系统所需要的显示信息进行转换驱动,并向显示器提供行扫描信号,控制显示器的正确显示,是连接显示器和个人电脑主板的重要元件,也是“人机对话”的重要设备之一。显卡作为电脑主机里的一个重要组成部分,承担输出显示图形的任务,对于从事专业图形设计的人来说显卡非常重要。
维基百科版本
图形处理单元(GPU)是一个专门的电子电路设计成迅速操纵和改变存储器加速的创建图像在一个帧缓冲器旨在用于输出到显示装置。GPU用于嵌入式系统,移动电话,个人计算机,工作站和游戏控制台。现代GPU在处理计算机图形和图像处理方面非常有效。它们高度并行的结构使它们比通用的更有效用于并行处理大块数据的算法的CPU。在个人计算机中,GPU可以存在于视频卡上或嵌入在主板上。在某些CPU中,它们嵌入在CPU 芯片上。
GPU至少在20世纪80年代一直被使用,它在1999年由Nvidia推广,他将GeForce 256作为“世界上第一个GPU” 推向市场。它被呈现为“具有集成变换,光照,三角形设置/剪切和渲染引擎的单芯片处理器”。竞争对手ATI Technologies在2002年发布了Radeon 9700,创造了“ 视觉处理单元 ”或VPU这一术语。